
範圍
 漢字
漢字基於歷史、國家疆域、政治等各種問題,中文信息處理系統所需要處理的文字,有時不僅包括簡體漢字、繁體漢字,也包括藏文、蒙文、壯文、維吾爾文等大量少數民族的文字,周邊國家的日本假名、諺文,還包括古漢語文字、西夏文、契丹文等各種不同的文字。
中文信息處理可以從硬體及軟體兩方面去看,以下詳述中文信息處理的發展歷史、現況及未來發展等多方面的面貌。
範疇
基礎研究:漢字字頻統計、詞頻統計、漢語自動分詞、句法屬性研究、漢字編碼字元集、通用漢字樣本庫、漢字屬性字典、語料庫等
輸入技術:中文輸入法、中文手寫輸入、中文語音輸入、文字識別等
輸出技術:漢字字模技術(字型庫)、漢字雷射照排、漢語語音合成等
存儲技術:漢字型檔標準等
轉換技術:繁簡轉換等
信息處理:中文情報檢索、中文文本校對、機器翻譯、自然語言理解、中文人機界面等
相關學科
語言文字學、計算機科學、模式識別、人工智慧、心理學、數學、數理統計、控制論、神經計算、模型論、信息學、形式化理論、聲學等
歷史
 朱邦復
朱邦復電腦在1946年由IBM發明,當時的電腦主要用於計算。及至1960年代,商用電腦開始普及,電腦被用於處理大規模的數據,當中其一個重要項目是圖書館的目錄整理。在當時,美國國會圖書館及多家大學都有不少來自東亞的藏書。為了有效管理這批藏書,必須要有一套有效處理東亞文字的系統。這套系統包括了兩方面:其一是如何把東亞文字儲存在電腦內;其二是如何在電腦表示出東亞文字。
在過去,每一台電腦都有各自的數據表達方式,使電腦之間不能溝通。及至1960年代美國信息交換標準碼(ASCII)的出現,電腦之間才可以互相溝通。不過,ASCII並不能有效處理英文以外的文字。
而IBM也斥資了六千萬、歷時十年, 研究電腦處理中文字的方法, 結論是電腦不能處理中文。而當時美國的圖書館開始電腦化,一批中文書有待編入目錄。
在台灣,中文電腦之父朱邦復在1976年發明了一套形意檢字法,到了1978年改進為倉頡輸入法, 1980年台灣開始了中文電腦,由宏碁公司出產。之後國喬、倚天、仲鼎等中文電腦系統相繼出現。
在大陸,在1974年8月開始了748工程, 包括了用計算機來處理中文字, 展開了各種研究工作, 後來到1980年公布了GB2312-80漢字編碼的國家標準,1983年中國科學院研究Unix中文化, 1985年推出了Unix中文版。
中文信息處理至今經歷了兩次高潮:1980年代中期到1990年代中期之前,核心內容是漢字的計算機處理問題;經過幾年的發展低潮之後,1990年代末,中文信息處理的重點轉向語音識別、語音合成和語義處理方面。
漢字之難——被打字機拋棄的時代:在二十世紀上半葉,英文打字機的普及極大的提高了文字資料的錄入速度。而由於漢字的複雜性,使中文打字機遲遲未能設計出來,再加之基礎漢字的學習難度大、時間長,連魯迅都喊出“漢字不滅,中國必亡”。之後,雖然設計出中文打字機,但要配備數千個鉛字組成的大字盤,昂貴的機器成本和複雜的使用技術決定它不能普及到大眾使用。毛澤東對此也深感無奈,發出了中文“要走世界共同的拼音文字道路”的慨嘆。這些局限於歷史條件所限而做出的言論,在中文信息處理技術發展後期仍然被經常(斷章取義的)提及。
1984年的《參考訊息》有這樣的記載:“法新社洛杉磯8月5日電 新華社派了22名記者,4名攝影記者和4名技術人員在奧運會採訪和工作。在全世界報導奧運會的7000名記者中,只有中國人用手寫他們的報導”……此時只有中國人仍然用手寫從事著創作。
