
定義
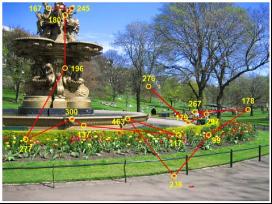 自然場景觀看的眼動軌跡圖
自然場景觀看的眼動軌跡圖一直以來,研究者對於場景(scene )缺乏一個準確而統一的操作定義。Henderson 和 Hollingworth (1999)在其綜述中將場景定義為由空間分布合理的背景和離散的物體構成的真實環境(real-world environment )的連貫圖像。場景包括背景(background)和物體(objects)兩個重要的組成部分。場景中的背景是指寬廣的、靜止的表面和結構,比如:地板、牆壁、天花板和山等都可以成為背景。場景中的物體是指比例較小的不連續物體。對於場景中背景與物體的定義是相對而言的,沒有絕對的標準限定。比如,一個辦公桌在辦公室場景可以作為物體。但是如果視野只關注這張辦公桌,那它也可以作為一個場景,這時辦公桌上的訂書機或電話就成為了這個場景中的物體。大部分研究一般採用正常人視野能看到的環境作為選擇場景的依據。比如校園和操場就是比較好的場景,而一盒火柴和從空中俯瞰城市就不是好的場景。以上介紹的場景更多地被稱作真實場景(real-world scene)
(Henderson, 2005; Henderson, 2007),而在其他的研究中,場景卻有不同的含義。在視覺搜尋的研究中,也把搜尋目標和目標以外的背景定義為場景(Chun, 2000)。為了理解上的方便,在本文中除非特別提及一律採用場景的叫法。
場景知覺一直受到研究者的關注,在19 世紀70 年代就有研究者採用圖片作為刺激材料探討場景的知覺加工問題(Biederman, 1972)。早期的研究由於條件限制,材料多為一些簡單圖片或線條畫(line drawing)(Friedman, 1979; Loftus & Mackworth, 1978)。這也導致了一個問題,就是場景與圖片、線條畫之間有什麼樣的區別和聯繫?正如Henderson 和 Hollingworth(1999)所描述,場景必須包括一定的物體和容納這個物體的背景;但圖片則不同,圖片可能只包括一個簡單的物體,或者只有連續的背景而沒有突出的物體。但是到目前為止,仍沒有比較明確的研究對此進行嚴格的區分。根據已有的文獻來看,早期的很多場景研究使用的刺激材料多為黑白圖片,後來才出現了一些彩色的圖片。但是最近的一些場景研究已經不僅僅局限於二維的圖片材料,而是加入了三維的立體視覺效果。也有一些研究(Hollingworth, 2004; Hollingworth, 2005 )開始嘗試採用視覺模擬和真實的環境來研究場景的知覺問題,這種情況下的場景就更加接近人們的真實生活環境。
刺激材料
 背景提示範式中的刺激材料
背景提示範式中的刺激材料對於場景知覺研究的刺激材料,Henderson 和Ferreira(2004)提出了兩個標準:
第一,材料可以是真實的環境本身,也可以是真實環境的描述形式(form of depiction);
第二,刺激可以是完整的也可以是採取某種方式的降低處理,比如合成。目前,有關場景知覺的研究材料大體有三大類。第一類是簡單的無意義圖形或字母構成的場景信息,比如在其他色塊中構成的背景中搜尋中間帶點的色塊;或者在很多不規則“L”構成的背景中搜尋目標字母“T”(Chun, 2000;Jiang, Olson, & Chun, 2000)。這些研究更多關注的是視覺搜尋中其他物體對搜尋物體的影響,研究者也把它們作為一種最基礎的場景知覺來看待。第二類是物體序列構成的場景,研究者將多個相關或不相關的物體擺放在一起,要求被試搜尋或記憶其中的一個物體,那么其他的物體就對這個目標物構成背景(Hollingworth, 2007;Zelinsky & Loschky, 2005)。
第三類是自然場景,一般採用真實環境的彩色或3D模擬圖片來代表場景(Davenport, 2007; Henderson, 2002; Henderson & Hollingworth, 1999; Hollingworth, 2004)。當目標物體處於自然場景中時,場景的所有布置和其他物體的分布都構成了這個目標物的背景,具體形式見圖1。自然場景比較貼近我們現實生活中見到的各種環境,研究者(Henderson, 2005 )建議把真實的自然場景作為場景研究的刺激材料,提高研究的外部效度。這三種不同的分類也體現了場景知覺研究的不同層次和水平。
