
疊代算法
疊代是數值分析中通過從一個初始估計出發尋找一系列近似解來解決問題(一般是解方程或者方程組)的過程,為實現這一過程所使用的方法統稱為疊代法(Iterative Method)。
一般可以做如下定義:對於給定的線性方程組x=Bx+f(這裡的x、B、f同為矩陣,任意線性方程組都可以變換成此形式),用公式x(k+1)=Bx(k)+f(括弧中為上標,代表疊代k次得到的x,初始時k=0)逐步帶入求近似解的方法稱為疊代法(或稱一階定常疊代法)。如果k趨向無窮大時limx(k)存在,記為x*,稱此疊代法收斂。顯然x*就是此方程組的解,否則稱為疊代法發散。
跟疊代法相對應的是直接法(或者稱為一次解法),即一次性的快速解決問題,例如通過開方解決方程x +3= 4。一般如果可能,直接解法總是優先考慮的。但當遇到複雜問題時,特別是在未知量很多,方程為非線性時,我們無法找到直接解法(例如五次以及更高次的代數方程沒有解析解,參見阿貝耳定理),這時候或許可以通過疊代法尋求方程(組)的近似解。
最常見的疊代法是牛頓法。其他還包括最速下降法、共軛疊代法、變尺度疊代法、最小二乘法、線性規劃、非線性規劃、單純型法、懲罰函式法、斜率投影法、遺傳算法、模擬退火等等。
 疊代法
疊代法利用疊代算法解決問題,需要做好以下三個方面的工作:
確定疊代變數
在可以用疊代算法解決的問題中,至少存在一個直接或間接地不斷由舊值遞推出新值的變數,這個變數就是疊代變數。
建立疊代關係式
所謂疊代關係式,指如何從變數的前一個值推出其下一個值的公式(或關係)。疊代關係式的建立是解決疊代問題的關鍵,通常可以順推或倒推的方法來完成。
對疊代過程進行控制
在什麼時候結束疊代過程?這是編寫疊代程式必須考慮的問題。不能讓疊代過程無休止地重複執行下去。疊代過程的控制通常可分為兩種情況:一種是所需的疊代次數是個確定的值,可以計算出來;另一種是所需的疊代次數無法確定。對於前一種情況,可以構建一個固定次數的循環來實現對疊代過程的控制;對於後一種情況,需要進一步分析出用來結束疊代過程的條件。
舉例說明
例 1 :一個飼養場引進一隻剛出生的新品種兔子,這種兔子從出生的下一個月開始,每月新生一隻兔子,新生的兔子也如此繁殖。如果所有的兔子都不死去,問到第 12 個月時,該飼養場共有兔子多少只?
分析:這是一個典型的遞推問題。我們不妨假設第 1 個月時兔子的只數為 u 1 ,第 2 個月時兔子的只數為 u 2 ,第 3 個月時兔子的只數為 u 3 ,……根據題意,“這種兔子從出生的下一個月開始,每月新生一隻兔子”,則有
u 1 = 1 , u 2 = u 1 + u 1 × 1 = 2 , u 3 = u 2 + u 2 × 1 = 4 ,……
根據這個規律,可以歸納出下面的遞推公式:
u n = u(n - 1)× 2 (n ≥ 2)
對應 u n 和 u(n - 1),定義兩個疊代變數 y 和 x ,可將上面的遞推公式轉換成如下疊代關係:
y=x*2
x=y
讓計算機對這個疊代關係重複執行 11 次,就可以算出第 12 個月時的兔子數。參考程式如下:
cls
x=1
for i=2 to 12
y=x*2
x=y
next i
print y
end
例 2 :阿米巴用簡單分裂的方式繁殖,它每分裂一次要用 3 分鐘。將若干個阿米巴放在一個盛滿營養參液的容器內, 45 分鐘後容器內充滿了阿米巴。已知容器最多可以裝阿米巴 220,220個。試問,開始的時候往容器內放了多少個阿米巴?請編程式算出。
分析:根據題意,阿米巴每 3 分鐘分裂一次,那么從開始的時候將阿米巴放入容器裡面,到 45 分鐘後充滿容器,需要分裂 45/3=15 次。而“容器最多可以裝阿米巴2^ 20 個”,即阿米巴分裂 15 次以後得到的個數是 2^20。題目要求我們計算分裂之前的阿米巴數,不妨使用倒推的方法,從第 15 次分裂之後的 2^20 個,倒推出第 15 次分裂之前(即第 14 次分裂之後)的個數,再進一步倒推出第 13 次分裂之後、第 12 次分裂之後、……第 1 次分裂之前的個數。
