LZW算法簡介
字元串和編碼的對應關係是在壓縮過程中動態生成的,並且隱含在壓縮數據中,解壓的時候根據表來進行恢復,算是一種無損壓縮.
根據 Lempel-Ziv-Welch Encoding ,簡稱 LZW 的壓縮算法,用任何一種語言來實現它.
LZW壓縮算法
的基本概念:LZW壓縮有三個重要的對象:數據流(CharStream)、編碼流(CodeStream)和編譯表(String Table)。在編碼時,數據流是輸入對象(文本檔案的據序列),編碼流就是輸出對象(經過壓縮運算的編碼數據);在解碼時,編碼流則是輸入對象,數據流是輸出對象;而編譯表是在編碼和解碼時都須要用藉助的對象。
字元(Character):最基礎的數據元素,在文本檔案中就是一個位元組,在光柵數據中就是一個像素的顏色在指定的顏色列表中的索引值;
字元串(String):由幾個連續的字元組成;
前綴(Prefix):也是一個字元串,不過通常用在另一個字元的前面,而且它的長度可以為0;
根(Root):一個長度的字元串;
編碼(Code):一個數字,按照固定長度(編碼長度)從編碼流中取出,編譯表的映射值;圖案:一個字元串,按不定長度從數據流中讀出,映射到編譯表條目.
LZW壓縮算法
的基本原理:提取原始文本檔案數據中的不同字元,基於這些字元創建一個編譯表,然後用編譯表中的字元的索引來替代原始文本檔案數據中的相應字元,減少原始數據大小。看起來和調色板圖象的實現原理差不多,但是應該注意到的是,我們這裡的編譯表不是事先創建好的,而是根據原始檔案數據動態創建的,解碼時還要從已編碼的數據中還原出原來的編譯表.
LZW算法
LZW壓縮算法
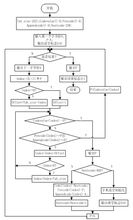 LZW算法流程圖
LZW算法流程圖LZW算法基於轉換串表(字典)T,將輸入字元串映射成定長(通常為12位)的碼字。在12位4096種可能的代碼中,256個代表單字元,剩下3840給出現的字元串。
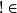 LZW算法
LZW算法LZW字典中的字元串具有前綴性,即 ωK∈T=>;ω
T。
LZW算法流程:
LZW解壓算法
具體解壓步驟如下:
(1)解碼開始時Dictionary包含所有的根。
(2)讀入在編碼數據流中的第一個碼字 cW(它表示一個Root)。
(3)輸出String.cW到字元數據流Charstream。
(4)使pW=cW 。
(5)讀入編碼數 據流 的下一個碼字cW 。
(6)目前在字典中有String.cW嗎?
YES:1)將String.cW輸出給字元數據流;
2)使P=String.pW;
3)使C=String.cW的第一個字元;
4)將字元 串P+C添 加進Dictionray。
NO :1)使P=String.pW ;
2)使C=String.pW的第一個字元;
3)將字元串P+C輸出到字元數據流並將其添加進Dictionray(現在它與cW相一致)。
(7)在編碼數據 流中還有Codeword嗎?
YES:返回(4)繼 續進行 解碼 。
NO:結束解碼 。
LZW壓縮的特點
LZW碼能有效利用字元出現頻率冗餘度進行壓縮,且字典是自適應生成的,但通常不能有效地利用位置冗餘度。
具體特點如下:
l)LZW壓縮技術對於可預測性不大的數據具有較好的處理效果,常用於TIF格式的圖像壓縮,其平均壓縮比在2:1以上,最高壓縮比可達到3:1。
2)對於數據流中連續重複出現的位元組和字串,LZW壓縮技術具有很高的壓縮比。
3)除了用於圖像數據處理以外,LZW壓縮技術還被用於文本程式等數據壓縮領域。
4)LZW壓縮技術有很多變體,例如常見的ARC、RKARC、pkzip高效壓縮程式。
5)對於任意寬度和像素位長度的圖像,都具有穩定的壓縮過程。壓縮和解壓縮速度較快。
6)對機器硬體條件要求不高,在 Intel 80386的計算機上即可進行壓縮和解壓縮。
