
定義
對於國內的滿二叉樹
從圖形形態上看,滿二叉樹外觀上是一個三角形。
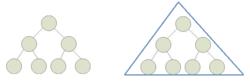 圖一
圖一從數學上看,滿二叉樹的各個層的結點數形成一個首項為1,公比為2的等比數列。
因此由等比數列的公式,滿二叉樹滿足如下性質。
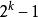 滿二叉樹
滿二叉樹1、一個層數為k 的滿二叉樹總結點數為:。因此滿二叉樹
 滿二叉樹
滿二叉樹的結點數一定是奇數個。
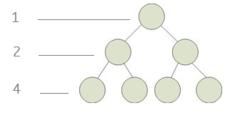
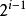 滿二叉樹
滿二叉樹2、第i層上的結點數為:
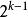 滿二叉樹
滿二叉樹3、一個層數為k的滿二叉樹的葉子結點個數(也就是最後一層):
對於國外的滿二叉樹
滿二叉樹的結點要么是葉子結點,度為0,要么是度為2的結點,不存在度為1的結點。
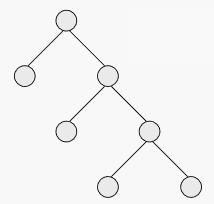 圖三
圖三因此,右圖中這個二叉樹也是滿二叉樹。但是按照國內的定義,它卻不是滿二叉樹。
美國以及國際上所定義的滿二叉樹,即full binary tree,和國內的定義不同,美國NIST給出的定義為:A binary tree in which each node has exactly zero or two children. In other words, every node is either a leaf or has two children. For efficiency, any Huffman coding is a full binary tree.
滿二叉樹的任意節點,要么度為0,要么度為2.換個說法即要么為葉子結點,要么同時具有左右孩子。霍夫曼樹是符合這種定義的,滿足國際上定義的滿二叉樹,但是不滿足國內的定義。
基於滿二叉樹的原地快速排序
一種基於滿二叉樹的原地快速排序算法。 與經典快速排序算法相比, 新算法每趟劃分採用動態樞軸而不是靜態樞軸, 同時新算法利用滿二叉樹的特點計算下一趟劃分的樞軸位置和元素範圍, 避免使用遞歸或開闢記憶體堆疊。 實驗表明, 新算法的時間性能優於最好的原地排序—堆排序。 原地快速排序二叉樹的概念對排序算法的研究和改進具有很好的理論和實用參考價值。
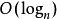 滿二叉樹
滿二叉樹給定一個長度為m的順序表 ,每個元素由一個關鍵字和其他的相關信息構成 , 排序算法的任務就是根據關鍵字以非降序(或非升序)重新安排數組中的元素(不失一般性, 以下我們按非降序排序)。排序算法僅允許做關鍵字比較和元素移動操作, 並用關鍵字比較次數和元素移動次數 ,衡量排序算法的時間性能和空間性能 。如果一個算法所使用的額外空間是一個固定常數 ,與處理問題的規模無關 ,則我們稱該算法是原地的。快速排序算法是最好的排序算法之一, 它的基本思想是通過若干次劃分得到有序表。一次劃分後樞軸左邊元素的關鍵字都不大於樞軸的關鍵字, 樞軸右邊元素的關鍵字都不小於樞軸的關鍵字 。然後對樞軸左邊和右邊的元素繼續劃分 ,直到每個部分都只有1個元素為止。經典快速排序或用遞歸函式實現或自己開闢記憶體堆疊實現,需要的額外空間, 都不是嚴格意義上的原地算法 。在本文中 ,將滿二叉樹的概念引入快速排序中, 利用滿二叉樹的特點計算下一趟劃分的樞軸位置和元素範圍 ,避免了使用遞歸或開闢記憶體堆疊 ,從而將快速排序改造成嚴格原地的。實驗表明, 該算法的時間性能優於最好的原地排序 —堆排序。
基於滿二叉樹二分K-means聚類並行推薦算法
在推薦系統中套用K-means算法聚類可有效降維,然而聚類效果往往依賴於選定的初始中心,並且一旦選定目標簇後,推薦過程只針對目標簇進行,與其他簇無關。針對上述兩個問題,提出一種基於滿二叉樹的二分K-means聚類並行推薦算法。該算法首先反覆疊代二分K-means算法,疊代過程中使用簇內凝聚度作為分裂閾值,形成一顆滿二叉樹;然後通過層次遍歷將用戶歸入到K個葉子節點(簇);最後針對K個簇,套用MapReduce框架進行並行推薦預測。MovieLens上的實驗結果表明,該算法可大幅度提高推薦系統準確性,同時增強系統可擴展性。
基於滿二叉樹的RA碼交織器設計
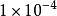 滿二叉樹
滿二叉樹為提高輸入信息較長時重複累積碼的編碼效率,對重複累積碼的交織器進行最佳化改進。按照滿二叉樹子節點的奇偶排列方式對交織器的輸入序列依次分組,並利用葉子節點對分組信息重新組合獲得輸出序列,與S隨機交織器相比,大大降低輸入信息之間的相關性,避免了RA碼校驗矩陣中I、II類4環的產生,保證了解碼的準確性。仿真結果表明,在輸入信息序列較長時,改進的交織器編碼速度快且誤碼率遠低於行列規則交織器;與S隨機交織器相比,改進的交織器可以顯著提高編碼速率,且在誤碼率同為時約有0.3dB的增益。
