
植物群落分析
正文
一類生態學方法,即對植物群落(及其環境)的觀測數據進行數學分析以求揭示其內在的生態學規律。植物群落,不同於生物群落,只包括一定地區內的植物,不包括動物和微生物,而在具體研究時更常集中於某些重點考察的生活型。但在植物群落分析中,特別是在排序研究中,環境因子也是主要研究內容,這所謂的環境因子也可以包括動物和微生物在內。植物群落分析方法,以從自然植物群落的統計學樣本中測取得的群落屬性與環境變化的定量數據為基礎,套用數學原理和計算技術,對大量數據進行兩種方法途徑的綜合:一種是把每個群落抽樣單元,按其屬性的相似性或相異性,聚合或劃分為許多組群(分類單元),這稱為群落的數值分類。另一種是把每個群落抽樣實體視為點,在生境梯度或群落屬性梯度的n維坐標空間中,序化地標記出來,這稱為群落排序。數值分類和排序是定量地客觀地對群落進行分類,揭示植物群落類型及其組成種群與環境相互關係的新技術。由於電子計算機的普遍套用,這些數值方法正在迅速發展,不斷完善。植物群落抽樣 考察植物群落,選擇出可代表該群落整體並具有一致性的一定區限,叫做群落樣地。在樣地內,為測計群落各項屬性,如種類組成、生活型、種群數量特徵、及環境因子特徵可設定一定面積、形狀或數量的小區(樣方),這是常用的一種群落抽樣方法。為了進行植物群落分析,要採取客觀抽樣法,即機率抽樣。可以按具體情況在隨機抽樣、系統(規則)抽樣、或分層抽樣三者中擇取一種。
樣方抽樣 樣方面積與形狀,原則上希望取最小表觀面積,最適的形狀。溫帶喬木群落最小面積一般為100~400平方米,熱帶森林更大些約1000~2000平方米;灌木群落約4~16平方米,草本群落1~4平方米,形狀多採用正方,也可視具體需要和種的分布格局、微地貌不同,取圓形或長條。
樣方數目多少,從統計學的要求,要有30~50個為好,如是分層抽樣,則每個層區中要有6~10個。群落性態變異大時,數目要多些,反之可以減少。
無樣方抽樣 也叫威斯康星學派的點樣法。是在群落樣地內按隨機或規則抽樣,配置一定數目(通常是50~100個)樣點。再以點為中心,按最近單株法、最近鄰體法,隨機對法、或中點四分法,記錄每株喬木學名,測量株距(d)、胸徑(圖1),集合n次測定的株距d,計算出喬木的平均株距:
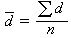 。由
。由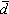 可算出每株喬木占有地表的平均面積:
可算出每株喬木占有地表的平均面積: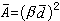 ,β是校正係數,上述4種無樣方抽樣方法的校正係數β,依次為 β=2,β=1.87,β=0.8,β=1。從喬木單株平均面積
,β是校正係數,上述4種無樣方抽樣方法的校正係數β,依次為 β=2,β=1.87,β=0.8,β=1。從喬木單株平均面積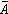 ,可計算單位樣地面積的喬木密度:
,可計算單位樣地面積的喬木密度: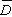 =1/(β)2=1/。同時,在每個樣點上做灌木和草本記名小樣方,根據喬木、灌木、草本種類的分布,可計算各個種的頻度。
=1/(β)2=1/。同時,在每個樣點上做灌木和草本記名小樣方,根據喬木、灌木、草本種類的分布,可計算各個種的頻度。 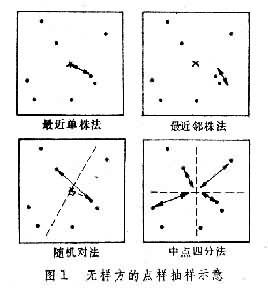 植物群落分析
植物群落分析原始數據的處理 抽樣調查取得的各項群落屬性的觀測數據,由於屬性的數據類型不同,量綱不一,數值大小懸殊,而各種分析方法對原始數據又各有一定要求,所以對原始數據要進行適當處理。首先要求類型統一,即把二元數據轉化成數量數據,或者反之,因多數方法只適合於分析同一類型的數據。其次,要對原始數據的數值進行轉換,即將原來數值x,轉換成