設第 1 次分裂之前的個數為 x 0 、第 1 次分裂之後的個數為 x 1 、第 2 次分裂之後的個數為 x 2 、……第 15 次分裂之後的個數為 x 15 ,則有
x 14 =x 15 /2 、 x 13 =x 14 /2 、…… x n-1 =x n /2 (n ≥ 1)
因為第 15 次分裂之後的個數 x 15 是已知的,如果定義疊代變數為 x ,則可以將上面的倒推公式轉換成如下的疊代公式:
x=x/2 (x 的初值為第 15 次分裂之後的個數 2^20)
讓這個疊代公式重複執行 15 次,就可以倒推出第 1 次分裂之前的阿米巴個數。因為所需的疊代次數是個確定的值,我們可以使用一個固定次數的循環來實現對疊代過程的控制。參考程式如下:
cls
x=2^20
for i=1 to 15
x=x/2
next i
print x
end
ps:java中冪的算法是Math.pow(2,20);返回double,稍微注意一下
例 3 :驗證谷角猜想。日本數學家谷角靜夫在研究自然數時發現了一個奇怪現象:對於任意一個自然數 n ,若 n 為偶數,則將其除以 2 ;若 n 為奇數,則將其乘以 3 ,然後再加 1。如此經過有限次運算後,總可以得到自然數 1。人們把谷角靜夫的這一發現叫做“谷角猜想”。
要求:編寫一個程式,由鍵盤輸入一個自然數 n ,把 n 經過有限次運算後,最終變成自然數 1 的全過程列印出來。
分析:定義疊代變數為 n ,按照谷角猜想的內容,可以得到兩種情況下的疊代關係式:當 n 為偶數時, n=n/2 ;當 n 為奇數時, n=n*3+1。用 QBASIC 語言把它描述出來就是:
if n 為偶數 then
n=n/2
else
n=n*3+1
end if
這就是需要計算機重複執行的疊代過程。這個疊代過程需要重複執行多少次,才能使疊代變數 n 最終變成自然數 1 ,這是我們無法計算出來的。因此,還需進一步確定用來結束疊代過程的條件。仔細分析題目要求,不難看出,對任意給定的一個自然數 n ,只要經過有限次運算後,能夠得到自然數 1 ,就已經完成了驗證工作。因此,用來結束疊代過程的條件可以定義為:n=1。參考程式如下:
cls
input "Please input n=";n
do until n=1
if n mod 2=0 then
rem 如果 n 為偶數,則調用疊代公式 n=n/2
n=n/2
print "—";n;
else
n=n*3+1
print "—";n;
end if
loop
end
疊代法開平方:
#include
#include
void main()
{
double a,x0,x1;
printf("Input a:\n");
scanf("%lf",&a);//為什麼在VC6.0中不能寫成“scanf("%f",&a);”?
if(a<0)
printf("Error!\n");
else
{
x0=a/2;
x1=(x0+a/x0)/2;
do
{
x0=x1;
x1=(x0+a/x0)/2;
}while(fabs(x0-x1)>=1e-6);
}
printf("Result:\n");
printf("sqrt(%g)=%g\n",a,x1);
}
求平方根的疊代公式:x1=1/2*(x0+a/x0)。
算法:1.先自定一個初值x0,作為a的平方根值,在我們的程式中取a/2作為a的初值;利用疊代公式求出一個x1。此值與真正的a的平方根值相比,誤差很大。
⒉把新求得的x1代入x0中,準備用此新的x0再去求出一個新的x1.
