
基本定義
用數軸上的一段經歷或一個數據區間,表示總體參數的可能範圍.這一段距離或數據區間稱為區間估計的置信區間。
參數估計的一種形式。通過從總體中抽取的樣本,根據一定的正確度與精確度的要求,構造出適當的區間,以作為總體的分布參數(或參數的函式)的真值所在範圍的估計。例如,估計一種藥品所含雜質的比率在1~2%之間;估計一種合金的斷裂強度在1000~1200千克之間,等等。在有的問題中,只需要對未知量取值的上限或下限作出估計。如前例中,一般只對上限感興趣,而在第二例中,則只對下限感興趣。
在數理統計學中,待估計的未知量是總體分布的參數或的某個函式()。區間估計問題可一般地表述為:要求構造一個僅依賴於樣本X=(1,2,…,)的適當的區間[(X),(X)],一旦得到了樣本X[2kg]的觀測值,就把區間[(),()]作為或()的估計至於怎樣的區間才算是“適當”,如何去構造它,則與所依據的原理和準則有關。這些原理、準則及構造區間估計的方法,便是區間估計理論的研究對象。作為參數估計的形式,區間估計與點估計是並列而又互相補充的,它與假設檢驗也有密切的聯繫。
置信區間理論這是1934年,由統計學家J.奈曼所創立的一種嚴格的區間估計理論。置信係數是這個理論中最為基本的概念。
置信係數奈曼以機率的頻率解釋為出發點,認為被估計的是一未知但確定的量,而樣本X是隨機的。區間[(X),(X)]是否真包含待估計的,取決於所抽得的樣本X。因此,區間 [(X),(X)]只能以一定的機率[537-03]包含未知的。對於不同的,()之值可以不同,()對不同的取的最小值1-(0<<1)稱為區間[(X),(X)]的置信係數。與此相應,區間[(X),(X)]稱為的一個置信區間。這個名詞在直觀上可以理解為:對於“區間[(X),(X)]包含”這個推斷,可以給予一定程度的相信,其程度則由置信係數表示。
對的上、下限估計有類似的概念,以下限為例,稱(X)為的一個置信下限,若一旦有了樣本X,就認為不小於(X),或者說,把估計在無窮區間[(X),∞)內。“不小於(X)”這論斷正確的機率為[537-04][537-4])。1()對不同的[2kg][2kg]取的最小值[2kg]1-(0<<1)稱為置信下限(X)的置信係數。
在數理統計中,常稱不超過置信係數的任何非負數為置信水平。
優良性準則置信係數1- 反映了置信區間[(X),(X)]的可靠程度,1-愈大,[(X),(X)]用以估計時,犯錯誤(即並不在[(X),(X)]之內)的可能性愈小。但這只是問題的一個方面。為了使置信區間[(X),(X)] 在實際問題中有用,它除了足夠可靠外,還應當足夠精確。比如說,估計某個人的年齡在 5至95歲之間,雖十分可靠,但太不精確,因而無用。通常指定一個很小的正數(一般, 取0.10,0.05,0.01等值),要求置信區間[(X),(X)]的置信係數不小於1-,在這個前提下使它儘可能地精確。對於“精確”的不同的解釋,可以導致種種優良性標準。比較重要的有兩個:一是考慮區間的長度(X)-(X)愈小愈好。這個值與X有關,一般用其數學期望E((X)-(X))作為衡量置信區間[(X),(X)] 精確程度的指標。這個指標愈小, 置信區間的精確程度就愈大。另一個是考慮置信區間 [(X), (X)]包含假值(指任何不等於被估計的 的值) 的機率[537-5][537-05],它愈小,[(X),(X)]作為的估計的精度就愈高。
如果(X)是的置信下限,則在保證(X)的置信係數不小於1-[2kg]的前提下,(X)愈大,精確程度愈高。這也可以用[(X) ,∞)包含假值(<)的機率[537-5][537-06]來衡量,此機率愈小,置信下限(X)的精確程度愈高。對置信上限有類似的結果,若在某個準則下,一個置信區間(或上、下限)比其他置信區間都好,則稱它為在這個準則下是一致最優的。例如,在上述準則下,置信係數1-的一致最優置信下限(X)定義為:(X)有置信係數1- ,且對任何有置信係數1-的置信下限1(X),當<時,成立[537-07]>
常見形式
簡介
區間估計,區間估計的區間上、下界通常形式為:“點估計±誤差”
 區間估計
區間估計“總體均值”的區間估計
符號假設
總體均值:μ
總體方差:σ
樣本均值:x* =(1/n)×Σ(Xi)
樣本方差:s* =(1/(n-1))×Σ(Xi-x*)^2
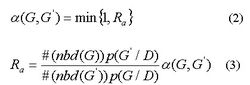 符號假設
符號假設置信水平:1-α
顯著水平:α
問題
已知n個樣本數據Xi (i=1,2,...,n),如何估計總體的均值?