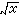 (只取正根),或其對數、倒數,或角度、機率等,以求更合理地體現它們的數量關係,使其具有一定的分布形式(如常態分配),或一定的數據結構(如線性結構)。第三,將原始數據標準化或中心化。原始數據的標準化,即用屬性或實體的總和、或最大值、或極差、或模來除該屬性的某個數據,實際上是把某個數值標準化為屬性總和的比值,取值在0與1之間。例如群落分析中將種群絕對多度換算為相對多度。樣方數據經標準化後,其幾何意義是各樣方點都從原來位置沿徑向投影到單位弦上,成為線性序列(圖2)。中心化主要是用平均值或離差來標準化各個原始數據。例如,平均值中心化是從屬性或樣方的各個原始數據中分別減去其平均值。中心化的幾何意義在使坐標原點移到樣方點的形心,由此給數值運算帶來很大方便,第四,原始數據的縮減,指去掉一些代表性不好或數據不完整的樣方,或者刪去各樣方中僅出現一次的孤種、或罕見種、或者生態學意義不大的常見種。縮減種數應當適當,不應影響研究結果。
(只取正根),或其對數、倒數,或角度、機率等,以求更合理地體現它們的數量關係,使其具有一定的分布形式(如常態分配),或一定的數據結構(如線性結構)。第三,將原始數據標準化或中心化。原始數據的標準化,即用屬性或實體的總和、或最大值、或極差、或模來除該屬性的某個數據,實際上是把某個數值標準化為屬性總和的比值,取值在0與1之間。例如群落分析中將種群絕對多度換算為相對多度。樣方數據經標準化後,其幾何意義是各樣方點都從原來位置沿徑向投影到單位弦上,成為線性序列(圖2)。中心化主要是用平均值或離差來標準化各個原始數據。例如,平均值中心化是從屬性或樣方的各個原始數據中分別減去其平均值。中心化的幾何意義在使坐標原點移到樣方點的形心,由此給數值運算帶來很大方便,第四,原始數據的縮減,指去掉一些代表性不好或數據不完整的樣方,或者刪去各樣方中僅出現一次的孤種、或罕見種、或者生態學意義不大的常見種。縮減種數應當適當,不應影響研究結果。 原始數據綜合表和數據矩陣 一般的群落調查,包括N個樣方,P個種的數據,可列成N列,P行的數據表:
 植物群落分析
植物群落分析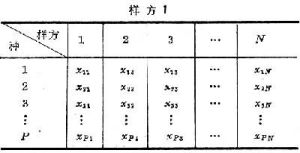 植物群落分析
植物群落分析數值分類技術 是直接以樣地內種的分布或種類組成的相對相似性數據為基礎的群落分類方法。兩個樣地的相對相似性數值,叫做相似係數,相似與相異在數學上是互補的概念,兩者都同樣可表述兩個樣地相似的程度。
相似係數的計算方法雖很多,但基本上可歸為2大類:一類是計算兩個樣地的群落種類組成成分的相似或相異程度,如匹配係數,關聯繫數等;另一類是計算兩個樣地中共有種的數量數據的相似或相異程度,如各種距離係數。
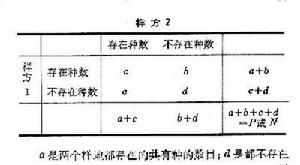
匹配係數與關聯繫數 依據數據矩陣中兩個列(樣地)的屬性(種)的二元數據“存在”與“不存在”,可構成2×2列聯表:
 植物群落分析
植物群落分析匹配係數的常用計算公式,有P.雅卡德(1901)的公式(1.1)和J.切卡諾夫斯基(1913)的公式(1.2),這兩個公式取值均在【0,1】的區間內。當a=0時,取值為0,表示完全相異;當α=P(總的種數)時,取值為1,表示完全相似。1-相似係數=相異係數。
雅卡德匹配係數=α/(α+b+c)(1.1)
切卡諾夫斯基匹配係數=2α/(2α+b+c) (1.2)
關聯繫數 較常用的計算方法有尤爾(1912)的公式(2.1)和達格內利(1962)的公式(2.2),取值均在【-1,+1】的區間。最大的負關聯;取值是-1,最大的正關聯,取值為+1。尤爾關聯繫數=(αd-bc)/(αd+bc) (2.1)
