
 印有注音、倉頡和大易碼的繁體中文鍵盤
印有注音、倉頡和大易碼的繁體中文鍵盤歷史
 漢字
漢字Big5碼的產生,是因為當時台灣不同廠商各自推出不同的編碼,如IBM 5550、王安碼等,彼此不能兼容;另一方面,台灣當時尚未推出官方的漢字編碼,而中華人民共和國所推行的GB 2312編碼,亦未有收錄繁體字。在這樣的時空背景下,為了使台灣早日進入資訊時代,所採行的一個計畫;同時,這個計畫對於以台灣為核心的亞洲繁體漢字圈也產生了久遠的影響。
在Big5碼誕生後,大部分台灣的電腦軟體都使用了Big5碼,加上後來倚天中文系統的高度普及,使後來的微軟 Windows 3.x等亦予以採用。雖然後來台灣還有各種想要取代Big5碼,像是倚天中文系統所推行的倚天碼、中華民國中文電腦公會所推動的公會碼等,但是由於Big5字碼已沿用多年,因此在習慣不易改變的情況下,始終無法成為主流字碼。而台灣以後發展的國家標準中文交換碼(CNS 11643)由於先天所限,必須使用3位元組來表示一個漢字,與現行英語軟體欠缺兼容,所以普及率遠遠不及Big5碼。
現在,除了台灣外,其他使用繁體漢字的地區,如香港、澳門,還有海外華人,都普遍使用Big5碼。這已經成為繁體中文顯示的標準格式。
發展
 Unicode
Unicode寫之程式、Microsoft Windows 2000及之後版本、Microsoft Office 2000及之後版本、Mozilla瀏覽器、Internet Explorer瀏覽器、Java 語言等等),已改用Unicode編碼。可惜現時仍有一些舊的軟體(如Visual Basic 6、部分Telnet或BBS軟體),未能支援Unicode編碼,故相信Big5缺字的問題仍會困擾用戶一段時間,直至所有程式都能改用Unicode為止。
位元組結構
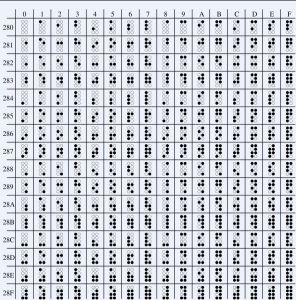
 大五碼
大五碼“高位位元組”使用了0x81-0xFE,“低位位元組”使用了0x40-0x7E,及0xA1-0xFE。在Big5的分區中:
值得留意的是,Big5重複地收錄了兩個相同的字:“兀、兀”(0xA461[U+5140]及0xC94A[U+FA0C])、“嗀、嗀”(0xDCD1[U+55C0]及0xDDFC[U+FA0D])。
 UNIX作業系統
UNIX作業系統在常用字如“功”(0xA55C)、“許”(0xB35C)、“蓋”(0xBB5C)、“育”(0xA87C)中時常出現,造成了許多軟體無法正確處理以Big5編碼的字串或檔案。這個問題被戲謔性地人名化,稱為“許功蓋”或“許蓋功”(這三個字都有這種問題)。
一般的解決方法,是額外增加“\”的字元,因為“\\”會被解釋為“\”,所以“成功\因素”這個字串就能無誤地被程式當作“成功因素”的字串來處理。但是額外的困擾是,有些輸出功能並不會把“\”當作特殊字元看待,所以有些程式或網頁就會錯誤地常常出現在“許功蓋”這些字後面多了“\”。
私人造字區:在倚天中文系統,以及後來的Windows3.1、95及98中,定義了四個私人造字區範圍:0xFA40-0xFEFE、0x8E40-0xA0FE、0x8140-0x8DFE、0xC6A1-0xC8FE。
私人造字區的原意,是供使用者加入本來在編碼表中缺少的字元,但當每個使用者都在不同的地方加上不同的字元後,當交換資料時,對方便難以知道某一個編碼究竟想表達什麼字。
影響
 中華民國總統府秘書長游錫堃
中華民國總統府秘書長游錫堃自中文電腦流行後,由於很多日常用字被視為異體字而未收錄。很多人,甚至電視台的字幕、報紙的用字習慣都被改變。
