
基本概念
 pci Express
pci ExpressPCI Express的接口根據匯流排位寬不同而有所差異,包括X1、X4、X8以及X16(X2模式將用於內部接口而非插槽模式)。較短的PCI Express卡可以插入較長的PCI Express插槽中使用。PCI Express接口能夠支持熱拔插,這也是個不小的飛躍。PCI Express卡支持的三種電壓分別為+3.3V、3.3Vaux以及+12V。用於取代AGP接口的PCI Express接口位寬為X16,將能夠提供5GB/s的頻寬,即便有編碼上的損耗但仍能夠提供4GB/s左右的實際頻寬,遠遠超過AGP 8X的2.1GB/s的頻寬。
PCI Express規格從1條通道連線到32條通道連線,有非常強的伸縮性,以滿足不同系統設備對數據傳輸頻寬不同的需求。例如,PCI Express X1規格支持雙向數據傳輸,每向數據傳輸頻寬250MB/s,PCI Express X1已經可以滿足主流聲效晶片、網卡晶片和存儲設備對數據傳輸頻寬的需求,但是遠遠無法滿足圖形晶片對數據傳輸頻寬的需求。因此,必須採用PCI Express X16,即16條點對點數據傳輸通道連線來取代傳統的AGP匯流排。PCI Express X16也支持雙向數據傳輸,每向數據傳輸頻寬高達4GB/s,雙向數據傳輸頻寬有8GB/s之多,相比之下,廣泛採用的AGP 8X數據傳輸只提供2.1GB/s的數據傳輸頻寬。
 pci Express
pci Express儘管PCI Express技術規格允許實現X1(250MB/秒),X2,X4,X8,X12,X16和X32通道規格,但是依形式來看,PCI Express X1和PCI Express X16將成為PCI Express主流規格,同時晶片組廠商將在南橋晶片當中添加對PCI Express X1的支持,在北橋晶片當中添加對PCI Express X16的支持。除去提供極高數據傳輸頻寬之外,PCI Express因為採用串列數據包方式傳遞數據,所以PCI Express接口每個針腳可以獲得比傳統I/O標準更多的頻寬,這樣就可以降低PCI Express設備生產成本和體積。另外,PCI Express也支持高階電源管理,支持熱插拔,支持數據同步傳輸,為優先傳輸數據進行頻寬最佳化。
在兼容性方面,PCI Express在軟體層面上兼容的PCI技術和設備,支持PCI設備和記憶體模組的初始化,也就是說驅動程式、作業系統無需推倒重來,就可以支持PCI Express設備。PCI Express是新一代能夠提供大量頻寬和豐富功能以實現令人激動的新式圖形套用的全新架構。PCI Express可以為頻寬渴求型套用分配相應的頻寬,大幅提高中央處理器(CPU)和圖形處理器(GPU)之間的頻寬。對最終用戶而言,他們可以感受影院級圖象效果,並獲得無縫多媒體體驗。
PCI Express的主要優勢就是數據傳輸速率高,目前最高的16X 2.0版本可達到10GB/s,而且還有相當大的發展潛力。PCI Express也有多種規格,從PCI Express 1X到PCI Express 16X,能滿足一定時間內出現的低速設備和高速設備的需求。PCI-Express最新的接口是PCIe 3.0接口,其比特率為8GT/s,約為上一代產品頻寬的兩倍,並且包含發射器和接收器均衡、PLL改善以及時鐘數據恢復等一系列重要的新功能,用以改善數據傳輸和數據保護性能。像INTEL、IBM、、LSI、OCZ、、三星(計畫中)、SanDisk、STEC、SuperTalent和東芝(計畫中)等,而針對海量的數據增長使得用戶對規模更大、可擴展性更強的系統所套用,PCIe 3.0技術的加入最新的LSI MegaRAID控制器及HBA產品的出色性能,就可以實現更大的系統設計靈活性。
PCI Express採用串列方式傳輸Data。它和原有的ISA、PCI和AGP匯流排不同。這種傳輸方式,不必因為某個硬體的頻率而影響到整個系統性能的發揮。當然了,整個系統依然是一個整體,但是我們可以方便的提高某一頻率低的硬體的頻率,以便系統在沒有瓶頸的環境下使用。以串列方式提升頻率增進效能,關鍵的限制在於採用什麼樣的物理傳輸介質。人們普遍採用銅線路,而理論上銅這個材質可以提供的傳輸極限是10 Gbps。這也就是為什麼PCI Express的極限傳輸速度的答案。
因為PCI Express工作模式是一種稱之為“電壓差式傳輸”的方式。兩條銅線,通過相互間的電壓差來表示邏輯符號0和1。以這種方式進行資料傳輸,可以支持極高的運行頻率。所以在速度達到10Gbps後,只需換用光纖(Fibre Channel)就可以使之效能倍增。
