
簡介
 技術接受模型表-2
技術接受模型表-2發展
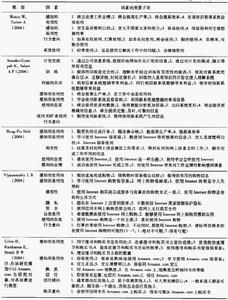 技術接受模型表-1
技術接受模型表-1目前,越來越多的組織意識到組織競爭力依賴於對智力資源的有效管理,使得知識管理迅速成為一個非常重要的組織職能[2]。知識管理包括大範圍的複雜的組織、社會和行為的因素,儘管如此,信息技術仍是目前研究知識管理的一個主要因素。基於知識管理是由信息有關的技術所支撐,採用技術接受模型對知識管理系統的接受進行研究。該模型主要測度技術接受模型兩個主要因素——感知的有用性、易用性與用戶使用知識管理系統的意向,以及實際使用之間的關係。
該研究模型同Davis最初的技術接受模型相比較,沒有考慮想用的態度這個因素,是因為Davis在1989年發現想用的態度在感知的有用性對使用的行為意向的影響方面只起部分調解作用,由於在該研究模型中沒有涉及到影響感知的有用性、感知的易用性的因素,所以外部變數也沒有包括在該研究模型中。
2、ERP套用系統接受模型的結構
企業資源計畫是一個能夠處理包括財政、人力資源、製造、物質管理、銷售和分配在內的多種功能的系統。實施ERP需要大量的組織資源並存在由大量投資所帶來的風險,相比傳統的簡單的信息技術系統的實施是一個完全不相同的信息技術套用範疇。
在該研究模型中,著重研究影響技術接受模型中兩個主要的因素——感知有用性和感知易用性的因素。模型包括了技術接受模型主要的因素同時定義了三個外部變數:ERP系統的計畫交流,對ERP系統所產生利益的共識,ERP系統的訓練。在組織中,最先可能接受ERP系統的是高級管理工作者,ERP系統的計畫交流使得關於ERP系統的信息從高級管理人員流向其他的人員,對ERP系統能產生利益的共識是指同行以及管理人員之間對ERP系統價值所達成的共識,ERP系統的訓練包括內部訓練和外部訓練,是指對用戶的一系列培訓。
3、lnternet套用接受模型的結構
近年來,越來越多的企業使用Internet,特別是在共享重要的信息資源時[9]。開發基於Internet的系統以及建立企業內部的網際網路有助於打破供應者與需求者之間時間和距離的障礙以減少成本提高生產率.企業使用Intenlet主要用來收集信息,但怎樣取得企業所期望的信息是企業使用Internet的一個主要障礙[10]。收集與任務有關的信息已成為使用Internet的一個主要方面,更為重要的是信息處理的性能也越來越取決於信息與組織任務的匹配程度。
在該研究模型中,使用技術接受模型對個人的工作業績進行評估。對日常工作中Internet使用的評估主要依據個人對使用與任務有關的網站和Intranet的印象。為了實證研究工作人員對與任務有關的Internet的使用,綜合運用了技術接受模型和Choo[11]的信息行為模型,信息行為模型主要說明人們怎樣通過信息的需求—搜尋—使用循環來降低任務的不確定性。以信息行為模型的三步循環為基礎,從三方面對工作中Internet的使用進行評估研究。在信息需求方面,主要就相關的信息能否解決問題的個人判斷進行模擬研究,提出因素—相關性[12];在信息搜尋階段,使用兩個技術因素——感知的有用性、易用性和一個個人因素——想用的態度對個人的評估進行研究;在信息使用階段,用感知的業績進行研究,對用戶來說,相比具體的使用Internet,評估制定的決策所帶來的結果和使用Internet能解決的實際問題更為重要一些。
4、Online Shopping接受模型的結構
近幾年來,大量網上零售商的破產使得人們對商家一消費者(B2C)網上銷售模式的過度樂觀的期望有所降低.目前,B2C電子商務還處於發展初期,傳統銷售渠道仍具有明顯的優勢,儘管如此,B2C電子商務作為一種銷售媒介並沒有消失。
Amazon,eBay,Travelocity這幾個電子商務網站持久穩定的發展顯示出電子商務零售商有能力克服時間和空間上的障礙為消費者提供更好的服務——大量的產品信息,專家建議,定製化服務,快速的訂單過程,電子產品的快速交付等等。但同時也存在著很多挑戰,尤其是在網站界面設計、訂單填寫、付款方式,以及消費者個人信息的保護上。
採用技術接受模型對Online Shopping接受進行研究,但由於消費者在選擇零售商時,享有更多的自主權,所以還必須考慮除了感知的有用性和易用性這兩個因素之外其他因素的影響,包括兼容性、隱私、安全、規範的信念和自我效用。
5、基於無經驗和有經驗消費者的Online Stores接受模型的結構