例如台灣教育部視“著”為“著”的異體字,故沒有收錄“著”字。康熙字典中的一些部首用字(如“亠”、“疒”、“辵”、“癶”等)、常見的人名用字(如“堃”(前中華民國前行政院長游錫堃)、“煊”(中華民國監察院院長、前財政部長王建煊)、“栢”(歌手張柏芝)、“喆”(歌手陶喆)等),雖被中文社會廣泛採用,也沒有收錄到Big5之中。
在網際網路上,實在不難看到人們把游錫堃、王建煊、陶喆等名字,寫成為“游錫方方土”、“王建火宣”和“陶吉吉”等寫法。電視上日本動畫的中文字幕中也會看到像“木堅”這樣的字。
Big5未收錄字舉例:
在倉頡中卻可打之
"邨"與"著"在香港里極為常用
| 未收錄的字 | 有收錄的字 | 原因 | 倉頡碼 |
|---|---|---|---|
| 綫 | 線 | 俗字 | 女火戈戈 |
| 綉 | 繡 | 俗字 | 女火竹木屍 |
| 邨 | 村 | 被認為是異體字 | 心山弓中(2) |
| 滙 | 匯 | 異體字 | 水屍人土 |
| 栢 | 柏 | 異體字 | 木一日 |
| 峯 | 峰 | 異體字 | 山竹水十(2) |
| 頴 | 穎 | 異體字 | 心火一月金(3) |
| 著 | 著 | 被認為是異體字 | 廿手月山 |
| 雙 | 雙 | 簡體字 | 水水(2) |
延伸
 倚天中文系統
倚天中文系統所以在市面上支援Big5碼的軟體,有不少都自行在原本的編碼外,添加一些符號及用字。
非官方Big5延伸
倚天Big5延伸:在倚天中文系統中,為與IBM5550碼相容,他們在Big5碼添加了以下的字元:
在0xA3C0-0xA3E0,添加了33個控制字元的圖象。
罕用符號區。在0xC6A1-0xC875,添加了圓形1-10、括弧1-10、小羅馬字i-ix等章節符號、一些部首及筆劃結構,日語平假名、片假名及俄語使用的西里爾字母。
在0xF9D6-0xF9FE,添加了7個倚天擴充字:碁、銹、恆、裏、墻、粧、嫺和34個表格符號。
這個延伸有時被稱為Big5-eten。由於倚天中文系統是Windows95推出之前市場占有率最高的中文系統,此延伸是各種非官方延伸當中最重要的一個。
在後期版本的倚天中文系統中,更加入了一些圖案和簡體中文字,但未被廣泛接受。
 微軟CP950編碼表
微軟CP950編碼表 在微軟Windows的CodePage950(簡稱CP950)之中,只添加了上述0xF9D6-0xF9FE的倚天擴充字及表格符號,並沒有加入日文假名字母等其他延伸,對不少使用MicrosoftWindows的用者帶來困擾。
在WindowsME之中,微軟首度在0xA3E1加入了歐元(€)符號,之後所有Windows版本的CodePage950也都有這個符號。
中國海字集:“中國海字集”是中國海有限公司(1990/09/17-2005/12/02)(已解散)的商業電腦字型產品。其特點是在加入大五碼以外的造字,加入一些常用但大五碼(BIG5)中沒有收進的字,標點及日文等5300多個,以彌補大五碼的不足。中國海字集本是中國海公司另一套產品輕鬆輸入法的衍生產品,以彌補大五碼字不夠無法輸入的缺憾,因此中國海字集通常附著“輕鬆輸入法”一同銷售,但中國海字型的也有單獨售賣或是包含在中國海的其它產品中。
DOS:中國海字集最初推出之時,是以“體驗版”的形式在台灣的BBS上供用戶下載其16×15字型作試驗。由於用戶反應十分好,所以後來委託棋峰資訊發行《中國海字集》一書,連同24×24字型及輕鬆輸入法體驗版發售。有關字型只適合當時最流行的中文系統,主要是倚天中文系統使用。