⒊利用疊代公式再求出一個新的x1的值,也就是用新的x0又求出一個新的平方根值x1,此值將更趨近於真正的平方根值。
⒋比較前後兩次求得的平方根值x0和x1,如果它們的差值小於我們指定的值,即達到我們要求的精度,則認為x1就是a的平方根值,去執行步驟5;否則執行步驟2,即循環進行疊代。
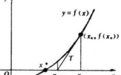
疊代法是用於求方程或方程組近似根的一種常用的算法設計方法。設方程為f(x)=0,用某種數學方法導出等價的形式x=g(x),然後按以下步驟執行:
⑴ 選一個方程的近似根,賦給變數x0;
⑵ 將x0的值保存於變數x1,然後計算g(x1),並將結果存於變數x0;
⑶ 當x0與x1的差的絕對值還小於指定的精度要求時,重複步驟⑵的計算。
若方程有根,並且用上述方法計算出來的近似根序列收斂,則按上述方法求得的x0就認為是方程的根。上述算法用C程式的形式表示為:
【算法】疊代法求方程的根
{ x0=初始近似根;
do {
x1=x0;
x0=g(x1); /*按特定的方程計算新的近似根*/
} while (fabs(x0-x1)>Epsilon);
printf(“方程的近似根是%f\n”,x0);
}
疊代算法也常用於求方程組的根,令
X=(x0,x1,…,xn-1)
設方程組為:
xi=gi(X) (I=0,1,…,n-1)
則求方程組根的疊代算法可描述如下:
【算法】疊代法求方程組的根
{ for (i=0;i
x=初始近似根;
do {
for (i=0;i
y=x;
for (i=0;i
x=gi(X);
for (delta=0.0,i=0;i
if (fabs(y-x)>delta) delta=fabs(y-x);
} while (delta>Epsilon);
for (i=0;i
printf(“變數x[%d]的近似根是 %f”,I,x);
printf(“\n”);
}
具體使用疊代法求根時應注意以下兩種可能發生的情況:
⑴ 如果方程無解,算法求出的近似根序列就不會收斂,疊代過程會變成死循環,因此在使用疊代算法前應先考察方程是否有解,並在程式中對疊代的次數給予限制;
⑵ 方程雖然有解,但疊代公式選擇不當,或疊代的初始近似根選擇不合理,也會導致疊代失敗。
遞歸
遞歸是設計和描述算法的一種有力的工具,由於它在複雜算法的描述中被經常採用,為此在進一步介紹其他算法設計方法之前先討論它。
能採用遞歸描述的算法通常有這樣的特徵:為求解規模為N的問題,設法將它分解成規模較小的問題,然後從這些小問題的解方便地構造出大問題的解,並且這些規模較小的問題也能採用同樣的分解和綜合方法,分解成規模更小的問題,並從這些更小問題的解構造出規模較大問題的解。特別地,當規模N=1時,能直接得解。
【問題】 編寫計算斐波那契(Fibonacci)數列的第n項函式fib(n)。
斐波那契數列為:0、1、1、2、3、……,即:
fib(0)=0;
fib⑴=1;
fib(n)=fib(n-1)+fib(n-2) (當n>1時)。
寫成遞歸函式有:
int fib(int n)
{ if (n==0) return 0;
if (n==1) return 1;
if (n>1) return fib(n-1)+fib(n-2);
}
遞歸算法的執行過程分遞推和回歸兩個階段。在遞推階段,把較複雜的問題(規模為n)的求解推到比原問題簡單一些的問題(規模小於n)的求解。例如上例中,求解fib(n),把它推到求解fib(n-1)和fib(n-2)。也就是說,為計算fib(n),必須先計算fib(n-1)和fib(n- 2),而計算fib(n-1)和fib(n-2),又必須先計算fib(n-3)和fib(n-4)。依次類推,直至計算fib⑴和fib(0),分別能立即得到結果1和0。在遞推階段,必須要有終止遞歸的情況。例如在函式fib中,當n為1和0的情況。
在回歸階段,當獲得最簡單情況的解後,逐級返回,依次得到稍複雜問題的解,例如得到fib⑴和fib(0)後,返回得到fib⑵的結果,……,在得到了fib(n-1)和fib(n-2)的結果後,返回得到fib(n)的結果。
在編寫遞歸函式時要注意,函式中的局部變數和參數知識局限於當前調用層,當遞推進入“簡單問題”層時,原來層次上的參數和局部變數便被隱蔽起來。在一系列“簡單問題”層,它們各有自己的參數和局部變數。
由於遞歸引起一系列的函式調用,並且可能會有一系列的重複計算,遞歸算法的執行效率相對較低。當某個遞歸算法能較方便地轉換成遞推算法時,通常按遞推算法編寫程式。例如上例計算斐波那契數列的第n項的函式fib(n)應採用遞推算法,即從斐波那契數列的前兩項出發,逐次由前兩項計算出下一項,直至計算出要求的第n項。
【問題】 組合問題
