
分析數據的統計處理
正文
分析化學測定的全過程都離不開物理量的測量,例如稱量,量體積,讀取電位、吸光度或峰高等信號值。這些測量技術對於環境溫度、濕度、試劑純度、儀器性能甚至個人的習慣等一系列因素都會在一定程度上產生敏感,從而造成測量數據的波動。實驗誤差是客觀存在的,分析結果必然帶有不確定性。為處理這些波動的數據並恰當地定量描述帶有不確定度的結果,就要用專門研究起伏波動的統計學工具,後者是建立在機率論基礎上的,可以幫助實驗者科學地收集、整理和分析數據,從中獲得信息,併合理表達數據,以說明研究對象的某些特徵。誤差 測量值x帶有誤差E,測量值去掉誤差就等於真值μ,μ=x-E,所以誤差的定義為:E=x-μ,即測量值偏離真值的程度,也是測量值的不確定度。
絕對誤差 測量值大於真值時誤差為正數,表示結果偏高;反之,誤差為負數時表示結果偏低。這裡的誤差都是絕對誤差,它具有與測量值和真值相對的量綱,也只有在與測量值一同考慮時才有意義。例如,0.05%的絕對誤差,對於大約含矽60%的矽酸鹽中矽的測定是令人滿意的,但是發生在含量僅0.01%的痕量組分分析時,就不容許了。
相對誤差 絕對誤差在真值中所占的比率稱相對誤差,一般用百分率表示:
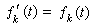
粗差 也稱過失誤差,是由於操作誤差而造成的。
系統誤差 它的產生是有一定原因的,系統誤差的大小在相同的測定過程中是恆定的,或者遵循一定的規律變化,例如隨樣品量或試劑用量的大小按比例變化。系統誤差又有一定的指向,例如稱量一種吸濕性物質,稱量誤差總是正值。從系統誤差的來源看,屬於方法和技術問題,知道了產生的原因,便可設法消除或修正,所以也叫可定誤差。
隨機誤差 在相同條件下重複多次測定同一物理量時,誤差的絕對值和符號的變化或大或小,或正或負,看來毫無規律和純屬偶然,這種誤差稱為隨機誤差,也叫偶然誤差。它遵循隨機變數的統計規律,單個地看是無規性的,但就其總體來說,正是由於單個的無規性,才導致了求它們的總和時有正負相消的機會,而且隨著變數個數的增加,誤差平均值趨近於零。這種抵償正是統計規律的表現,所以隨機誤差是可以用機率統計的方法來處理的。
精密度和準確度 誤差代表不確定度,即不精密度和不準確度,但習慣上用其倒數來表示精密度和準確度。精密度高的實驗結果,其準確度不一定高(除非不存在系統誤差);但精密度高卻是準確度高的先決條件。
精密度純屬隨機誤差引起的不確定度部分,它反映一組重複測定的數據相互接近的程度或說明分散的程度。在分析化學中,根據具體情況的不同,可用以下兩種方式表示精密度:①重複性,是在完全相同條件(同一操作者、同一儀器、同一實驗室和較短的時間間隔)下用相同方法分析相同的樣品所得一組重複測定數據的精密度;②再現性,是不同條件(不同分析人員、不同儀器、不同實驗室、不同時間)下用相同方法分析相同的樣品所得一組測定數據的精密度。
準確度表征測量值與真值的偏離程度,廣義的準確度應包含系統誤差和隨機誤差的聯合效應。
基礎統計學概念 總體、個體和樣本 統計學中把準備測量的一個滿足指定條件的個體的集合叫做總體,其中的每個單位是一個個體,從總體中隨機抽出的一組個體叫做一個樣本,樣本中個體數目即樣本的大小或樣本容量。對分析化學來說,總體是指在給定條件下經過無限多次重複測定得到的無限多個數據的集合。這只能是理論性概念,因為實際能夠得到的是有限的N次重複測定的N個測量值,即樣本容量為N的一個樣本,通過樣本的統計量來估計總體的參數。
常態分配 同一個總體的無限多個數據通常總是聚集在某箇中心值周圍。高於或低於中心值的數據對稱分布在中心值兩旁。距中心值越遠的值出現的頻率越小。若以頻數對測量值作圖,可得圖1
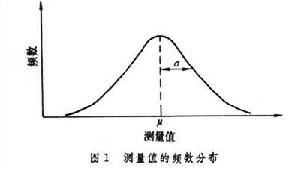 中的鐘形曲線,曲線越寬,在指定條件下測得的數據越分散,精密度也越差,因此以反映分布曲線寬度的參數σ(曲線拐點到中心值的橫坐標值)表征精密度,同時以反映數據集中趨勢的參數μ表征總體平均值。確定了μ和σ,分布就確定了。還可用N(μ,σ2) 表示中心值為μ,分散性參數為σ2的常態分配。
中的鐘形曲線,曲線越寬,在指定條件下測得的數據越分散,精密度也越差,因此以反映分布曲線寬度的參數σ(曲線拐點到中心值的橫坐標值)表征精密度,同時以反映數據集中趨勢的參數μ表征總體平均值。確定了μ和σ,分布就確定了。還可用N(μ,σ2) 表示中心值為μ,分散性參數為σ2的常態分配。 樣本的統計量 用來估計總體參數。設在指定條件下重複測定一個化學樣品N 次,以x1,x2,…, xN代表N個測定值xi,便可定義下面的樣本統計量為總體參數的估值:
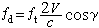
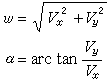 為樣本均值,
為樣本均值,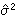 為樣本方差,N-1為樣本的自由度。和是隨樣本而變化的隨機變數。只有當N趨於∞時,它們才趨近於常數,成為總體均值μ和總體方差捛2。方差的平方根叫做標準偏差捛:
為樣本方差,N-1為樣本的自由度。和是隨樣本而變化的隨機變數。只有當N趨於∞時,它們才趨近於常數,成為總體均值μ和總體方差捛2。方差的平方根叫做標準偏差捛: 

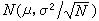 分布。N增大使σ塣減小的收益,因平方根的關係而有限度。若想使標準偏差減為1/10,便要相應地使N增大100倍,何況系統誤差並不因多次平均而減小,所以通常只在N<20時才考慮增大N的收益。
分布。N增大使σ塣減小的收益,因平方根的關係而有限度。若想使標準偏差減為1/10,便要相應地使N增大100倍,何況系統誤差並不因多次平均而減小,所以通常只在N<20時才考慮增大N的收益。 不確定度和區間估計 誤差的標準常態分配 將測量值 x的頻數分布圖的橫坐標改成以標準偏差為單位的誤差,以變數Z表示:

 這時的分布叫標準常態分配,以N(0,1)表示。
這時的分布叫標準常態分配,以N(0,1)表示。 區間估計 圖2中的常態分配曲線又叫高斯曲線,它根據高斯誤差方程畫出。
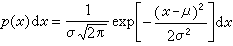
這裡σ的係數就是N(0,1)分布中的Z值, 若取機率為0.95,即意味著Z=1.96,各種Z值下的機率可從一般書刊中查到。
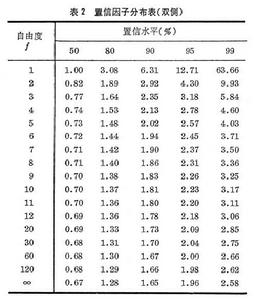
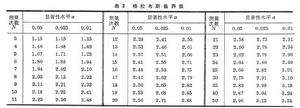
容許區間 對總體而言。μ±Zσ 區間內的分布曲線稱覆蓋域,以P表示,是由Z值規定的。在有限次測定中用樣本值塣和S代替總體參數μ和σ時,由於塣和S是隨樣本而異的隨機變數,致使選定K值組成的塣±KS區間也是隨機的,難以定量覆蓋域。但是如果在選擇P與K的同時外加一個出現這種P值的可能性或機率γ,便能用以下的形式說明問題,例如要回答欲使覆蓋域不小於P的可能性為γ,應取什麼K值。表1給出與常用P和γ 相對應的K值。
 分析數據的統計處理
分析數據的統計處理置信區間 已知單次測量值分布的標準偏差σ,樣本容量為N的測量平均值塣分布的標準偏差
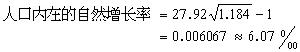 ,則通過塣和不確定度
,則通過塣和不確定度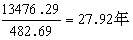 所組成的區間
所組成的區間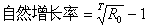 能夠括入總體均值μ的機率是由Z值決定的,例如:
能夠括入總體均值μ的機率是由Z值決定的,例如: 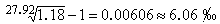
這個置信因子已由W.S.戈塞特解決了,他把置信因子t定義為:
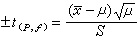
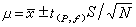
 分析數據的統計處理
分析數據的統計處理顯著性檢驗 在實際套用中往往不只是估計總體的值,還需要說明總體的某種性質,例如兩個樣本的差異是否顯著到不能代表同一總體。這裡包括工藝改變後產品質量有無顯著變化,兩種分析方法測定結果是否一致等具體問題。
這類統計推斷都是先提假設,然後按照某種邏輯在某種機率上判斷是否有顯著性差異,以決定原假設的成立與否。所以,統計檢驗方法又叫做顯著性檢驗或假設檢驗。
顯著性水平 顯著性檢驗離不開預設的小機率,例如常態分配的測量值落到區間 【μ±2σ】以外的機率小於0.05,落到區間【μ±3σ】以外的機率更小於0.01。在N 趨近於∞時,機率如此小的事件在有限次測量中理應不出現。如果竟然出現了,就有理由認為它是異常的。這個小機率越小,相應的事件就越顯得異常,所以此小機率在統計檢驗中叫做顯著性水平α,可用它來反映顯著異常的程度。通常α在0.05以下便認為是顯著。
統計檢驗在分析化學中的套用 ①極值的取捨,在同一組樣本值中的最大值xmax和最小值xmin叫極值。對極值容易產生懷疑。它的取捨往往很影響精密度。如果技術上找不到捨棄的原因而又有懷疑時,可藉助統計檢驗工具。先假設被檢值不異常,選定顯著性水平α(例如α=0.05)和一種判據公式,例如格拉布斯檢驗公式:
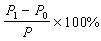
 分析數據的統計處理
分析數據的統計處理先假設二者在顯著性水平α上無顯著差異,可視為來自同一總體,計算統計量t:
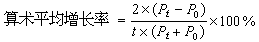
參考書目
ASTM, Committee E-11 on Statistical Methods,ASTM Manual on Presentation of Data and Control Chart Analysis,ASTM Special Technical Publication 15D,1976.