漢字成了被打字機拋棄的“落後文明”,直到二十世紀八十年代PC技術推廣下,中文PC系統問世,中文信息輸入的問題,才有了初步解決。
漢字的拉丁化問題:漢字拉丁化,是給漢字進行注音的方法,從而易於中西方交流,或者代替漢字。有些人以為將漢字改造為字母文字,希望以此在短期內大幅增加中國人民的識字率。
緣起:中西方的交流很早就有了,而不同的文化交流需要語言的溝通,漢字拉丁化可以實現西方人對中國的了解。 近代以前,漢字的拉丁化基本由西方人進行。近代中國遭受了一系列的變故,徹底打破了中國固有的文化自豪感。中國近代的一些思想家認為中國古代的一些歷史遺留阻礙了中國的發展,包括孔子思想、禮教等,其中也包括漢字。
漢字由於其字數眾多,學習比較費勁,而且由於師承不同,字的具體寫法也有不同。近代科學大量引入中國,漢字在這些概念面前變得不夠使用,又由於新文化運動影響,漢字改革遂成為主流的社會思想。其中劉半農、魯迅等提倡尤甚。
過程:
 中文信息處理注音符號與拼音法
中文信息處理注音符號與拼音法1867年,在英國使館任中文秘書的威妥瑪(Thomas F. Wade)出版了一部《語言自邇集》,創立了一個拉丁化的威妥瑪拼音,使用時間很長,對漢字的拉丁化起了重要作用,以後的方案都有參考。
1918年中華民國教育部公布第一套法定的37個民族字母形式的注音字母方案,特點是採用符號表示聲調,這雖然不是一種直接的拉丁化方案,但用符號表示聲調的方法卻延續到漢語拼音方案。
1928年中華民國教育部公布第一套法定的拉丁化拼音方案-國語羅馬字(簡稱國羅),特點是用字母的拼法來表示漢語的聲調,實際上由於流傳時間較短,時間起到的作用不大。1958年,中華人民共和國公布的第二套法定的拉丁化漢語拼音方案,使用了26個拉丁字母,用符號表示聲調,但是這種符號不易在西式打字機上實現。1980年代,漢語的信息化進入日程,形成“萬碼奔騰”的局面,漢語拼音方案作為重要的拼音輸入方法得到使用,使漢語較能同信息化接軌。
漢字信息處理階段:
 中文信息處理
中文信息處理軟體:
輸入法:
企業:聯想、方正、四通等一批靠中文處理產品起家的企業。
標準、基礎研究:中文信息處理界基本上完成了詞頻統計、多種字型顯示/列印字型檔、漢字顯示/列印技術、輸入法、內碼標準、字元集標準等與字相關的所有基礎工作。倪院士說,到2000年,中國已制定了70個與中文信息處理相關的國家標準。
學術理論:1990年代中期,最為普及的計算機作業系統由DOS升級到Windows平台。微軟公司從中文版Windows 3.2開始,在作業系統里集成了漢字處理技術,使傳統中文信息處理產品迅速失去了市場。中文信息處理進入一個低谷,原先做中文信息處理的公司紛紛轉行。Windows2000及以上版本,無論採用何種文字,均已支持中文處理。
中文電腦、中文程式語言、中文軟體
網際網路時代的中文處理:
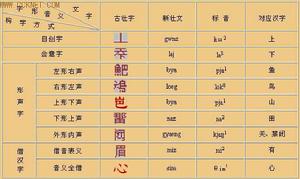 壯文
壯文漢語信息處理階段
數字圖書館:與此同時,為方便使國內各民族電腦化的步伐加快,政府作出一連串列動去使這些民族的語言更便於“計算機化”。這一連串列動包括以下各項:
取消民族語言中的特殊字元,儘可能以26個標準拉丁字母代替。(參看:壯語)
為還未有文字的民族設立以拉丁字母為本的新文字。
台灣方面,在1990年代曾引發“中文電腦化”及“電腦中文化”的爭議。