問題描述:找出從自然數1、2、……、n中任取r個數的所有組合。例如n=5,r=3的所有組合為:⑴5、4、3 ⑵5、4、2 ⑶5、4、1
⑷5、3、2 ⑸5、3、1 ⑹5、2、1
⑺4、3、2 ⑻4、3、1 ⑼4、2、1
⑽3、2、1
分析所列的10個組合,可以採用這樣的遞歸思想來考慮求組合函式的算法。設函式為void comb(int m,int k)為找出從自然數1、2、……、m中任取k個數的所有組合。當組合的第一個數字選定時,其後的數字是從餘下的m-1個數中取k-1數的組合。這就將求m 個數中取k個數的組合問題轉化成求m-1個數中取k-1個數的組合問題。設函式引入工作數組a[ ]存放求出的組合的數字,約定函式將確定的k個數字組合的第一個數字放在a[k]中,當一個組合求出後,才將a[ ]中的一個組合輸出。第一個數可以是m、m-1、……、k,函式將確定組合的第一個數字放入數組後,有兩種可能的選擇,因還未去頂組合的其餘元素,繼續遞歸去確定;或因已確定了組合的全部元素,輸出這個組合。細節見以下程式中的函式comb。
【程式】
# include
# define MAXN 100
int a[MAXN];
void comb(int m,int k)
{ int i,j;
for (i=m;i>=k;i--)
{ a[k]=i;
if (k>1)
comb(i-1,k-1);
else
{ for (j=a;j>0;j--)
printf(“%4d”,a[j]);
printf(“\n”);
}
}
}
void main()
{ a=3;
comb(5,3);
}
【問題】 背包問題
問題描述:有不同價值、不同重量的物品n件,求從這n件物品中選取一部分物品的選擇方案,使選中物品的總重量不超過指定的限制重量,但選中物品的價值之和最大。
設n 件物品的重量分別為w0、w1、…、wn-1,物品的價值分別為v0、v1、…、vn-1。採用遞歸尋找物品的選擇方案。設前面已有了多種選擇的方案,並保留了其中總價值最大的方案於數組option[ ],該方案的總價值存於變數maxv。當前正在考察新方案,其物品選擇情況保存於數組cop[ ]。假定當前方案已考慮了前i-1件物品,現在要考慮第i件物品;當前方案已包含的物品的重量之和為tw;至此,若其餘物品都選擇是可能的話,本方案能達到的總價值的期望值為tv。算法引入tv是當一旦當前方案的總價值的期望值也小於前面方案的總價值maxv時,繼續考察當前方案變成無意義的工作,應終止當前方案,立即去考察下一個方案。因為當方案的總價值不比maxv大時,該方案不會被再考察,這同時保證函式後找到的方案一定會比前面的方案更好。
對於第i件物品的選擇考慮有兩種可能:
⑴ 考慮物品i被選擇,這種可能性僅當包含它不會超過方案總重量限制時才是可行的。選中後,繼續遞歸去考慮其餘物品的選擇。
⑵ 考慮物品i不被選擇,這種可能性僅當不包含物品i也有可能會找到價值更大的方案的情況。
按以上思想寫出遞歸算法如下:
try(物品i,當前選擇已達到的重量和,本方案可能達到的總價值tv)
{ /*考慮物品i包含在當前方案中的可能性*/
if(包含物品i是可以接受的)
{ 將物品i包含在當前方案中;
if (i
try(i+1,tw+物品i的重量,tv);
else
/*又一個完整方案,因為它比前面的方案好,以它作為最佳方案*/
以當前方案作為臨時最佳方案保存;
恢復物品i不包含狀態;
}
/*考慮物品i不包含在當前方案中的可能性*/
if (不包含物品i僅是可男考慮的)
if (i
try(i+1,tw,tv-物品i的價值);
else
/*又一個完整方案,因它比前面的方案好,以它作為最佳方案*/
以當前方案作為臨時最佳方案保存;
}
為了理解上述算法,特舉以下實例。設有4件物品,它們的重量和價值見表:
物品 0 1 2 3
重量 5 3 2 1
價值 4 4 3 1
並設限制重量為7。則按以上算法,下圖表示找解過程。由圖知,一旦找到一個解,算法就進一步找更好的佳。如能判定某個查找分支不會找到更好的解,算法不會在該分支繼續查找,而是立即終止該分支,並去考察下一個分支。
按上述算法編寫函式和程式如下:
【程式】
# include
# define N 100
double limitW,totV,maxV;
int option[N],cop[N];
struct { double weight;
double value;
}a[N];
int n;
void find(int i,double tw,double tv)
{ int k;
/*考慮物品i包含在當前方案中的可能性*/
if (tw+a.weight<=limitW)
{ cop=1;
if (i
else
{ for (k=0;k
option[k]=cop[k];
maxv=tv;
}
cop=0;
}
/*考慮物品i不包含在當前方案中的可能性*/