Windows:1994年,微軟公司推出繁體中文Windows3.1。由於這個版本開始採用TrueType字型技術,使字型比非Windows的點陣字型美觀得多。但是由於中國海公司的研發進度嚴重落後,因此這段期間中國海公司一直沒有新產品推出。當時外界有一套適用於Windows3.1的外字檔案,是熱心網友自行開發後上傳到網上,質量甚至比往後中國海推出的更好。
直至1997年,中國海推出Windows3.1版本的輕鬆輸入法及Windows95使用的輕鬆輸入法EZ2000,當中附帶著向TrueType版本的中國海字集。更在Office97中,附帶著輕鬆輸入法的體驗版,由於能夠顯示及輸入如日文及一些特別標點,因此大受歡迎,使得中國海進入最輝煌的時期。
可惜的是,在2000年的時候,Windows2000的推出,一方面Windows2000已經採用Unicode,要輸入像日文已經沒有Windows98,ME那么困難,另一方面中國海一直無法推出支援Windows2000的輕鬆輸入法。中國海公司曾經釋出了免費的中國海字集,供大眾使用,但為時已晚;當2001年推出支援Windows2000的輕鬆輸入法銷售並不理想後,中國海公司亦告結束。
日和字集:“日和字集”乃一香港人開發的造字檔,以兼容香港增補字元集為賣點,為字集中仍沒函蓋的日本漢字和日本國字作增補,並附有倉頡、速成等輸入法作輔助。
 Unicode補完計畫
Unicode補完計畫要留意的是“Unicode補完計畫”不等於Unicode。當你看見有人說“我安裝了Unicode”,通常是他把“Unicode補完計畫”和Unicode搞混了。
“Unicode補完計畫”也不是用來解決軟體顯示亂碼的問題。電腦內要有相關的字形(例如支援整個Unicode漢字的字形),才能在電腦顯示器看到。因為“Unicode補完計畫”只包含了編碼轉換表,並不包括字形在內。而一些日語遊戲裝在WindowsXP所出現的亂碼問題,應使用MicrosoftAppLocale內碼轉換器等程式去作內部轉換。
歷史:
2001年9月:Unicode計畫1.0版發表。支援日文假名。
2001年10月:Unicode計畫2.0版發表。支援第一水平漢字單向對應。
2002年4月:中文化聯盟發表Big5Extension擴充規格。一口氣支援大量漢字。
2002年5月:Big5Extension擴充規格與Unicode計畫同意整合。
2002年6月:有鑒於Big5Extension易與中推會的Big5E名稱混淆,正式決定統一以Unicode計畫作為名稱,由中文化聯盟發布。
2006年2月:FireFox2採用Unicode補完計畫做為BIG5單向轉換到UNICODE的字碼表,因此FireFox2/3可顯示BIG5碼日文假名。而同時期的IE6/7至今仍無法顯示BIG5碼日文假名。
 中華民國教育部
中華民國教育部台灣農委會常用中文外字集:中華民國行政院農業委員會制定了一套有133個漢字的造字檔,其中有84個是魚字部漢字、7個是鳥字部漢字。
Big5+:中文數位化技術推廣委員會(中推會)在1997年推出Big5+,使用了兩萬多碼位,納入了Unicode1.1下所有漢字。由於編碼使用到的範圍超過原先Big5定義(Big5+使用了高位元組0x81-0xFE,低位元組0x40-0x7E、0x80-0xFE),無法安裝在MicrosoftWindows上,現幾乎無人使用。
Big-5E:為了使MicrosoftWindows使用者可以使用造字檔,中華民國行政院委託中推會再次推出一個補充字集Big-5E(與Big5+並不兼容),共收3954字。它把Big5+不少漢字都去掉,更甚者放棄了倚天延伸字集的假名部分。於是,除了部分被強制使用的政府單位外,沒有多少人願意使用Big5E。
