
定義
關聯分析是一種簡單、實用的分析技術,就是發現存在於大量數據集中的關聯性或相關性,從而描述了一個事物中某些屬性同時出現的規律和模式。
關聯分析是從大量數據中發現項集之間有趣的關聯和相關聯繫。關聯分析的一個典型例子是購物籃分析。該過程通過發現顧客放入其購物籃中的不同商品之間的聯繫,分析顧客的購買習慣。通過了解哪些商品頻繁地被顧客同時購買,這種關聯的發現可以幫助零售商制定行銷策略。其他的套用還包括價目表設計、商品促銷、商品的排放和基於購買模式的顧客劃分。
可從資料庫中關聯分析出形如“由於某些事件的發生而引起另外一些事件的發生”之類的規則。如“67%的顧客在購買啤酒的同時也會購買尿布”,因此通過合理的啤酒和尿布的貨架擺放或捆綁銷售可提高超市的服務質量和效益。又如“‘C語言’課程優秀的同學,在學習‘數據結構’時為優秀的可能性達88%”,那么就可以通過強化“C語言”的學習來提高教學效果。
相關名詞
示例1:如下是一個超市幾名顧客的交易信息。
| TID | Items |
| 001 | Cola, Egg, Ham |
| 002 | Cola, Diaper, Beer |
| 003 | Cola, Diaper, Beer, Ham |
| 004 | Diaper, Beer |
TID代表交易流水號,Items代表一次交易的商品。
我們對這個數據集進行關聯分析,可以找出關聯規則{Diaper}→{Beer}。
它代表的意義是:購買了Diaper的顧客會購買Beer。這個關係不是必然的,但是可能性很大,這就已經足夠用來輔助商家調整Diaper和Beer的擺放位置了,例如擺放在相近的位置,進行捆綁促銷來提高銷售量。
1、事務:每一條交易稱為一個事務,例如示例1中的數據集就包含四個事務。
2、項:交易的每一個物品稱為一個項,例如Cola、Egg等。
3、項集:包含零個或多個項的集合叫做項集,例如{Cola, Egg, Ham}。
4、k−項集:包含k個項的項集叫做k-項集,例如{Cola}叫做1-項集,{Cola, Egg}叫做2-項集。
5、支持度計數:一個項集出現在幾個事務當中,它的支持度計數就是幾。例如{Diaper, Beer}出現在事務 002、003和004中,所以它的支持度計數是3。
6、支持度:支持度計數除於總的事務數。例如上例中總的事務數為4,{Diaper, Beer}的支持度計數為3,所以它的支持度是3÷4=75%,說明有75%的人同時買了Diaper和Beer。
7、頻繁項集:支持度大於或等於某個閾值的項集就叫做頻繁項集。例如閾值設為50%時,因為{Diaper, Beer}的支持度是75%,所以它是頻繁項集。
8、前件和後件:對於規則{Diaper}→{Beer},{Diaper}叫做前件,{Beer}叫做後件。
9、置信度:對於規則{Diaper}→{Beer},{Diaper, Beer}的支持度計數除於{Diaper}的支持度計數,為這個規則的置信度。例如規則{Diaper}→{Beer}的置信度為3÷3=100%。說明買了Diaper的人100%也買了Beer。
10、強關聯規則:大於或等於最小支持度閾值和最小置信度閾值的規則叫做強關聯規則。關聯分析的最終目標就是要找出強關聯規則。
關聯分析方法
Apriori算法
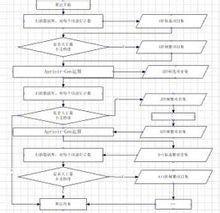 關聯分析
關聯分析Apriori算法是挖掘產生布爾關聯規則所需頻繁項集的基本算法,也是最著名的關聯規則挖掘算法之一。Apriori算法就是根據有關頻繁項集特性的先驗知識而命名的。它使用一種稱作逐層搜尋的疊代方法,k—項集用於探索(k+1)—項集。首先,找出頻繁1—項集的集合.記做L,L用於找出頻繁2—項集的集合L,再用於找出L,如此下去,直到不能找到頻繁k—項集。找每個L需要掃描一次資料庫。