認知加工方式
 自下而上加工對場景知覺的影響
自下而上加工對場景知覺的影響場景知覺的加工方式是場景知覺研究中最基本的問題,對不同加工方的探討是研究關注的核心之一。場景知覺的研究屬於知覺研究重要的組成部分,所以,研究者仍然採用認知加工中自上而下(top-down)和自下而上(bottom-up )的加工方式來解釋場景知覺中信息的提取與加工。這兩種加工也被描述為基於刺激的加工(stimulus-based )和知識驅動的加工(knowledge-driven )(Henderson, 2003)。Henderson(2007)把自上而下加工比喻為被“推”(push)的加工,而自下而上的加工是被“拉”(pull)的加工,這種比喻形象地說明了兩種知覺加工方式的差異。場景的自下而上的加工是指由於場景中局部的視覺特性比較突出,而使被試被動地加工這些突出的區域。比如,場景中明亮而且色彩鮮艷的區域一般會受到更早和更多的注視。支持自下而上加工的典型解釋就是“突顯地圖”(saliency map )理論(Castelhano, Wieth, & Henderson, 2007;Torralba, Oliva, Castelhano, & Henderson, 2006; Underwood & Foulsham, 2006;Underwood, Foulsham, van Loon, Humphreys, & Bloyce, 2006)。這種理論認為,場景中的顏色、密集度、對比度和邊際朝向(edge orientation )等會造成一些區域突出於其他的周圍區域,這些突出的區域會吸引人的注意,在視覺加工中會比較早地被注意和加工。自下而上的加工。
而自上而下的加工則是指由於受到先前認知加工和知識經驗的影響,人會主動加工場景中一些特定的信息。比如:當要求被試從客廳場景搜尋鐘錶獲得時間時,被試會激活相關的知識經驗,根據任務的要求主動搜尋目標物體而不管場景中其他的區域是否鮮艷和明亮。自上而下的加工強調已有知識經驗的作用,這些知識經驗包括對先前場景信息的短時記憶和情景記憶,存貯在長時記憶中類似場景的有關視覺、空間和語義信息,以及被試的目的和計畫等。就短時記憶而言,剛才看到過的一幅圖片,當再看這幅圖片或者類似圖片時,我們會積極關注我們感興趣的區域,或者認為信息豐富的區域。長時記憶中也包含著一些場景的信息,比如,廚房場景一般都會包括灶具,辦公桌的場景一般都會包括電腦。這些信息會影響我們對場景的知覺和加工。場景記憶的研究發現,對場景的知覺圖式和原有經驗在場景的編碼和記憶中具有重要的作用(Pezdek & Maki, 1988)。
由於圖像本身的特性要比知識經驗更容易量化和操作,所以很多的研究都傾向於採用自下而上的加工方式來建立視覺加工的計算模型或量化的預測。比較典型的代表就是突顯地圖模型(Henderson, 2007; Humphreys & Bloyce, 2006; Underwood & Foulsham, 2006; Underwood, Foulsham, van Loon, Humphreys, & Bloyce, 2006)。但是,場景的加工往往不是獨立的加工能夠完成的。場景知覺研究中有關背景對場景物體識別的結果發現,我們對場景的知覺可能受到兩種加工的互動影響,無論是場景中突顯的物體,還是場景中的模糊背景會通過相互的作用影響場景的知覺,所以很難用一種單一的加工方式來解釋我們對真實複雜場景的知覺(Davenport & Potter, 2004; Henderson & Hollingworth, 2002; Underwood, Templeman, Lamming, & Foulsham, 2008)。因此,也出現了將兩者結合的背景引導模型(Contextual Guidance Model )(Torralba, Oliva, Castelhano, & Henderson, 2006)。
研究範式
場景知覺研究不同於基礎的視覺研究,場景中包含的信息比較多,對於實驗變數的控制比較困難,所以研究者設計了不同的實驗範式來探討場景的知覺。根據已有研究中所採用的實驗任務不同,對於場景知覺的研究大體上有5種常用的實驗範式:眼動(Eye Movement)、背景提示(Contextual Cueing)、物體覺察(Object Detection)、變化覺察(Change Detection )和點線索追隨(Follow-The-Dot)。這幾種範式雖然名稱和叫法各不相同,但是彼此之間也存在一定的重合和繼承,下面將分別對這些研究範式進行簡單的介紹。