資策會方面的意見:認為電腦的操作空間有限。如果不讓中文適應電腦環境,中文就會失去新時代的活動能力而變成死的語言。
學界及業界的意見:操作空間有限的只是短時期的問題。隨著電腦發展日新月異,操作空間的限制很快就變得沒有意義。政府應該在新時代來臨以前,及早制定長遠的標準。
結果:資策會未能在ISO 10646開始討論中日韓文字編碼空間之前產生一個前瞻性的編碼方案,加上當時中國大陸政府的阻撓,使繁體字幾乎要在電腦世界消失。後來幸得多方面商討和配合,同意中日韓三國共享編碼空間,成為了今時今日的中日韓統一表意文字,而台灣的一萬三千多個字亦準以“民間通用標準”為理由成為了統漢碼的參考標準之一。電腦對漢字的親和性增加,而Unicode在統漢碼之後,亦不斷推出擴展A、擴展B及擴展C計畫,以涵蓋歷史上所有曾經出現過及使用過的漢字,並為它們編碼記錄。現時已整理好接近七萬個漢字。
中文電腦系統
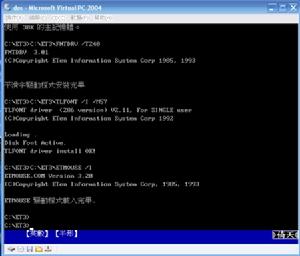 倚天中文系統
倚天中文系統運行在DOS上的中文系統
天匯漢字系統TW213
希望漢字系統UCDOS
倚天中文系統,它還有Windows版本,最後一個版本是倚天2000 for Windows
震漢中文系統,因與倚天高度相似而曾被倚天控告。
其他
這些都是1980年代出產的軟體,隨著Windows通行都逐一末落了。
編碼
編碼 (encoding): 用數字代替文字
中文內碼:例如Big5
中文交換碼:例如CCCII、CNS11643
字集: 要先選擇一定數量的字, 如常用字3500,或某本字典收錄的八千字
繁體字(主要是台灣及香港用):Big5,,一萬三千多字
簡化字(主要是中國大陸用):GB,六千多字
繁簡混合: GBK (由GB發展而來),二萬多字; Unicode2.0(可同時處理日文、韓文等文字),二萬多字。
輸出輸入
 五筆
五筆輸出字型
(印刷字型 font):細明體(不能使用, 因錯字多)、標楷體(符合台灣字型標準)、SimSun(簡宋, 符合大陸規範)字型技術
(在熒幕及印表機):點陣(bitmap)、向量(vector)、TrueType、OpenType等
輸入
鍵盤:
字形輸入:五筆字型、倉頡(及因倉頡而衍生的簡易等)、快碼、九方、縱橫等
字音輸入:漢語拼音、注音、港式拼音及其他方言拼音其他:混合字形及字音, 使用英文譯成中文外置輸入設備:
麥克風(語音輸入)、手寫板(手寫認字)、掃描器(字元識別 character recognition)
研究項目
目前已經開展的有以下10項:
①漢字信息處理:
這是一項最關鍵的語言工程,漢字如不能進入計算機,圖書情報工作自動化、印刷出版現代化 、辦公室事務自動化都將化為空談。 近10年來,漢字信息處理研究得到很大發展。曾設計了 400多種漢字編碼方案(見漢字編碼),其中上機通過試驗或已被採用作為輸入方式的,已達數十種之多。研製了上百種漢字信息處理系統和設備。這些系統主要採用兩種類型的鍵盤:一是筆觸式大鍵盤,另一是小鍵盤。前一種除整體輸入外,一般還有利用部件組合漢字的能力;後一種有的可兼容多種編碼方案,有的還帶有計算機引導的智慧型。
漢字信息處理除了在漢字編碼方面進行研究外,還製成了若干種漢字輸入輸出專用設備,其中有各種類型的漢字輸入鍵盤、漢字字型檔、漢字顯示終端、漢字圖形兼容終端、漢字印字機。成套的漢字信息處理系統(包括漢字編碼法、通用中外文鍵盤、通用中外文顯示器、漢字列印設備、漢字型檔和系統軟體等)已研製成功,並安排批量生產。一種最新式的編輯排版系統──計算機雷射漢字照排系統也已研製成功。中國的字模生產有良好的基礎,1985年 5月國家標準局公布了《信息交換用漢字15×16點陣字模集及數據集》和《信息交換用漢字24×24點陣字模集及數據集》兩項標準,為各種設備的設計和推廣提供了有利條件。
