
基本內容
為了得到一致假設而使假設變得過度複雜稱為過擬合。想像某種學習算法產生了一個過擬合的分類器,這個分類器能夠百分之百的正確分類樣本數據(即再拿樣本中的文檔來給它,它絕對不會分錯),但也就為了能夠對樣本完全正確的分類,使得它的構造如此精細複雜,規則如此嚴格,以至於任何與樣本數據稍有不同的文檔它全都認為不屬於這個類別。
標準定義:給定一個假設空間H,一個假設h屬於H,如果存在其他的假設h’屬於H,使得在訓練樣例上h的錯誤率比h’小,但在整個實例分布上h’比h的錯誤率小,那么就說假設h過度擬合訓練數據。 ----《Machine Learning》Tom M.Mitchell
例:如圖所示
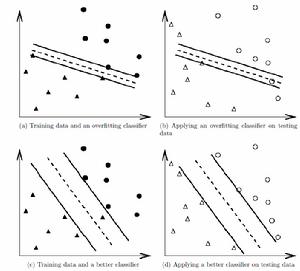 a,b過擬合 c,d不過擬合
a,b過擬合 c,d不過擬合可以看出在a中雖然完全的擬合了樣本數據,但對於b中的測試數據分類準確度很差。而c雖然沒有完全擬合樣本數據,但在d中對於測試數據的分類準確度卻很高。過擬合問題往往是由於測試數據少等原因造成的。