眼動範式
由於眼動跟蹤技術允許被試在自由的狀態下觀看場景,所以很多的場景知覺研究採用眼動跟蹤的方法。這些研究可以從兩個方面來進行梳理。首先,從眼動的指標來看,對於場景知覺的眼動研究主要涉及三個方面,即場景知覺過程中眼睛的注視位置、注視時間和眼跳及信息整合(Henderson & Hollingworth, 1999)。眼動範式主要關注前兩個方面的眼動控制問題,即場景知覺過程中眼睛注視哪裡,注視多久。對場景知覺的信息整合和眼跳,需要結合其他的任務(比如:變化探測)進行研究。對場景知覺的眼動研究發現,場景知覺的加工時間是對場景注視的空間和時間分布的函式。其次,眼動研究還會結合變化覺察、物體識別(object identification )和場景記憶(scene memory )等實驗任務,探討場景知覺過程中局部信息提取、場景中的物體識別以及把物體和場景信息進行編碼存入短時或長時記憶等問題(Henderson, 2007)。
眼動範式一般給被試呈現場景刺激,要求被試自由觀看場景,在被試觀看過程中記錄被試的眼動信息,然後對眼動數據進行分析。刺激呈現的時間從幾百毫秒到幾秒不等。比較早的採用眼動範式研究場景知覺的是Loftus 和Mackworth(1978)的研究,他們給被試呈現兩組線條畫,一組為場景中的物體與場景關係一致,比如拖拉機出現在農場場景中;一組為場景中物體與場景關係不一致,比如章魚出現在農場場景中。研究發現,物體與場景的關係是否一致(即物體出現在該場景中是否合理)會影響被試對場景中物體的眼動注視。相比一致的物體而言,被試對於那些與場景不一致的物體給予了更多的注視,而且注視的持續時間也更長。對目標物體的注視持續時間被認為是物體識別速度的重要指標。由於能夠即時地測查被試對場景知覺的過程性信息,所以後來的很多研究都採用眼動範式來研究場景知覺,並且取得了很多有意義的結果(Boyce & Pollatsek, 1992; De Graef, Chistiaens, & d’Ydewalle, 1990;Friedman, 1979;Underwood, Templeman, Lamming, & Foulsham, 2008)。
雖然眼動能夠獲得很多過程性信息,但是眼動範式也有它的局限性。由於眼動很容易受到其他內部和外部因素的影響,所以必須進行嚴格的實驗控制,排除無關變數的干擾,才能很好地解釋自變數的影響作用。此外,對場景知覺的眼動研究中十分重視第一次注視持續時間,把它作為場景中物體識別的重要指標(De Graef, Chistiaens, & d’Ydewalle, 1990)。但是,至今還沒有足夠的證據證明第一次注視持續時間反映的是物體識別時間,還是隨後的其他加工。除非有進一步的證據或者其他方式的輔助,否則單獨靠眼動範式不能很好地解釋對場景的知覺和加工。
背景提示範式
 背景提示範式中的刺激材料
背景提示範式中的刺激材料在知覺場景時,背景提供了豐富的信息。比如:背景可以提供場景中特定物體可能的位置信息、大小信息以及物體與場景的關係信息等。對於視覺背景信息的加工能夠為我們更有效地了解所看到的世界提供良好的基礎。Marvin Chun(2000) 在綜述中比較詳細地介紹了有關背景提示範式的一些情況。背景提示範式主要是基於視覺搜尋研究發展而來,目的在於探討場景背景對目標搜尋的影響。研究要求被試在由不規則L 構成空間背景中搜尋目標字母T,同時判斷字母T 的傾斜方向。實驗控制了背景的布局差異,一種情況中,T 出現方向變化,但是其背景中的干擾項L 的空間布局和顏色沒有任何變化,這種情況被稱為舊背景組。另外一種情況被稱為新背景組,在這組中仍然變化T 的方向,但是其出現的背景中的干擾項L 也進行了相應的空間位置變化。結果發現,舊背景組的反應時要低於新背景組。這種重複出現的背景布局能夠提高被試的反應速度,具有提示的作用,被稱為背景提示(contextual cueing)。有趣的是,當實驗結束後,要求被試對新舊背景組進行再認時,兩組被試間沒有差異,判斷的水平接近猜測水平。研究者認為被試對這種不變的舊背景的學習是內隱的,不需要有意識的編碼和記憶(Chun & Jiang, 1998)。