PCI Express是下一階段的主要傳輸匯流排頻寬技術。然而,GPU對匯流排頻寬的需求是子系統中最高的,顯而易見的是,視頻在PCI Express應占有一定的分量。顯然,PCI Express的提出,並非是匯流排形式的一個結束。恰恰相反,其技術的成熟仍舊需要這個時間。當然了,趁這個時間,那些晶片、主機板、視頻等廠家是否能出來支持是PCI Express發展的關鍵。
PCI-Express是最新的匯流排和接口標準,它原來的名稱為“3GIO”,是由英特爾提出的,很明顯英特爾的意思是它代表著下一代I/O接口標準。交由PCI-SIG(PCI特殊興趣組織)認證發布後才改名為“PCI-Express”。這個新標準將全面取代現行的PCI和AGP,最終實現匯流排標準的統一。它的主要優勢就是數據傳輸速率高,目前最高可達到10GB/s以上,而且還有相當大的發展潛力。PCI Express也有多種規格,從PCI Express 1X到PCI Express 16X,晶片組。當然要實現全面取代PCI和AGP也需要一個相當長的過程,就象當初PCI取代ISA一樣,都會有個過渡的過程。
起源和現狀
 WY576-F2 Intel82576
WY576-F2 Intel825762001年春季的IDF上Intel正式公布PCI Express,是取代PCI匯流排的第三代I/O技術,也稱為3GIO。該匯流排的規範由Intel支持的AWG(Arapahoe Working Group)負責制定。2002 年4月17日,AWG正式宣布3GIO 1.0規範草稿制定完畢,並移交PCI-SIG進行審核。開始的時候大家都以為它會被命名為Serial PCI(受到串列ATA的影響),但最後卻被正式命名為PCI Express。2006年正式推出Spec2.0(2.0規範)。
PCI Express匯流排技術的演進過程,實際上是計算系統I/O接口速率演進的過程。PCI匯流排是一種33MHz@32bit或者66MHz@64bit的並行匯流排,匯流排頻寬為133MB/s到最大533MB/s,連線在PCI匯流排上的所有設備共享133MB/s~533MB/s頻寬。這種匯流排用來應付音效卡、10/100M網卡以及USB 1.1等接口基本不成問題。隨著計算機和通信技術的進一步發展,新一代的I/O接口大量湧現,比如千兆(GE)、萬兆(10GE)的乙太網技術、4G/8G的FC技術,使得PCI匯流排的頻寬已經無力應付計算系統內部大量高頻寬並行讀寫的要求,PCI匯流排也成為系統性能提升的瓶頸,於是就出現了PCI Express匯流排。PCI Express匯流排技術在當今新一代的存儲系統已經普遍的套用。PCI Express匯流排能夠提供極高的頻寬,來滿足系統的需求。
PCI-E 3.0規範也已經確定,其編碼數據速率,比同等情況下的PCI-E 2.0規範提高了一倍,X32連線埠的雙向速率高達32Gbps。
誕生和概念
雖然,除了3D顯示卡以外,直到現在還沒有哪個計算機配件脫離PCI匯流排的束縛另起爐灶,諸如千兆網卡、音效卡、RAID卡等都還在循規蹈矩的奉行著PCI規範,但,PC技術的快速發展已經讓PCI匯流排越來越顯現出不足,尤其是最近的千兆網路以及視頻套用等外設,會使PCI可憐的133MB/s頻寬難以承受,當幾個類似外設同時滿負荷運轉,PCI匯流排幾近癱瘓。不但如此,隨著技術的不斷進步,PCI電壓難以降低的缺陷越來越凸出出來,PCI規範已經成為PC系統的發展桎梏,徹底升級換代迫在眉睫。
到了2001年,在Intel春季的IDF上,Intel正式公布了旨在取代PCI匯流排的第三代I/O技術,該規範由Intel 支持的AWG(Arapahoe Working Group)負責制定,並稱之為第三代I/O匯流排技術(3rd Generation I/O,也就是3GIO),也就是後來的PCI Express匯流排規範。不過在公布之初,套用環境、配套設備還不是很完善,並不為人們所關注。到了2002年4月17日,AWG正式宣布3GIO 1.0規範草稿制定完畢,並移交PCI-SIG進行審核,該規範最終卻被命名為PCI Express,而到了2003年Intel春季IDF上,Intel正式公布了PCI Express的產品開發計畫,PCI Express最終走向套用。
PCI-E 3.0
常見的顯示卡都是PCI-E 2.0標準的,制定於2007年,速率5GT/s,x16通道頻寬可達8GB/s。按照原先的路線圖,PCI-E 3.0標準將在2010年進入市場,不過實際上卻是2010年才完成PCI-E 3.0標準的最終方案,而直到一年後HD 7970發布才真正有顯示卡支持PCI-E 3.0。
PCI-E 3.0:頻寬更高、延遲更低
與PCI-E 2.0相比,PCI-E 3.0的目標是頻寬繼續翻倍達到10GB/s,要實現這個目標就要提高速度,PCI-E 3.0的信號頻率從2.0的5GT/s提高到8GT/s,編碼方案也從原來的8b/10b變為更高效的128b/130b,其他規格基本不變,每周期依然傳輸2位數據,支持多通道並行傳輸。