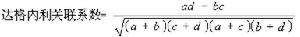 (2.2)
(2.2)
 植物群落分析
植物群落分析布雷-柯蒂斯距離公式:
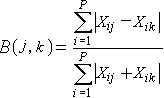 (3.1)
(3.1)
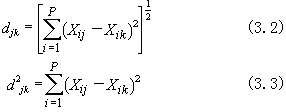
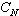 或
或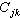 ;又叫Q矩陣。其中行和列的序號都表示樣方,其中元素表示j 樣方和k樣方的相似係數(j,k=1,2,…,N)。
;又叫Q矩陣。其中行和列的序號都表示樣方,其中元素表示j 樣方和k樣方的相似係數(j,k=1,2,…,N)。 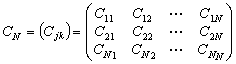
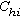 。這又叫R 矩陣,其中行和列的序號都表示種。元素表示第h種和第i種之間的相似係數(h,i=1,2,…,P)。
。這又叫R 矩陣,其中行和列的序號都表示種。元素表示第h種和第i種之間的相似係數(h,i=1,2,…,P)。 植物群落的數值分類 群落分類的基本單位是樣地(或樣方),即群落實體。群落的內涵特徵描述項目,如種類組成、種的頻度、多度或顯著度等的數值,即反映實體屬性的信息。數值分類一般是按屬性的相似或相異程度,將所有樣地(或樣方)集合分成若干個“同質的”樣地(樣方)組,使組內的成員儘可能地相似,不同組的成員儘可能地相異。即按群落所包含的各個屬性、或規定的各項屬性的變異幅度來分類。這些“同質”的樣方組,可以是等級的分類類級(如傳統分類的群叢,群屬,群目,群系等),也可以是非等級的類級(統稱為植物群落型)。通常按屬性分類,用樣方間的矩陣CN,稱為正分析,或R分析方法。但也有用屬性或種間矩陣CP的,稱為逆分析,或 Q分析方法。分類的方法程式有二大類,即聚合分類,或分劃分類。
等級聚合的分類 根據群落樣地(樣方)彼此間的相似程度,通過逐次合併,成為不同等級的“同質”樣方組,或聚簇(Clustor)的分類方法,也叫聚簇分析。等級聚合程式最早被切卡諾夫斯基(1909)用於人類學資料的分類,以後才被波蘭生態學家專門用於植被分類。
群落的聚簇分析,是多元的聚合方法。因為,群落樣地或樣方的N ×N 相似(異)係數矩陣CN是進行聚合的基礎。無論哪一種相似(異)係數,其數值都是從所有屬性的數據計算而來。聚合的程式一般是:①計算樣地(樣方)的 N×N 相似(異)係數矩陣CN;②先從CN中找出最相似的一對樣地(方)合併為第一個聚簇;③重算(N-1)×(N-1)的相似(異)矩陣;④再從中找出與第一次合併聚簇最相似的另一個樣地,併合並出另一個聚簇;⑤依次,重複逐次合併,直到全部樣地合併為一。簡言之,即從單個樣方開始聚合,再是聚簇與單個樣方、或與另外聚簇的聚合,自下而上直到把整個樣方集合聚合為一體,結果是產生一個逐級聚合分析的枝譜圖。
等級聚合過程中,有一個如何測算兩個聚簇之間的距離的問題。需要一個適合的測度
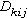 ,表示h聚簇到i和j聯合聚簇之間距離。通常套用的七種聚合方法是:最近鄰法;最遠鄰法;中線法;形心法;組平均法;平方和增量法;可變法等。蘭斯和威廉斯(1967)為這些計算群簇距離的不同聚合方法,建立了一個統一的模型。
