
簡介
歸一化指數函式,或Softmax函式,實際上是有限項離散機率分布的梯度對數歸一化。因此,Softmax函式在包括 多項邏輯回歸,多項線性判別分析,樸素貝葉斯分類器和人工神經網路等的多種基於機率的多分類問題方法中都有著廣泛套用。特別地,在多項邏輯回歸和線性判別分析中,函式的輸入是從K個不同的線性函式得到的結果,而樣本向量 x 屬於第 j 個分類的機率為:
 歸一化指數函式
歸一化指數函式這可以被視作K個線性函式的Softmax函式的複合。Softmax 回歸模型是解決多類回歸問題的算法,是當前深度學習研究中廣泛使用在深度網路有監督學習部分的分類器 ,經常與交叉熵損失函式聯合使用。
以下是歸一化指數函式代碼實現示例,輸入向量 [1,2,3,4,1,2,3]對應的Softmax函式的值為[0.024,0.064,0.175,0.475,0.024,0.064,0.175]。輸出向量中擁有最大權重的項對應著輸入向量中的最大值“4”。這也顯示了這個函式通常的意義:對向量進行歸一化,凸顯其中最大的值並抑制遠低於最大值的其他分量。下面是使用Python進行函式計算的示例代碼:
邏輯函式
邏輯函式或邏輯曲線是一種常見的S函式,它是皮埃爾·弗朗索瓦·韋呂勒在1844或1845年在研究它與人口增長的關係時命名的。廣義Logistic曲線可以模仿一些情況人口增長(P)的S形曲線。起初階段大致是指數增長;然後隨著開始變得飽和,增加變慢;最後,達到成熟時增加停止。
分類器
分類是數據挖掘的一種非常重要的方法。分類的概念是在已有數據的基礎上學會一個分類函式或構造出一個分類模型(即我們通常所說的分類器(Classifier))。該函式或模型能夠把資料庫中的數據紀錄映射到給定類別中的某一個,從而可以套用於數據預測。總之,分類器是數據挖掘中對樣本進行分類的方法的統稱,包含決策樹、邏輯回歸、樸素貝葉斯、神經網路等算法。分類器的構造和實施大體會經過以下幾個步驟:
選定樣本(包含正樣本和負樣本),將所有樣本分成訓練樣本和測試樣本兩部分。
在訓練樣本上執行分類器算法,生成分類模型。
在測試樣本上執行分類模型,生成預測結果。
根據預測結果,計算必要的評估指標,評估分類模型的性能。
交叉熵
交叉熵(Cross Entropy)是Shannon資訊理論中一個重要概念,主要用於度量兩個機率分布間的差異性信息。語言模型的性能通常用交叉熵和複雜度(perplexity)來衡量。交叉熵的意義是用該模型對文本識別的難度,或者從壓縮的角度來看,每個詞平均要用幾個位來編碼。複雜度的意義是用該模型表示這一文本平均的分支數,其倒數可視為每個詞的平均機率。平滑是指對沒觀察到的N元組合賦予一個機率值,以保證詞序列總能通過語言模型得到一個機率值。通常使用的平滑技術有圖靈估計、刪除插值平滑、Katz平滑和Kneser-Ney平滑。交叉熵可在神經網路(機器學習)中作為損失函式,p表示真實標記的分布,q則為訓練後的模型的預測標記分布,交叉熵損失函式可以衡量p與q的相似性。交叉熵作為損失函式還有一個好處是使用sigmoid函式在梯度下降時能避免均方誤差損失函式學習速率降低的問題,因為學習速率可以被輸出的誤差所控制。
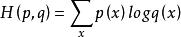 歸一化指數函式
歸一化指數函式