為了使人們擺脫繁重的編碼輸入工作,漢字的光電自動識別研究提上了日程。近年來有越來越多的單位從事手寫體和印刷體的識別研究。郵電部數據所和北京郵電學院提出了象限端點和轉動慣量特徵識別法,瀋陽自動化研究所提出了文字線長度識別法,上海公用事業研究所研製出數字條形識別系統,電子工業部第52研究所設計了提取漢字筆劃特徵的劃分映射法,清華大學研製了有限制性手寫體漢字識別系統。
為了使各種系統之間的信息交換有共同性,也為了使各種輸入輸出設備的設計有統一的根據,1981年國家標準局公布了《信息交換用漢字編碼字元集基本集》(簡稱《漢字標準交換碼》)。這個標準是根據漢字使用頻度制定的,共分兩級,一級3755個字,二級3008個字,共6763個字。為了滿足少數用字量超過基本集的用戶和台灣、香港等地的需要,正在制定《信息交換用漢字編碼字元集輔助集》,輔助集將根據使用頻度高低分作第一輔助集和第二輔助集,各收8000餘字。
②機器翻譯:
計算機和語言的最早結合開始於機器翻譯。1956年,機器翻譯被列入中國科學工作的發展規劃。1957年,機器翻譯研究工作正式開始進行。這可以說是中文信息處理的第一項工程。首先研究的是俄漢機器翻譯,並於1959年成功地進行了試驗,譯文輸出是代碼,而不是漢字,因為當時沒有漢字輸出裝置。1958年底至1960年初,又研製了一套英漢機器翻譯規則系統。1966~1975年工作處於停頓狀態。近年來,先後上機試驗了英漢、俄漢、法漢、日漢和漢外(英、法、德、俄、日)機器翻譯系統十餘個。有的輸出漢字譯文。有的輸出拼音譯文。
語言的對比研究是機器翻譯的語言學基礎。在外漢機器翻譯系統中調整詞序是一個中心任務。詞序的調整,首先必須分清層次和確定軸心。為了調整詞序,有的系統還建立了一套特殊的成分體系,即中介成分體系。介詞、連詞和標點是機器翻譯研究中的難點,對它們的正確分析是解決詞序調整問題的關鍵。當結構分析發生困難時,需要進行語義分析。
③中文情報檢索:
 辭海
辭海情報檢索系統中的關鍵問題是情報檢索語言的建立(見計算機情報檢索)。除一般的辭彙語法問題外,中文情報檢索系統中還有一個特殊問題,就是詞的切分,因為檢索是以詞(關鍵字)為基礎的。
④言語統計:中國利用電子計算機進行言語統計是機器翻譯工作者開始的。1978年語言研究所和計算技術研究所在合作研究 ECMT-78英漢機器翻譯系統的過程中曾編制一個排序統計程式,加工過一些外文資料和漢語拼音資料。1981年北京語言學院等單位開始對人工調查統計的辭彙進行計算機處理。1985年完成了《漢語辭彙的統計與分析》,在52萬多字的漢字語料中統計出18177個不同的詞, 這些詞出現的總和是374654次,出現最多的單音節詞是"的", 出現最多的雙音節詞是“我們”。1986年 6月又完成了《現代漢語頻率詞典》。1982年北京航空學院等單位開始更大規模的漢語統計工作,要在2000萬字的語料中進行字頻和詞頻統計。部分字頻統計結果已經得出,從1977~1982年的1200多萬字的語料中統計出8969個不同的漢字,並提供了這些漢字根據不同學科分類的26種使用頻度表。
