
含義
曲線擬合
用連續曲線近似地刻畫或比擬平面上離散點組所表示的坐標之間的函式關係。更廣泛地說,空間或高維空間中的相應問題亦屬此範疇。在數值分析中,曲線擬合就是用解析表達式逼近離散數據,即離散數據的公式化。實踐中,離散點組或數據往往是各種物理問題和統計問題有關量的多次觀測值或實驗值,它們是零散的,不僅不便於處理,而且通常不能確切和充分地體現出其固有的規律。這種缺陷正可由適當的解析表達式來彌補。
稱為在 xk處擬合的殘差或剩餘,衡量擬合優度的標準通常有
式中 ωk>0為權係數或權重(如無特別指定,一般取為平均權重,即( k=1,2,…,m),此時無需提到權)。當參數 b)使 T( b))或 Q( b))達到最小時,相應的(2)分別稱為在加權切比雪夫意義或加權最小二乘意義下對 (1)的擬合,後者在計算上較簡便且最為常用。
模型中參數的確定
一般的線性模型是以參數 b)為係數的廣義多項式,即 (3)式中 g0, g1,…, gn稱為基函式。對諸 g j的不同選取可構成多種典型的和常用的線性模型。從函式逼近的觀點來看,式(3)還能近似地體現許多非線性模型的性質。
在最小二乘意義下用線性模型(3)擬合離散點組(1),參數 b可通過解方程組( i=0,…, n)來確定,即解關於 b0, b1,…, bn的線性代數方程組 (4)式中 ( i, j=0,1,…, n),
方程組(4)通常稱為法方程或正規方程,當m> n時一般有惟一解。
至於非線性模型以及非最小二乘原則的情形,參數 b)可通過解非線性方程組或最最佳化計算中的有關方法來確定(見非線性方程組數值解法、最最佳化)。
模型的選擇
對於給定的離散數據(1),需恰當地選取一般模型(2)中函式 ?( x, b))的類別和具體形式,這是擬合效果的基礎。若已知(1)的實際背景規律,即因變數 y對自變數 x的依賴關係已有表達式形式確定的經驗公式,則直接取相應的經驗公式為擬合模型。反之,可通過對模型(3)中基函式 g0, g1,…, gn(個數和種類)的不同選取,分別進行相應的擬合併擇其效果佳者。函式 g0, g1,…, gn對模型的適應性起著測試的作用,故又稱為測試函式。另一種途徑是:在模型(3)中納入個數和種類足夠多的測試函式,藉助於數理統計方法中的相關性分析和顯著性檢驗,對所包含的測試函式逐個或依次進行篩選以建立較適合的模型(見回歸分析)。當然,上述方法還可對擬合的殘差(視為新的離散數據)再次進行,以彌補初次擬合的不足。總之,當數據中變數之間的內在聯繫不明確時,為選擇到相適應的模型,一般需要反覆地進行擬合試驗和分析鑑別。
定義
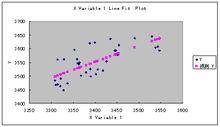 線性擬合
線性擬合已知某函式的若干 離散函式值{f1,f2,…,fn},通過調整該 函式中若干待定係數f(λ1, λ2,…,λm), 使得該函式與已知點集的差別(最小二乘意義)最小。如果待定函式是線性,就叫 線性擬合或者 線性回歸(主要在統計中)。
套用
線性擬合作為數學計算中一種常用的數學方法,在建築、物理、化學、甚至於天體物理、航天中都得到基本的套用。一般情況下,線性擬合需要根據實際需要,取用不同的擬合度,即R2。
區別
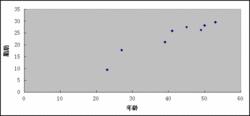 線性擬合散點圖
線性擬合散點圖兩個變數之間的關係是一次函式關係的——圖象是直線,這樣的兩個變數之間的關係就是“線性關係”;如果不是一次函式關係的——圖象不是直線,就是“非線性關係”。