,表示h聚簇到i和j聯合聚簇之間距離。通常套用的七種聚合方法是:最近鄰法;最遠鄰法;中線法;形心法;組平均法;平方和增量法;可變法等。蘭斯和威廉斯(1967)為這些計算群簇距離的不同聚合方法,建立了一個統一的模型。 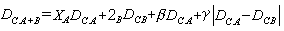
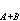 =nA+nB。2A,2B,β,γ是常數(模型係數)。
=nA+nB。2A,2B,β,γ是常數(模型係數)。 威廉斯和蘭伯特(1966)提出的信息分析方法,用對稱信息相似係數,即以樣方組合併引起的信息增量 △I,作為A與B樣方組間的相異性指標,將信息增量最小的成對群簇加以合併,其計算式為
△I(A,B)=I(A+B)-I(A)-IB
等級劃分的分類 是從N 個樣地(方)的集合開始,從上向下逐次分劃。即先按相似性分為二個樣方組,使組內相似性最大,組間相異性最大。接著對每個組再次分劃,最終達到一定要求的“同質”樣方組為止。等級分劃有單元和多元二類,現時通行的多為單元分劃方法。如關聯分析、組群分析和信息分析等方法。在群落數值分類中最常用的是關聯分析方法。
關聯分析,是基於在某個一致的群落中不同樣方之間種類是不相關的,即二種間的關聯是隨機的,因而可把種間關係最小的一些樣方,從樣方集合中分劃出來,作為一個類級。
關聯分析的程式是:①依據二元(種的存在與不存在)原始數據矩陣X,求出P個種的種間關聯繫數矩陣CP=(Chi),(h,i=1,2,…,P);②從種的關聯矩陣中找出一個與其他種關聯最大的種A,稱為臨界種或關鍵種。③在樣方集合中把含有臨界種A的樣方組(A),與不含臨界種的樣方(a)劃分開成二個子樣方組;④對(A)分別重複上面的程式,確定另一個臨界種B,按B種的有或無,從A中劃分出有B種存在的B樣方組。如此反覆進行,直到在分出的子組內部種間關聯繫數全都在規定的顯著水平以下,即達到劃分過程的“終止線”為止。⑤最後,也可得到等級劃分分類的樹譜圖(圖4)。
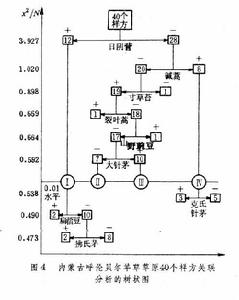 圖中橫坐標表示兩條終止線的兩個顯著水平,縱坐標表示各次分劃的X2/N的臨界值和分劃的過程。每一次分劃的兩支聯結線下的植物種是該次分劃的臨界種,(+)號表示含有該臨界種的樣方組,樣方數在方框內;(-)號表示無臨界種的樣方組,樣方數記在方框內。
圖中橫坐標表示兩條終止線的兩個顯著水平,縱坐標表示各次分劃的X2/N的臨界值和分劃的過程。每一次分劃的兩支聯結線下的植物種是該次分劃的臨界種,(+)號表示含有該臨界種的樣方組,樣方數在方框內;(-)號表示無臨界種的樣方組,樣方數記在方框內。 現在,一般關聯分析多採用威廉斯和蘭伯特(1959,1960)的關聯繫數X2,或均方關聯繫數V2。
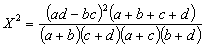
V2=X2/N
式中α,b,c,d,N,都是二個種的2×2列聯表中的數值。選用這二種關聯繫數,是因為X2係數可供進行顯著性檢驗,只有當 X2值大於或等於一定的顯著水平,0.1,0.05,0.02或0.01(對應的臨界值分別為2.706,3.841,5.412或6.635)時,才承認該兩個種(種h和種i)在各該水平上是顯著關聯的。
組群分析,是以某些特定種的存在與不存在把樣地(方)集合劃分開來。選定特定種是依據它們與另外許多種共同出現的頻度。
等級劃分分類的多元分劃方法,有依據樣方組之間不相似性的組內平方距離的總和法;加權歐氏距離法,以及信息分析方法,不過,在等級劃分中套用多元分析並不普遍。
植物群落的排序 是識別環境因子、種群和群落三個方面彼此之間相互聯繫的一類群落分析方法。排序的理論基礎是在環境因子的梯度與植被的種群和群落屬性的連續變化具有一定的秩序性。因而,可以將群落樣地(樣方)視為點,在以因子梯度為軸的坐標空間中分別把各個點的位置定出來,從而顯示群落抽樣及其屬性(種群)的變化的抽象格局;明晰地反映群落類型物種分布,種群特徵與主導環境因子的關係。
