
簡介
 “推土機”處理器
“推土機”處理器AMD“推土機”是代號bulldozer(推土機)的全新架構,“推土機”架構最早是在2007年年中提出的,當“推土機”處理器
時計畫採用45nm工藝,2009年上半年發布,競爭IntelNehalem,不過可能是因為45nmK10Phenom系列進展不順,新架構被推遲了。在AMD的發展規劃中在2009-2010年間都是45nmPhenom打天下,32nm工藝產品要到2011年才會發布,也就是“推土機”架構。“推土機”是AMD徹底重新設計的核心,將成為AMD下一代高性能處理器技術,用於客戶端和伺服器領域,相比於Opteron6100系列會增加33%的核心、大約50%的性能。作為嶄新一代的處理器構架,AMD“推土機”將採用32nmSOI工藝,這讓“推土機”相比“Magny-Cours”皓龍處理器可以在不增加功耗的前提下增加33%的核心數量、增加50%的吞吐量。與AMD之前所有處理器都有所不同的是,“推土機”採用了“模組化”的設計,每個“模組”包含兩個處理器核心,這有些像一個啟用了SMT的單核處理器。每個核心具有各自的整數調度器和四個專有的管線,兩個核心共享一個浮點調度器和兩個128位FMAC乘法累加器。
型號規格
桌面版本
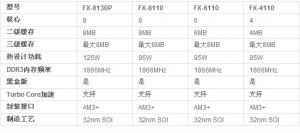 型號規格
型號規格推土機家族的桌面版本“贊比西河”(Zambezi)將分為三個子系列,分別是八核心的FX-8000、六核心的FX-6000、四核心的FX-4000。首發型號四款,包括兩款八核心、一款六核心和一款四核心;到年底的時候還會追加另外四款,主要是速度上的提升。贊比西河都採用GLOBALFOUNDRIES32nmSOI工藝製造,SocketAM3+封裝接口,首批四款都支持TurboCore動態加速,而且全部屬於BlackEdition黑盒版,開放超頻,記憶體支持均為雙通道DDR3,頻率最高達到了1866MHz。
高端版本
高端版本“FX-8130P”為四模組八核心,二級快取8MB(每模組2MB),三級快取最大8MB,熱設計功耗125W;之下是同樣八核心的“FX-8110”,應該是頻率略有降低,熱設計功耗也降至95W,其他相同。 六核心是“FX-6110”,三模組,二級快取相應地減至6MB,四核心則是“FX-4110”,雙模組,二級快取4MB,熱設計功耗都是95W。推土機架構
Bulldozer(推土機)架構中的另一個新元素就是採用了基於集群的多執行緒技術。Bulldozer的核心模組是一個可以同時運行兩個執行緒的處理組件,兩個核心可以執行兩個完全不會相互干擾的執行緒,有點類似於Intel的雙核處理器的超執行緒奇數。
多簇式多執行緒技術
儘管雙核、多執行緒和Bulldozer線上程並行執行方面是相同的,但是核心的分區卻截然不同。多執行緒就是在一個單個的處理核心內同時運行多個工作執行緒的技術,和CMP晶片多處理器技術不同,後者是通過集成多個處理核心的方式讓系統的處理能力提升,現在主流的多喝處理器都是用了CMP技術,而像Pentium4、Corei7這樣的處理器帶的“超執行緒技術”則屬於多執行緒奇數,而Bulldozer是基於集群化多執行緒架構,Cluster-BasedMulti-threading:CMT,也稱多簇式多執行緒技術。
設計集群化
在Intel的超執行緒方案中,採用的是複製處理器架構狀態的方法來實現超執行緒,核心內部並沒有增設一套額外的硬體執行單元來處理多執行緒,只是增加了處理器中存儲執行緒有關數據的單元數量,病在硬體執行單元空閒時將這些數據送往其中處理,一邊增加處理器執行單元的利用率。這種設計有一定的缺點,比如它只使用了一個指令視窗來負責兩個執行緒的調度、執行和引退,效率並不高。這就像是生產線只有一名管理調度人員,一個人很難同時處理兩個任務,這樣有時候便會出現生產線故障,而處理器在碰到這種情況時性能澤輝出現明顯的下降。相對於傳統超執行緒或雙核技術,Bulldozer這種設計集群化架構的理念是讓雙核模組在多執行緒運算中更高效。Bulldozer每一個模組中加入了額外的執行單元,每一個模組都具備可以將一個大任務細分為多個並行任務的能力,這些生產線可以按需要任意整合,不會對整個裝配線的效能造成影響。因此CMT技術的效能要高於傳統的多執行緒方案。根據AMD介紹,單個“推土機模組”可以達到80%左右的多執行緒性能提升,而且所用的電晶體數目似乎並不比Intel的超執行緒奇數更多,這是一個相當鼓舞人心的成就。