首先,引入記號:
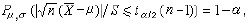 區間估計
區間估計σ'=σ/sqrt(n)
s'=s*/sqrt(n)
然後,分情況討論:
情況1小樣本(n<30),σ已知,此時區間位於 x* ± z(α/2)×σ'
情況2小樣本(n<30),σ未知,此時區間位於 x* ± t(α/2)×s'
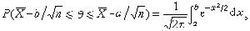 區間估計
區間估計情況3大樣本(n≥30),σ已知,此時區間位於 x* ± z(α/2)×σ'
情況4大樣本(n≥30),σ未知,此時區間位於 x* ± z(α/2)×s'
其中,z(α/2)表示:常態分配的水平α的分位數
t(α/2)表示:T分布的水平α的分位數
假設檢驗
 貝葉斯方法
貝葉斯方法另一種是利用區間估計與假設檢驗的聯繫,設要作θ的置
信係數為1-α 的區間估計,對於任意的θ0,考慮原假設為 H:θ=θ0,備擇假設為 K:θ≠θ0。設有一水平為α 的檢驗,它當樣本X屬於集合A( θ0)時接受H。若集合{θ0∶X∈A(θ0)}是一個區間,則它就是θ的一個置信區間,其置信係數為1-α。就上例而言,對假設H:μ=μ0的檢驗常用t檢驗:當時接受μ=μ0,集合即為區間 這正是前面定出的μ的置信區間。若要求θ的置信下限(或上限),則取原假設為θ≤θ0(或θ≥θ0),備擇假設為θ>;θ0(或θ<;θ0),按照同樣的方法可得到所要求的置信下(上)限。
還有一種方法是利用大樣本理論(見大樣本統計)。例如,設x1,x2,…,xn為抽自參數為p的二點分布(見機率分布)的樣本,當n→∞時,依分布收斂(見機率論中的收斂)於標準常態分配N(0,1),以 uα/2記N (0,1)的上 α/2分位數,則有。所以,可作為p的一個區間估計,上面的極限值1-α就定義為它的漸近置信係數。
推斷法
 費希爾的信任推斷法
費希爾的信任推斷法20世紀30年代初期,統計學家R.A.費希爾提出了一種構造區間估計的方法,他稱之為信任推斷法。其基本觀點是:設要作θ的區間估計,在抽樣得到樣本X以前,對θ一無所知,
樣本X透露了θ的一些信息,據此可以對θ取各種值給予各種不同的“信任程度”,而這可用於對θ作區間估計。例如,設X是從正態總體N(θ,1)中抽出的樣本,則服從標準常態分配N(0,1),由此可知,對任何α
即
費希爾把這個等式解釋為:在抽樣以前,對於θ落在區間內的可能性本來一無所知,通過抽樣,獲得了上述數值,它表達了統計工作者對這個區間的"信任程度",若取b)=-α=uα/2,則得到區間,其信任程度為 1-α。即當用上述區間作為θ的區間估計時,對於“它能包含被估計的θ”這一點可給予信任的程度為1-α。
在本例以及其他某些簡單問題中,用費希爾的方法與用奈曼的方法得出一致的結果。但是,這兩個方法不僅在基本觀點上不一致,而且在較複雜的問題中,所得出的結果也不同。一個著名的例子是所謂的費希爾-貝倫斯問題:設兩個常態分配μ1,μ2,σ娝,σ娤都未知,要求μ1-μ2的區間估計。費希爾用他的方法提供了一個與奈曼理論不一致的解法,奈曼在1941年曾對此進行了詳盡的討論。
另外。