if (tv-a.value>maxV)
if (i
else
{ for (k=0;k
option[k]=cop[k];
maxv=tv-a.value;
}
}
void main()
{ int k;
double w,v;
printf(“輸入物品種數\n”);
scanf((“%d”,&n);
printf(“輸入各物品的重量和價值\n”);
for (totv=0.0,k=0;k
{ scanf(“%1f%1f”,&w,&v);
a[k].weight=w;
a[k].value=v;
totV+=V;
}
printf(“輸入限制重量\n”);
scanf(“%1f”,&limitV);
maxv=0.0;
for (k=0;k find(0,0.0,totV);
for (k=0;k
if (option[k]) printf(“%4d”,k+1);
printf(“\n總價值為%.2f\n”,maxv);
}
作為對比,下面以同樣的解題思想,考慮非遞歸的程式解。為了提高找解速度,程式不是簡單地逐一生成所有候選解,而是從每個物品對候選解的影響來形成值得進一步考慮的候選解,一個候選解是通過依次考察每個物品形成的。對物品i的考察有這樣幾種情況:當該物品被包含在候選解中依舊滿足解的總重量的限制,該物品被包含在候選解中是應該繼續考慮的;反之,該物品不應該包括在當前正在形成的候選解中。同樣地,僅當物品不被包括在候選解中,還是有可能找到比目前臨時最佳解更好的候選解時,才去考慮該物品不被包括在候選解中;反之,該物品不包括在當前候選解中的方案也不應繼續考慮。對於任一值得繼續考慮的方案,程式就去進一步考慮下一個物品。
【程式】
# include
# define N 100
double limitW;
int cop[N];
struct ele { double weight;
double value;
} a[N];
int k,n;
struct { int ;
double tw;
double tv;
}twv[N];
void next(int i,double tw,double tv)
{ twv.=1;
twv tw=tw;
twv tv=tv;
}
double find(struct ele *a,int n)
{ int i,k,f;
double maxv,tw,tv,totv;
maxv=0;
for (totv=0.0,k=0;k
totv+=a[k].value;
next(0,0.0,totv);
i=0;
While (i>=0)
{ f=twv.;
tw=twv tw;
tv=twv tv;
switch(f)
{ case 1: twv.++;
if (tw+a.weight<=limitW)
if (i
{ next(i+1,tw+a.weight,tv);
i++;
}
else
{ maxv=tv;
for (k=0;k
cop[k]=twv[k].!=0;
}
break;
case 0: i--;
break;
default: twv.=0;
if (tv-a.value>maxv)
if (i
{ next(i+1,tw,tv-a.value);
i++;
}
else
{ maxv=tv-a.value;
for (k=0;k
cop[k]=twv[k].!=0;
}
break;
}
}
return maxv;
}
void main()
{ double maxv;
printf(“輸入物品種數\n”);
scanf((“%d”,&n);
printf(“輸入限制重量\n”);
scanf(“%1f”,&limitW);
printf(“輸入各物品的重量和價值\n”);
for (k=0;k
scanf(“%1f%1f”,&a[k].weight,&a[k].value);
maxv=find(a,n);
printf(“\n選中的物品為\n”);
for (k=0;k
if (option[k]) printf(“%4d”,k+1);
printf(“\n總價值為%.2f\n”,maxv);
}
遞歸特點
程式調用自身的編程技巧稱為遞歸(recursion)。
一個過程或函式在其定義或說明中又直接或間接調用自身的一種方法,它通常把一個大型複雜的問題層層轉化為一個與原問題相似的規模較小的問題來求解,遞歸策略只需少量的程式就可描述出解題過程所需要的多次重複計算,大大地減少了程式的代碼量。遞歸的能力在於用有限的語句來定義對象的無限集合。用遞歸思想寫出的程式往往十分簡潔易懂。
一般來說,遞歸需要有邊界條件、遞歸前進段和遞歸返回段。當邊界條件不滿足時,遞歸前進;當邊界條件滿足時,遞歸返回。
注意:
⑴ 遞歸就是在過程或函數裡調用自身;
⑵ 在使用遞增歸策略時,必須有一個明確的遞歸結束條件,稱為遞歸出口。