為提高按層次搜尋並產生相應頻繁項集的處理效率,Apriori算法利用了一個重要性質,並套用Apriori性質來幫助有效縮小頻繁項集的搜尋空間。
Apriori性質:一個頻繁項集的任一子集也應該是頻繁項集。證明根據定義,若一個項集I不滿足最小支持度閾值min_sup,則I不是頻繁的,即P(I)<min_sup。若增加一個項A到項集I中,則結果新項集(I∪A)也不是頻繁的,在整個事務資料庫中所出現的次數也不可能多於原項集I出現的次數,因此P(I∪A)<min_sup,即(I∪A)也不是頻繁的。這樣就可以根據逆反公理很容易地確定Apriori性質成立。
針對Apriori算法的不足,對其進行最佳化:
1)基於劃分的方法。該算法先把資料庫從邏輯上分成幾個互不相交的塊,每次單獨考慮一個分塊並對它生成所有的頻繁項集,然後把產生的頻繁項集合併,用來生成所有可能的頻繁項集,最後計算這些項集的支持度。這裡分塊的大小選擇要使得每個分塊可以被放入主存,每個階段只需被掃描一次。而算法的正確性是由每一個可能的頻繁項集至少在某一個分塊中是頻繁項集保證的。
上面所討論的算法是可以高度並行的。可以把每一分塊分別分配給某一個處理器生成頻繁項集。產生頻繁項集的每一個循環結束後.處理器之間進行通信來產生全局的候選是一項集。通常這裡的通信過程是算法執行時間的主要瓶頸。而另一方面,每個獨立的處理器生成頻繁項集的時間也是一個瓶頸。其他的方法還有在多處理器之間共享一個雜湊樹來產生頻繁項集,更多關於生成頻繁項集的並行化方法可以在其中找到。
2)基於Hash的方法。Park等人提出了一個高效地產生頻繁項集的基於雜湊(Hash)的算法。通過實驗可以發現,尋找頻繁項集的主要計算是在生成頻繁2—項集L上,Park等就是利用這個性質引入雜湊技術來改進產生頻繁2—項集的方法。
3)基於採樣的方法。基於前一遍掃描得到的信息,對它詳細地做組合分析,可以得到一個改進的算法,其基本思想是:先使用從資料庫中抽取出來的採樣得到一些在整個資料庫中可能成立的規則,然後對資料庫的剩餘部分驗證這個結果。這個算法相當簡單並顯著地減少了FO代價,但是一個很大的缺點就是產生的結果不精確,即存在所謂的數據扭曲(Dataskew)。分布在同一頁面上的數據時常是高度相關的,不能表示整個資料庫中模式的分布,由此而導致的是採樣5%的交易數據所花費的代價同掃描一遍資料庫相近。
4)減少交易個數。減少用於未來掃描事務集的大小,基本原理就是當一個事務不包含長度為志的大項集時,則必然不包含長度為走k+1的大項集。從而可以將這些事務刪除,在下一遍掃描中就可以減少要進行掃描的事務集的個數。這就是AprioriTid的基本思想。
FP-growth算法
由於Apriori方法的固有缺陷.即使進行了最佳化,其效率也仍然不能令人滿意。2000年,Han Jiawei等人提出了基於頻繁模式樹(Frequent Pattern Tree,簡稱為FP-tree)的發現頻繁模式的算法FP-growth。在FP-growth算法中,通過兩次掃描事務資料庫,把每個事務所包含的頻繁項目按其支持度降序壓縮存儲到FP—tree中。在以後發現頻繁模式的過程中,不需要再掃描事務資料庫,而僅在FP-Tree中進行查找即可,並通過遞歸調用FP-growth的方法來直接產生頻繁模式,因此在整個發現過程中也不需產生候選模式。該算法克服了Apriori算法中存在的問顥.在執行效率上也明顯好於Apriori算法 。
關聯規則生成
得到了頻繁項集,而此時的任務就是在頻繁項集裡面挖掘出大於最小置信度閾值的關聯規則。怎么挖呢?把頻繁項集分成前件和後件兩部分,然後求規則前件→後件的置信度,如果大於最小置信度閾值,則它就是一條強關聯規則。但是把頻繁項集分成前件和後件的情況有很多,我們可以對其進行一些最佳化。