吸引新的消費者並留住已有的消費者是電子商務成功的關鍵。消費者對網上商家的信任在吸引新的消費者和留住已有的消費者兩方面都起著重要的作用,尤其是消費者對網上商店是否可信的判斷將會影響新老消費者參與電子商務的意願。信任在電子商務中格外重要,因為消費者在這種不確定環境中更容易被商家利用。Amazon,tom就在沒有徵求消費者同意的情況下與第三方機構共享消費者個人的信息。雖然消費者的信任是影響消費者接受並使用電子商務的一個很重要的因素,但並不是唯一的因素。在進行網上交易時,消費者通過商家的網站與商家進行互動,與其他信息技術的套用一樣,決定開始使用網站並且繼續使用它同樣取決於技術接受模型中兩個關鍵因素——感知的有用性和易用性。這樣對Online Stores接受的研究就可以從兩個緊密聯繫並且互補的方面進行:一個商家,一項信息技術。
在該研究模型中,以Amazon.com為研究對象,使用技術接受模型和電子商務的熟悉與信任模型(familiarity and trust mode1)從上述兩個方面對消費者的網上購買意向進行研究。
因素測度
不同的技術接受模型因為接受的對象不同,其因素也有差異。對這些因素的測量是實證的基礎,不同技術接受模型的因素測度比較。
實證研究
 表-3數據分析方法
表-3數據分析方法1、不同技術接受模型的變數分析
不同的技術接受模型具有不同的拓撲結構,實證的變數也各不相同,表2分析了經典的實證研究文獻的模型變數。
2、實證研究中數據的採樣和數據分析方法(見表3)
出於方便和成本的考慮,大部分實驗的受試者為大學的本科生或研究生。實驗過程一般為:首先讓學生訪問一個網站,之後讓他們根據訪問網站的感受填寫問卷,也有直接讓受試者填寫問卷。問卷編制採用Likert法,即每個問題提供5或7種選擇,以5種為例分為:很不贊同(1),不贊同(2),既不贊同也不反對(3),基本贊同(4),很贊同(5),這符合人們判斷問題的方式。問卷回收之後進行甄別,剔除那些不合格的;然後檢驗問卷的信度和效度,再採用各種方法,如主成分分析法、結構方程模型、多元線性回歸等方法來驗證模型。
實例分析
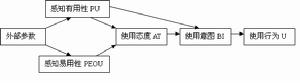 示意圖
示意圖1.研究對象:網上書店用戶。
2.研究緣起:圖書網路行銷的方式包括網上書店行銷、出版社網站行銷、Email行銷、手機行銷、部落格行銷等,而其中又以網上書店模式最為成熟和具有研究價值。
3.研究目的:利用TAM理論分析影響網上書店運營的外在因素,並試圖尋找出哪些因素對顧客——網路用戶的影響最大,從而幫助網上書店改善它們的運營模式。
4.外部變數細化:將TAM理論套用到網上書店研究,需要將上述模型中的外部因素細化。具體來說,影響用戶使用行為的外部變數包括:網站基本功能、書目資訊功能、個性服務功能、配送服務功能、圖書質量、價格以及交易安全性。利用TAM分析框架,還需要將上述外部變數在問卷中以問題形式細化,這裡不贅述。
5.研究方法:本研究採取向網上書店用戶發放調查問卷的形式,對上述變數進行細化、打分。本案例問卷設計採用李克特量表(Likertscaling),對每一問題的回答選項分為完全不同意、不同意、沒意見、同意、完全同意,並分別賦值1~5。
本案例目的在於驗證網站基本功能、書目資訊功能、個性服務功能、配送服務功能以及交易安全性等指標與網上書店使用行為之間的相關關係,由於TAM理論在感知有用性與使用行為之間存在正相關關係,本案例主要驗證上述指標與感知有用性之間的相關性。
本研究將各指標的相應題項得分進行加總平均,作為各研究變數的測量結果,這一方法也是有據可查的(Gerbing&Anderson,1988)。本案例所採取的驗證方法為簡單線性回歸,主要檢驗指標將在各個檢驗中給出。
(1)樣本基本資料。本次調查採用網上投放問卷的形式,共發放問卷250份,收回有效問卷194份,問卷回收率為77.6%。通過對收回樣本進行統計,男性在總人數中占60.3%,女性占39.7%。學歷中本科所占的比例最大,達到60.8%;網齡調查中,2年以上的有56.2%,占大多數。這個正好和張志強在《從看國區域網路上書店發展》一文中的觀點相符合。
(2)回歸分析及相關指標。回歸分析是在大量統計數據基礎上,利用數理統計方法建立因變數與自變數之間的回歸關係函式表達式。
標準化β是回歸分析中的一個量度指標,正值表示自變數與因變數之間存在正相關關係,而負值則表示自變數與因變數之間存在負相關關係。
p值為結果可信程度的一個遞減指標,p值越大,樣本中變數的關聯越不是總體中各變數關聯的可靠指標。實際上,p值是將觀察結果認為有效,即具有總體代表性的犯錯機率。如p=0.05提示樣本中變數關聯有5%的可能是由於偶然性造成的。在許多研究領域,0.05的p值通常被認為是可接受錯誤的邊界水平。