Big5-2003:鑒於Big5不是一個官方標準,中推會決定編制一個Big5的定義,並把它放到官方編碼CNS11643的附錄里,正式成為官方標準的一部分。
在Big5-2003之中,收錄了所有在1984年Big5編碼的所有字元,另外再加入微軟CP950的歐元符號、倚天延伸字集的0xA3C0-0xA3E0、0xC6A1-0xC7F2、0xF9D6-0xF9FE的用字。Big5-2003沒有收錄行列輸入法特殊符號及0xC7F3-0xC875的俄語西里爾字母,理由是以CNS11643沒有這些字元。除此之外,所有倚天延伸全部收錄。
相對於Big5-2003,最早沒有加上任何延伸的Big5則被稱為Big5-1984。
 香港增補字元集
香港增補字元集字元集所收羅的字,主要包括香港的地名、人名用漢字、粵語漢字及異體字,也有小部份簡體字。除此之外,此字元集亦把倚天中文系統收錄的日語平假名、片假名及俄語字母包括在內。此字元集由中文界面諮詢委員會管理,仍在不斷擴編之中。最新版本為2005年5月推出的HKSCS-2004,收錄4,941個字元。
字元分類:在HKSCS-2004版本,漢字字元共4500個,其中3353字可在大型的字典(如《漢語大字典》)中查到,包括簡化字、異體字、日語漢字等。其餘在各大中文字典中查不到的字中,有粵語方言字(有些可在方言字典及學術著作中查到)、人名、公司名、地方名、變形部首、附形、訛字。有些字來自入境事務處、公司註冊處、稅務局、地政總署。
各類符號共441個,有漢字筆形、漢語拼音字母、國際音標符號、漢字元件、畫表符號、日本平假名、片假名等。
香港增補字元集在2005年才有畫數、部首、粵音等資料給用戶參考,還說明方便檢索,而非作為規範標準。(漢字的部首在不同的字典中,歸部也不盡相同)
 國喬中文系統
國喬中文系統早期的倚天中文系統、國喬中文系統等對造字缺乏管理,而又沒有文字專家的審定,因此當時造字很是混亂,有些甚至可能只是臨時使用的“錯字”(尋遍各大字典、專書也查不到的字,也作幽靈漢字);製作這些中文系統的廠商又對字形、字型缺乏認識,有些字會因為字型不同而字形稍有差別,分別編進了兩個碼位中。又有同一字有系統區及造字區兩個碼位,有些聯綿詞只收其一不收其二;這個問題帶到了政府通用字型檔和香港增補字元集中,字集因要反向兼容而跳過了一些碼位。
Big-5原來的編碼,只有漢字、標點、注音符號等字元及少數圖形,後來經過台灣廠商的增收,多了7個“倚天字”(即碁、銹、裏、墻、恆、粧、嫺)及日文的假名,最後這批字元又被香港增補字元集收入。
香港增補字元集所使用的Big-5的外字區分幾個區段:
“造字區一”(FA40—FEFE):早期的GCCS字元集已經填滿這一段。
“造字區二”(C6A1—C8FE):倚天用了這段來放日文假名等符號。這些符號在HKSCS1999年的版本被收納。
“造字區三”(8140—A0FE):香港增補字元集把這段開頭的(8140—84FE)保留給用戶,新增的字元只用其餘的碼位。“廠商造字區”(F9D6—F9FE):這段開始的七個碼位用來存放裏、恆等“倚天字”,之後的碼位被微軟的繁體中文Windows用來存放制表符號。後來HKSCS1999年版本將之全部收納。
可是一般提及HKSCS的檔案,包括來自香港政府的,都沒有註明HKSCS以外的一般繁體字編碼(即是Big-5本身)使用哪個版本。Big-5在2003年前就只有一個版本,不會造成混淆,但HKSCS-2004的檔案仍沒有指定Big-5部份是2003年之後還是之前的版本,雖然到目前為止並沒有任何系統使用Big5-2003。
相關詞條
輸入法大全
| 輸入法大全及其理論,發明者等。 |