隨後,研究者(Chun & Jiang, 1999 )把原來的空間背景提示改變為物體的相互關係提示,實驗的刺激形式如圖3 下圖所示。目標物為垂直方向對稱的圖形,其他不以垂直方向對稱的圖形為干擾項,構成背景空間。實驗為了更好地排除其他干擾,反應結束後,原來的所有刺激圖形被一些探測字母替代,要求被試報告目標圖形出現位置的字母。實驗仍然分為新舊兩組,舊組為目標圖形與一些特定的干擾圖形成對出現;新組為目標圖形和干擾圖形的出現是隨機分派的。結果發現,被試對目標圖形與干擾圖形成對一致出現的刺激反應時更短。在此基礎上,Chun 等採用動態事件提示(dynamic event cueing)和3D 刺激材料作為實驗材料,得出了一致的結果(Chua & Chun, 2003; Chun & Jiang, 1999), 即搜尋的目標物與特定背景的重複出現會利於視覺搜尋。背景提示範式從總體上來說是支持視覺的自上而下加工的,它的理論假設認為視覺的背景信息可以促進場景的加工。
A:目標物位置的線索提示在場景消失後
B:目標物位置的線索提示在場景出現前
Brockmole和Henderson等(Brockmole, Castelhano, & Henderson, 2006;Brockmole, Hambrick, Windisch, & Henderson, in press;Brockmole & Henderson, 2006a )把這種範式套用到真實場景知覺中。真實的場景不同於隨機排列的字母和圖形,它們是連貫的,信息豐富的,背景與目標間聯繫也更加複雜。這種情況下,背景提示是如何對場景加工起作用的?背景提示是來自於場景的總體信息還是局部信息?這些都是研究者關心的問題。研究者首先把T 和L 作為目標物嵌入到真實場景中,目標物在場景中出現的位置是固定的。在新背景組中目標物出現的場景每次都是變化的,舊背景組則反覆呈現8 個場景。結果發現,舊背景組對目標字母的搜尋時間更快。與Chun 的結果不同的是,對被試進行新舊場景背景的再認發現,被試對舊場景背景的再認好於新場景背景,且正確率高於猜測水平(Brockmole & Henderson, 2006a)。相對隨機的字母和無意義圖形而言,場景更加的形象和具有意義,其記憶更多的是外顯記憶。這些研究結果也得到了眼動數據的支持,發現被試對反覆呈現的背景組的目標字母注視更少(Brockmole & Henderson, 2006b)。此外,Brockmole等通過變化場景中整體和局部背景布局來操縱不同的背景提示,考查了整體和局部背景提示對目標字母視覺搜尋的影響。結果發現,在真實場景背景條件下,背景提示的促進作用主要來自整體的背景提示(Brockmole, Castelhano, & Henderson, 2006)。此外,Brockmole 等(in press)採用象棋專家和新手作為被試,要求被試搜尋國際象棋棋譜中的目標字母。結果發現,在重複呈現情況下,有意義棋局對搜尋的促進作用專家要比新手高四倍。無意義棋局對專家的搜尋促進作用減半。
物體覺察範式
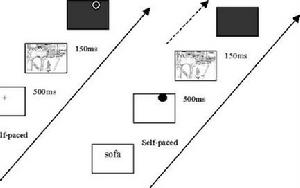
 變化探測任務示例
變化探測任務示例採用了這種實驗範式。在其隨後的研究中完善了這物體覺察範式把場景中目標物體的覺察準確性種範式,並將其命名為物體覺察範式,而且得出了作為物體覺察與否的指標。Biederman(1972)最早有意義的研究結果(Biederman, 1981; Biederman, Mezzanotte, & Rabinowitz, 1982)。經典的物體覺察範式見圖4。實驗首先給被試呈現目標物體的名稱,然後呈現一個注視點,接著呈現場景刺激,然後是一個由無意義線條構成的掩蔽,在掩蔽上有一個圓圈提示目標物體出現的位置,最後讓被試做是否的判斷並記錄其反應時。目標物位置提示可以出現在場景出現前也可以在其後,如果位置提示出現在場景呈現前,則反應時的記錄從場景呈現結束後開始。但是,經典的物體覺察範式受到了一些批評和質疑。首先,由於混亂場景引入新的輪廓,導致正常場景和混亂場景在視覺方面的複雜性是不對等的,使得實驗結果的真實性受到懷疑。其次,被試可以根據正常場景來編碼物體的位置關係,從而選擇那些可能在提示位置出現的物體,而這在混亂場景中很難做到。