Л.Г.拉緬斯基(1924,1930),早在20世紀20年代就開始以環境因素如土壤肥力和土壤水分的梯度作為坐標軸,排列物種或群落的分布。之後,R.H.惠特克(1951,1967)的梯度分析則是從環境因子、種群、群落三方面的梯度來研究植物群落特徵變化的規律。
梯度分析有二條途徑。如果是在以已知的一個或多個環境梯度為軸的坐標空間中排列群落樣地(樣方抽樣)的話,這叫做直接梯度分析。若是以從群落抽樣(樣方)的相似性或物種相關性的測定導出的抽象軸為坐標,排列出樣地或種群的變化趨向,則叫做間接梯度分析。
直接梯度分析 是基於Л.Г.拉緬斯基(1924)對不同植物種的種群多度(密度)依從於環境條件的變化的統計學分析和表述。他認為群落生境通常隨其不同環境因子的變化而呈現連續的變異。各個植物種在對環境的需求上具有多樣性,因而,在生境的連續變化中會顯示出不同物種各自的生態學的獨特性。在以環境梯度為軸的空間裡,直接表達種群、生態群組或群落分布模式的技術,就叫做直接梯度分析或排序。
直接梯度分析的程式是:①沿環境因子梯度間隔取樣;②列出梯度群落表;③描繪環境梯度種群數量分布曲線;④劃分生態組群,確定各生態組群的平均加權;⑤按以上步驟對另一環境因子進行分析,最後建立多維的複合梯度排列圖解。
R.H.惠特克(1954,1960)建立了群落樣地的比較定量法,用群落相似性百分率來表示各個群落樣本(樣地)的生態距離。PS=100-0.5∑|α-b|=∑min(α,b),α和b 是某個種在二個樣方中的重要性值。還可直接用海拔高度和地貌單元二組複合梯度為x和y 軸,在圖解上表述群落類型及種群分布格局與環境梯度的關係。
直接梯度分析技術,導致了種群獨特性、種群連續統和植被複合連續統等新的群落學理論的產生。
間接梯度分析 也叫間接排序,是以自然群落樣本(樣方)的N×N 相似矩陣或相異矩陣,導出抽象軸,將樣本作為點,在軸坐標空間裡定位,從而揭示群落與環境關係的一類數學方法。包括連續統分析或組成梯度分析,極點排序,主分量分析,相互平均法,位置向量排序和典範分析等不同分析方法。它是80年代在植被分析中發展最快的領域。
極點排序 簡寫PO是廣泛套用的一項簡易有效的間接排序技術。操作程式是:
① 把N個群落樣本中各個種的屬性,標準化為重要值。
② 將成對樣本按種的重要值計算兩個樣本的相似係數,或兩者的相異係數。相似係數計算式為PS=∑min(x,y),式中的 min(x,y) 是共有物種在抽樣x和y中的兩個最小值。相異係數計算式為PD=1-PS。
③ 構造N×N 的相似係數和相異係數矩陣(是兩個“半矩陣”)。
④ 建立第一排序軸(x 軸)。選取矩陣中相異係數值最大的兩個樣本, 設A與B兩個樣本作為x 軸的端點樣本。令A位於x 軸的O端;則B為x 軸的遠端,B與A的坐標距離,即A與B 的相異係數值。
⑤ 確定其他樣本在x 軸上的坐標定位,及其與x軸的偏離值。設擬定位的樣本為C,CA樣對的PD值為DA,CB對的PD值為DB,A端與B端的距離為L,則C在x軸的坐標,是C與O 端A的距離x,x可根據比爾斯(1960)的公式計算:
x=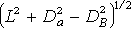
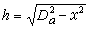 。
。 ⑥ 建立第二排序軸(y軸)。選取與x 軸偏離值最大的一個樣本,設為D,D即可定為y軸的O端,再選取一個與D的相異係數最大的一個樣本,設為E,E即是y軸的另一遠端。其他樣本,也可按照⑤的方法,確定它們在y 軸上的坐標。同樣,還可選取第三排序軸(z軸)。極點排序通常只求二或三維排序坐標。
