
言語合成
正文
用人工產生語音乃至整段語言的技術。合成語音的裝置叫做言語合成器或言語合成系統。早期的合成器是機械式的或電路式的,如今,言語合成已經計算機化了。言語合成技術不僅是深入研究語音特性的一種手段,而且也是實現人 -機語言通信的一種手段。在語音研究中,利用言語合成技術,可以靈活而精確地控制語音的特性參數,合成出各種各樣的語音樣本,通過對這些樣本的聽辨,逐步揭示出語音現象的機理。
言語合成與語音學 用合成技術來驗證語音的特性,是言語合成主要功能之一。它可以驗證哪些語音要素在傳輸中是必需的,哪些是多餘的。可以檢查語音中某一頻段在傳輸中的有效程度;可以通過試驗言語的“信噪比”來確定言語清晰度的最佳參量等等。語言學家在20世紀50年代晚期開始用合成來探索語音學上的問題,他們用加減參量、依存制約、轉換切分等方法,對元音音位區域、複合元音的主次特徵、輔音的發音方法和部位在辨音中的貢獻、聲調在辨義上的功能,以及一切韻律特徵等的研究,提供了極其方便而有效的手段。
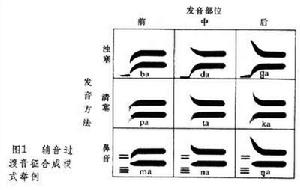
言語合成系統的類型及其發展 機械式的合成是比較早期的方法,用機械裝置模擬人的發音,用人工控制可以發出簡單音節。後來有人用電路方法模擬語音信號。聲譜分析發展後,大量出現根據言語聲譜來合成語音的裝置。電子計算機問世,一切複雜的機械或電路的合成系統都用計算機來代替,並在功能方面有了進展。言語合成約可分為 5個階段:①40年代以前,是用機械或電路模擬語音的時代。②50年代有了新的進展,言語聲譜分析已達到相當完備程度。輔音與元音之間的“過渡音征”畫成模式,通過模式還音器能產生很標準的輔音,至今還有參考價值(圖1)。③60年代, 計算機套用於語音合成系統,言語的"規則合成"成為最先進的合成自然語言的途徑。④70年代以來,在規則合成的基礎上,主要向合成的商品化發展,大量的多語言對譯器充斥市場,多限於有限辭彙和低質量的音質。⑤80年代以來,提高合成的音質以及“文-語合成”,盲人閱讀機等都有了相當成績。這種連續語言的合成要求,展開了第5代言語合成的序幕。未來的言語合成,將是除了更仿真地合成語音外,還要包括一切語法、語氣等特徵,為人-機對話系統奠定基礎。
 言語合成
言語合成計算機的言語合成系統大體有 3類:規則合成、單元編輯合成和錄音編輯合成。
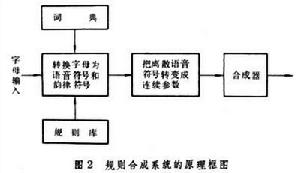
①規則合成系統(圖 2)紮根於語音產生的聲學理論。按此理論,任何一個語音都由聲源激勵、聲道共鳴和口鼻輻射這3個過程產生。語音不同,產生該語音的一套聲學參數也不同。這些參數有:控制音高的基頻(對濁音而言),控制音強的振幅,控制音長的時間,控制音色的頻譜包絡,共振峰頻率及頻寬,線性預測係數 (LPC),聲道截面函式或調音參數等。用這類參數按照一定的規則來控制具體的合成器,就能合成出預定的語音或語句。
 言語合成
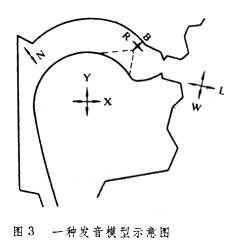
言語合成具體合成器有終端合成器和調音合成器等類型。終端合成器多以共振峰為控制參數(也稱共振峰合成器),用濾波器組來模擬語音的頻譜特徵,使得最終合成出的語音譜包絡逼近自然語音的譜包絡。調音合成器則是以發音模型為基礎,用幾個發音參量來描寫發音過程,這些參量通過規則轉換出聲道截面函式序列,進而控制合成器,合成出相應的語音。(圖3)是一種發音模型的示意圖,圖中L和W描寫唇的合、撮和開口度, R和B描寫舌尖的移動,X和Y描寫舌體活動,N描寫軟齶的升降。對語音研究來說,共振峰合成器和調音合成器都有實用價值。
 言語合成
言語合成③錄音編輯合成系統。事先把待輸出的語句、短語、單詞等進行錄音、壓縮和編碼,然後存入計算機。使用時,在既定的指令串控制下,計算機對存入的信息進行檢索、編輯和解碼,輸出話音。這種系統有如一種低數碼率的錄放機。
 言語合成
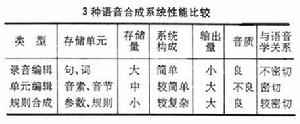
言語合成在單元編輯合成系統中,存入的是音節或音素,而一種語言的音節或音素數目總是有限的,例如漢語的音素只有30多個,以這些音素拼成的音節只有 400多個。顯然,這種方式能以較小的存儲量來滿足較大的辭彙量輸出的要求。例如,自然發出的“合成器”一詞有一秒的時長,在錄音編輯合成系統中,對此一秒的聲波要取 1萬個點(即採樣頻率10千赫),每一點的數位編成12位的代碼,那么,存儲量將是 120千位。但“合成器”一詞由 7個音素組成( 用漢語拼音注音為hé chéng qì),如果在某單元編輯合成系統中,為每一音素存10毫秒的波形 ,合成此詞時只需0.84千位。但是,實際的發音動作是連貫的,一個音節由幾個音素構成時,各音素間有許多變體,音節和音節之間呈現出錯綜複雜的協同發音等關係。所以,編輯拼接時要作大量語音學上的處理。目前,這類處理技術還不太完善,因此這種系統雖然能輸出的辭彙量比錄音編輯的多得多,存儲量又小得多,但合成的音質不如錄音編輯系統。
在規則合成系統中,存入的是描寫語音特性的各種參量而不是波形本身,所以所需存儲量比兩種編輯合成系統小得多,而它能輸出的辭彙量是很大的,甚至是無限的。不過,在規則合成系統中,處處依賴編定的規則,語音現象又那么複雜,各音素或音節之間又相互影響,以致要歸納出比較系統的和完善的規則是不容易的。
目前,國內外對上述 3種類型的語音合成系統都正在大力開發之中,有的系統已開始用於自動報時、天氣預報、自動報電話號碼、汽車自動報警、語音教學、導遊語詞翻譯、發音玩具等方面。有的系統和語音自動識別系統合為一種應答系統,用於車站、機場自動售票業務等。在一種盲人助讀系統中,輸入文字後,系統就能流利地朗讀起來。
見聲學語音學、言語識別。
參考書目
J.L.Flanagan,L.R.Rabiner(ed.),Speech Synthesis,Dowden,Hutchinson and Ross Inc.,Stroudsburg,1973.