針對經典範式的不足,研究者(Boyce, Pollatsek, & Rayner, 1989;Hollingworth & Henderson, 1998 )對實驗範式進行了改進。其中一點就是採用了信號檢測的方法,即通過測量的敏感性體現實驗中自變數對因變數的影響。雖然信號檢測方法能夠控制一些反應偏向,但是實驗還是不能把反應偏向從敏感性測量中去除。當研究者改進了設計來控制被試的反應偏向後,卻沒有發現先前的實驗結果。此外,Hollingworth 和Henderson(1998)還對目標物體出現前給予位置提示提出了質疑。認為反應前對要出現的目標物給予位置提示會導致實驗結果出現人為的偏向。他們改進了實驗範式,把對目標物體呈現位置的提示放在場景呈現之後,卻發現了與先前研究不同的結果。他們把這種改進後的實驗呈現命名為場景後強迫判別(post-scene forced-choice discrimination procedure )。
變化覺察範式
變化覺察範式與物體覺察類似,都是對場景中的物體進行覺察,但是二者在變化方式上存在差異,所以把它作為一種單獨的方式介紹。變化覺察的基本範式是給被試看一張場景圖片,在觀看過程中的某一時間,將場景圖片中的一個具體物體改變,考察被試在之後的觀看過程中能不能探測到前後的變化。由於這種變化只是圖片中的一個物體或細節發生了變化,場景的其他成分與原來一致,所以通過覺察反應判斷被試是否覺察到了該變化,即可判斷是否對場景有正確的視覺記憶。根據不同的研究目的,變化覺察範式有兩種不同的形式:閃爍範式(flicker paradigm)和眼動控制的變化覺察範式。
閃爍範式主要探討在眼跳過程中對場景的知覺和表征。研究(Henderson, 1997 )發現人的視覺系統在眼跳過程中不能保持詳細的視覺表象。Rensink 等人(1997)最早採用這種範式來考查人們在場景知覺過程中的變化視盲(change blindness)現象。具體形式為呈現場景A 240ms,然後呈現灰屏80ms, 接下來按同樣方式呈現改變後的場景A’,然後一直反覆地呈現這兩個場景60s,直到被試按鍵報告發現真正的差異停止實驗。呈現灰屏的目的在於干擾視網膜對信息的暫時停留。場景A 和A’除了場景中單個物體存在明顯的變化外(比如:顏色改變、某個部分缺失等),其他背景信息均相同。結果發現被試很難發現前後場景的差異。隨後的實驗中,Rensink 等改變了呈現形式,仍有很大一部分被試不能發現前後場景的變化。研究認為通過眼跳很難保持視覺表征的信息,除非積極地投入注意並且進行編碼。這種對場景的變化視盲現象在Levin和Simons(1997)的動態研究中得到了進一步的證實。
已有的變化覺察範式存在一個邏輯前提,即被試在變化發生之前看過這個物體。但事實上,由於場景觀看不像文字閱讀那樣有著固定的順序,被試在觀看中可以按照任意的方式進行,所以就無法判斷在變化發生前被試是否注視過這個物體。而且,閃爍範式的眼跳受到了人為灰屏的干擾,與正常觀看中的眼跳存在差異。研究者(Hollingworth & Henderson, 2002 )針對此問題,改進了變化覺察範式。他們引入了眼動跟蹤技術,根據被試的注視情況來確定何時變化目標物,分成注視後變化和注視前變化,具體形式見圖5。圖中B 區為中央區域,A 區為目標區域,它包含著目標物。C 區是變化啟動區域,這個區域一般都設定得離A 區較遠,這保證了被試在看這個區域時,通過邊緣視覺無法覺察到A 區的變化。
在場景呈現之前,要求被試注視螢幕中央的點,保證被試最初的注視點在中央區域。在注視後變化中,被試對目標物區域A 的注視時間超過90ms 後,當注視點離開該區域時就會激活變化啟動區域C, 之後只要被試的注視點到達區域C 時,就會將區域A 中的物體變化成為另一物體。然後,考察被試在之後的觀看中再次注視區域A 時有沒有發現這個物體的變化(Rensink, 2000),或者在A 區的平均注視持續時間有沒有顯著地長於其他區域(Brockmole & Henderson, 2005)。此範式保證了被試在物體變化之前對該物體進行了注視。在注視前變化中,當被試的注視點離開了中央區域B 時,啟動變化區域C 就被激活。這時,如果在沒有注視A 區之前先注視了C 區,只要被試的注視點到達區域C 時,就會將區域A 中的物體變化成為另一物體。然後,考察當被試在之後的觀看中注視到A 時有沒有發現變化。這種情況下,被試在物體變化前沒有注視過該物體,所以不能發現A 的變化。因此,可以將這種情況作為基線水平,這樣可以去除猜測或經驗推理等對變化覺察的影響。