⑦ 排序效果檢驗。通常可按排序坐標求出各對樣本間的歐氏距離d。再把N(N-1)/2個歐氏距離,與原來各對樣本的相似係數作為二組數據,計算它們之間的相關係數r。如果r在0.9以上,即可認為排序後的樣本距離與原數據所反映的相異性是相擬合的。排序效果是令人滿意的。
極點排序如果用P×P 的屬性相似矩陣,則可以顯示種群與環境關係的秩序,還有人套用這一技術研究土壤特性的排序(蒙克,1965)。極點排序技術經過不斷修正與改進,它在多領域裡套用取得明顯效果。具有計算簡便,排序直觀,生態學意義明晰等優點。
主分量分析 主分量分析 (PCA)是一種數據分析的數學方法,其目的是使多維空間中的樣方點群投影到低維(2~3維)空間的坐標軸上,並力求獲得原始數據的信息損失最小,或保存最多的線性序列。符合這種要求的坐標軸就稱為主分量。古多爾(1954)將這種方法首先套用到群落分析。主分量分析排序的一般程式是:
① 對原始數據N×P 的X 矩陣中的屬性(種的)數據中心化、標準化,使坐標原點稱到處於N個點的形心(塣1,塣2,…,塣P)處。
② 計算屬性(種)間的內積矩陣S。S=XXT=(
 ),(h,i=1,2,…,P)。
),(h,i=1,2,…,P)。 ③ 求出S的特徵根和特徵向量。S的特徵根即特徵多項式|S-γI|=0的P個根。將特徵根依大小次序排列成h1≥h2≥…≥hP。再由us=Au的關係解出P個h相應的特徵向量,並將它們依次按行排列,得到變換矩陣u。
④ 求N個樣方的排序坐標。根據變換矩陣u,即可由Y=uX,計算出N個樣方點對新坐標系的P個主分量的坐標。一般只需取各個樣方點對第一、第二或第三主分量的值γ,以便在2~3維空間裡畫出N個樣方點的直觀排序圖形。
⑤ 估計屬性對主分量的作用。因為主分量是原有屬性的線性組合,各個主分量本身所荷載的信息量只是原來各屬性的綜合效應,並非原來某一屬性的作用。所以還要估計屬性(種)在其所在主分量中所占的負荷量大小,由此可了解各屬性對排序所起的作用大小。
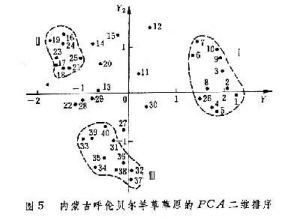
曾對內蒙古呼盟羊草草原的40個樣方、32個種的數據,進行PCA分析排序,得到二維排序圖(圖5)。在這個PCA排序中,根據13個種計算第一和第二主分量保留的信息,只占總信息44.3%,加上第三主分量可增大到50.7%。其中第一維y1占28.4%,第二維y2占15.9%。排序的結果,將樣方分布構成 3個點集,表征因生境的差異而存在三種群落類型。在y1軸的左面和右面是與土壤水分梯度有關的A與B兩個群落;在y2的上面和下面的B和C兩個群落是與土壤鹽漬化梯度有關的兩個群落。對y1作用最大的種為不太耐旱的日陰菅(負荷量2.6);對y2作用大的是只存在於半乾旱生境的柴胡 (1.9)和只分布在鹽漬化土壤中的鹼蒿(-1.81)。這3個種也就是劃分羊草草原 3個群叢組的臨界種。
 植物群落分析
植物群落分析① 計算物種與抽樣的排序坐標間的相互平均關係。
② 用疊代法求出第一軸上的y和z。
③ 求其他軸上的排序坐標。
④ 估計特徵值(即相應軸的方差)γ。
⑤ 對物種和樣本(樣方)進行排序。
排序方法的發展,正面臨一個如何真實反映生境、物種、群落三者間的非線性關係,及其連續、隨機和不確定性等特徵的問題。
數值分類,早期或現代發展的排序,都僅僅是研究植物群落生態學的一種數學技術,它只是手段而不是目的。重要的是如何套用生態學實際知識和理論思維,指導方法的套用並對方法的結果作出正確的判斷和解釋。
參考書目
陽含熙、盧澤愚:《植物生態學的數量分類方法》,科學出版社,北京,1981。
周紀綸:植被的多因子生態系統分析途徑,《植物生態學與地植物學叢刊》,1981。
R.H.惠特克主編,周紀綸等譯:《植物群落分類》,科學出版社,北京,1985。
R.H.惠特克主編,王伯蓀譯:《植物群落排序》,科學出版社,1986。