新工藝及新技術
Turbo Core全核心加速技術
TurboCore技術主要是指對於一些沒有完全消耗到最大程度的工作負載,去加快時鐘速度。在多種不同工作負載上,使用了TurboCore可以最大增加500兆赫茲的性能。最重要的一點,TurboCore加速指的是所有核的加速,和有些核加速技術明顯不同,以往的核加速技術可能需要關閉一些核,只對部分核進行加速。採用TurboCore技術,最多可以使所有核增速500兆赫茲,如果再關閉一些核運轉的情況下,加速將會超過500兆赫茲。同時我們還對記憶體控制器進行了進一步最佳化,從而提高記憶體的吞吐量。除了每個核心獨享4個整數計算管線,在浮點運算上,“推土機”採用了“FlexFP”技術,兩個核心共享一個浮點調度器和兩個128位FMAC乘法累加器,可以進行組合,每個時鐘周期可以完成兩次64位雙精度計算或4次32位單精度計算。如果一個核心沒有進行浮點運算,那么另一個核心可以占用這兩個128位的FMAC,在一個時鐘周期完成4次雙精度運算或8次單精度計算,AMD將其命名為AVX模式。這種技術保證了“推土機”的浮點運算能力,在高性能計算中並不會因為“共享”而犧牲性能。
新接口和新工藝
推土機處理器將採用Socket AM3+接口,941個針腳,不同於目前938個針腳的SocketAM3接口,其好處是可以支持DDR3-1866記憶體和高級節能技術,而且AM3+將是AM3+將是AMD的最後一代針腳柵格陣列(PGA)封裝,之後將改用觸點柵格陣列(LGA),等到Fusion融合處理器降臨的時候就會使用LGAAF1新接口,觸點多達1591個,支持DisplayPort1.2標準、PCI-E3.0規範(32條信道)、四通道記憶體。
加強型記憶體控制器
8年前AMD首家推出集成記憶體控制器,根據AMD在這一領域的經驗和非常好的技術,又在這一代產品中全面提升了記憶體控制器的性能。首先對記憶體控制器在效率方面進行了針對性的重新設計和完善,因此實現30%的記憶體性能提升。在提升30%性能基礎上,讓記憶體支持1600MHz頻率,可以獲得額外20%的性能。兩項加起來,可以實現記憶體控制器50%吞吐量提升同時支持AVX指令和SSE指令
FLEXFP是AMD至今為止最有創新意義的浮點計算技術,每一個模組都有一個FLEXFP進行浮點運算。如果使用傳統128位編碼,意味著每個核會有單獨的浮點運算單元。與友商相比,如果在128位編碼前提下,AMD所執行的數量多一倍。如果是256位AVX編碼,Bulldozer可以把兩個浮點運算單元放在一起執行。所以在256位編碼執行模式下,與友商比較,執行的數量是一樣的。但是Bulldozer有一個非常大的優勢,就是可以同時執行256位AVX指令和SSE指令。而友商就不能做到這點,他們只能在AVX或SSE中選擇其一,這樣的優勢能夠讓Bulldozer在高性能計算、媒體編解碼以及在一些技術型運算方面有更高的性能。更先進的電源管理技術
每個模組內第二個整數核心所需要的電路只占總核心面積的12%,從晶片級別上講這只會給整個核心增加5%的電路。更多的核心、更少的空間,這顯然有利於提高單位功耗、單位成本的性能。能耗大小是由被通電時鐘數量決定的,它取決於執行一個普通指令(運算)需要讓多少電晶體處於通電狀態。在最大時鐘供電的百分比下,正常套用狀態和閒置狀態下,Bulldozer都具有非常好的能耗表現。同時在各能耗單位上進行了最佳化,可以在各種單位下進行電源關閉。高性能運算能耗之所以高,主要是由於浮點運算,而一般套用運算主要是在執行單元消耗得最高。同時還有閒置狀態下,AMD的技術可以做到對於那些完全用不著的核,把電源完全關閉。去年AMD產品有一個大轉型,AMD推出了新插槽,2011年推出的推土機可以使用2010年的插槽。而友商為推出新平台,同時推出了新插槽,這也使得AMD更占優勢。