後來Henderson 等人(Henderson, Brockmole, & Gajewski, 2008; Henderson & Hollingworth, 2003 )進一步完善了眼動控制的變化覺察範式,使得這種範式更好地服務於場景知覺中物體變化覺察的研究。採用眼動控制的變化覺察範式得出了與閃爍範式類似的結果,被試仍然很難發現前後場景的變化。以上的研究結果說明無論眼跳還是注視中,局部的動態信息如果在輸入過程中受到干擾或禁止,那么場景的變化很難被覺察到。
點線索追隨範式
 場景知覺
場景知覺點線索追隨範式是結合原來物體覺察判斷和眼動注視的改進形式,目的是為了更好地保證實驗的內部效度。在介紹點線索追隨前,先簡單介紹迫選再認任務(forced-choice recognition)。迫選再認任務在原來物體覺察的基礎上發展而來。任務首先給被試看一個包含著很多物體的場景一段時間,看完之後呈現兩個再認場景,這兩個再認場景和原來看過的場景是一樣的,但其中有一張場景中的某個物體發生了變化,讓被試判斷,哪個場景中的那個物體和原來的物體一樣。這樣通過被試反應的正確率就可以判斷被試對物體的視覺記憶的成績(Hollingworth, 2003;Hollingworth & Henderson, 2002)。
迫選再認任務是在看完一個場景之後對目標物進行迫選再認,但是由於場景中包含著多個物體,那么必然有的物體先看到,有的物體後看到,有的物體注視時間短,有的物體注視時間長。因此無法準確判斷目標物與測試之間的時間間隔,無法考察視覺記憶的保持時間問題。針對這種情況,Hollingworth(2004)設計了點線索追隨範式,來研究場景視覺短時記憶的保持和信息加工問題。該範式在呈現場景過程中,有一個點線索會依次指向各個物體,要求被試在觀看過程中,眼睛追隨點線索進行注視,即點線索在哪個物體上,被試就看哪個物體。這樣就可以保證場景中所有的物體都被注視到,並且保證加工的時間基本一致。最重要的是,可以操縱某個目標物體是在什麼時間被注視,通過計算目標物與測試之間間隔了多少個物體(即點線索指向了多少個物體)就可以推算出目標物注視到測試之間的時間間隔。結果發現,物體的視覺記憶在間隔0~4 個物體的情況下,成績不斷下降,但間隔4 個物體與間隔10 個物體的成績差異不顯著,此時的正確率保持在80%左右。根據這一結果,研究者提出視覺記憶的有關理論假設,即視覺記憶可以保持相當長的時間,且容量較大。
意義
 場景知覺
場景知覺視知覺研究是基礎心理學和實驗心理學研究的重點內容,隨著技術的進步和研究的深入,很多研究者越來越關注人是如何知覺和加工周圍真實的場景環境的。以John M. Henderson 等人(Henderson & Hollingworth, 1999 )為代表的一些研究者,在基礎視覺研究的基礎上採用眼動等技術對自然場景知覺(scene perception )展開了相關的研究。Henderson 和Hollingworth(1999)把人類的視覺研究分為三個水平:低水平的視覺(low-level vision or early vision),中間水平的視覺(intermediate-level vision) 和高水平的視覺(high-level vision)。低水平的視覺研究涉及視覺圖像的深度、顏色、紋理結構等視覺物理特徵的提取,以及圖像表征的形成;中間水平的視覺研究涉及對物體外形、輪廓和空間關係的提取,這種提取不受物體名稱和意義的影響;高級水平的視覺研究關注從視覺表徵到物體的意義、知覺和認知的互動影響、視覺信息的短時記憶以及物體與場景的識別。而在高級視覺研究中,有關場景知覺的研究成為一個備受關注的領域(Henderson, 2005; Henderson, 2007)。Henderson 等在2005 年第6 期的Visual Cognition 上專門組織了一期內容(special issue on real-world scene perception)來探討有關場景知覺的研究問題。