由於詞的自動切分問題尚未解決,因而現在的詞頻統計都是在人工調查統計或人工分詞的基礎上進行的。另外,中國文字改革委員會和武漢大學利用計算機對《辭海》1.6 萬多個漢字的部件進行了統計分析,以研究漢字的結構特點。為了研究人名用字的使用情況,中國文字改革委員會和山西大學根據人口調查材料對人的姓名分別進行了統計。很多省份“王”為大姓,而福建省“陳”、“林”為大姓。
⑤漢語理解系統:
最近幾年,隨著人工智慧的進展,語言研究所、心理研究所、自動化研究所和一些大學開展了漢語理解系統(人機對話)的研究。目前只限於書面語言理解,而且主要是問答型的。輸入方式採用漢語拼音。上機試驗結果表明,有的系統已有識別30多種句型的能力(見漢語書面理解系統)。漢語語音理解系統的研製正在醞釀之中。
⑥計算機輔助語言教學:
近年來很多人關心這一課題。華東師範大學現代化教育技術研究所、哈爾濱工業大學、上海交通大學等單位已研製出語言教學軟體多種(見計算機輔助語言教學)。
⑦語音識別和言語合成:
語音打字的任務早在1958年便已提出。1964年實現了“元音識別機”,1970年前後又實現了10個口呼漢語數字的識別機。但利用電子計算機進行識別研究,則始於 1972年。 聲學研究所利用語音圖樣匹配方法在一定範圍內實現了單呼語言的識別,正確率達99.5%以上。哈爾濱工業大學利用音素分析法進行漢語識別,正確率達90%以上。
漢語合成的研究已在一些單位進行,一般尚處於研究實驗階段。清華大學自動化系最近試製成功一種會說話的中文計算機,機器里存有漢語聲韻母等語言數據,計算機會自動根據拼音規則實現拼接,合成語音。
⑧方言研究:
國外有人曾將漢語方言資料輸入計算機,讓計算機提供各個方言聲母、韻母、聲調的出現頻率,以及鼻化、齶化現象分布的百分比。這些數據不僅有利於方言的共時描寫和比較,而且還有利於檢驗各種歷史構擬假說的正確性。目前,中國已開始利用計算機進行方言研究和繪製方言地圖。
⑨索引、詞表和詞典的編制:
1980年武漢大學開始語言自動處理工作,主要是編制逐字索引,同時提供漢字統計數據。他們計畫編輯《現代漢語語言資料索引》23輯,收錄現代著名作家9人的作品共33部,總字數500多萬。前 5部作品(《駱駝祥子》、《倪煥之》、《雷雨》、《日出》和《北京人》)的逐字索引和統計資料已相繼印出。最近,他們又與山東省社會科學院合作,完成了《論衡》的語詞索引和統計資料。其他一些書籍的索引工作也在進行之中。
⑩修辭學研究:
武漢大學等單位利用現有的語料庫開始進行風格學研究,隨著語料的擴充和統計方法的改進,將會提供不同作家的風格特點和各種風格對比研究的成果。
利用計算機編制詞表、詞典也已提上日程。語言研究所正在編制《多語對照語言學辭彙(英、法、德、俄、中)》。機編詞典除能加快辭書的編輯出版過程外,還可以隨時擴充、修改,保持詞典的先進性。
中文信息處理研究方興未艾。隨著研究手段的改善和研究工作的深入,還將有更多更新的項目湧現。
外延
日文電腦,韓文電腦,其他文字的電腦系統加在其他作業系統或硬體上,如Linux, Macintosh, PPC, Palm, 手提電話等搜尋器 (search engine)語義網 (sementic web)電子書 (ebook)電子字典(軟體形式如金山詞霸或硬體形式如快譯通)電腦輔助翻譯 (Computer Aided Translation)軟體的國際化(internationalization)和本土化(globalization)其他
貢獻的人
 王安
王安