除了頻寬翻倍帶來的數據吞吐量大幅提高之外,PCI-E 3.0的信號速度更快,相應地數據傳輸的延遲也會更低。此外,針對軟體模型、功耗管理等方面也有具體最佳化。簡而言之,PCI-E 3.0就跟高速路一樣,車輛跑得更快,發車間隔更低,座位更舒適。
特點和長處
PCI Express匯流排是一種完全不同於過去PCI匯流排的一種全新匯流排規範,與PCI匯流排共享並行架構相比,PCI Express匯流排是一種點對點串列連線的設備連線方式,點對點意味著每一個PCI Express設備都擁有自己獨立的數據連線,各個設備之間並發的數據傳輸互不影響,而對於過去PCI那種共享匯流排方式,PCI匯流排上只能有一個設備進行通信,一旦PCI匯流排上掛接的設備增多,每個設備的實際傳輸速率就會下降,性能得不到保證。PCI Express以點對點的方式處理通信,每個設備在要求傳輸數據的時候各自建立自己的傳輸通道,對於其他設備這個通道是封閉的,這樣的操作保證了通道的專有性,避免其他設備的干擾。
在傳輸速率方面,PCI Express匯流排利用串列的連線特點將能輕鬆將數據傳輸速度提到一個很高的頻率,達到遠超出PCI匯流排的傳輸速率。PCI Express的接口根據匯流排位寬不同而有所差異,包括x1、x4、x8以及x16(x2模式將用於內部接口而非插槽模式),其中X1的傳輸速度為250MB/s,而X16就是等於16倍於X1的速度,即是4GB/s。與此同時,PCI Express匯流排支持雙向傳輸模式,還可以運行全雙工模式,它的雙單工連線能提供更高的傳輸速率和質量,它們之間的差異跟半雙工和全雙工類似。因此連線的每個裝置都可以使用最大頻寬,PCI Express接口設備將有著比PCI設備優越的多的資源可用。
除了這些,PCI Express設備能夠支持熱拔插以及熱交換特性,支持的三種電壓分別為+3.3V、3.3Vaux以及+12V。考慮到顯示卡功耗的日益上漲,PCI Express而後在規範中改善了直接從插槽中取電的功率限制,16x的最大提供功率達到了70W,比AGP 8X接口有了很大的提高。基本可以滿足未來中高端顯示卡的需求。這一點可以從AGP、PCI Express兩個不同版本的6600GT上就能明顯地看到,後者並不需要外接電源。
可以看到PCI Express只是南橋的擴展匯流排,它與作業系統無關,所以也保證了它與原有PCI的兼容性,也就是說在很長一段時間內在主機板上PCI Express接口將和PCI接口共存,這也給用戶的升級帶來了方便。由此可見,PCI Express最大的意義在於它的通用性,不僅可以讓它用於南橋和其他設備的連線,也可以延伸到晶片組間的連線,甚至也可以用於連線圖形晶片,這樣,整個I/O系統將重新統一起來,將更進一步簡化計算機系統,增加計算機的可移植性和模組化。PCI Express已經為PC的未來發展重新鋪設好了路基,下面就要看PCI Express產品的套用情況了。
規格比較
 WY5715F BCM5715S
WY5715F BCM5715SPCI Express x16 插槽
PCI Express x1 插槽
PCIe的規範主要是為了提升電腦內部所有匯流排的速度,因此頻寬有多種不同規格標準,其中PCIe x16是專為顯示卡所設計的部分。AGP的資料傳輸效率最高為2.1GB/s,不過對上PCIe x16的8GB/s,很明顯的就分出勝負,但8GB/s只有指資料傳輸的理想值,並不是使用PCIe接口的顯示卡,就能夠有突飛猛進的效能表現,實際的測試數據上並不會有這么大的差異存在。
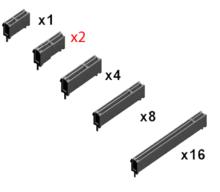
| 傳輸通道數 | 腳Pin總數 | 主接口區Pin數 | 總 長 度 | 主接口區 長度 |
| x1 | 36 | 14 | 25 mm | 7.65 mm |
| x4 | 64 | 42 | 39 mm | 21.65 mm |
| x8 | 98 | 76 | 56 mm | 38.65 mm |
| x16 | 164 | 142 | 89 mm | 71.65 mm |
| 規格 | 匯流排寬度 | 工作時脈 | 傳輸速率 |
| PCI 2.3 | 32 位元 | 33/66 MHz | 133/266 MiB/s |
| PCI-X 1.0 | 64 位元 | 66/100/133 MHz | 533/800/1066 MiB/s |
| PCI-X 2.0(DDR) | 64 位元 | 133 MHz | 2.1 GiB/s |
| PCI-X 2.0(QDR) | 64 位元 | 133 MHz | 4.2 GiB/s |
| AGP 2X | 32 位元 | 66 MHz | 532 MiB/s |
| AGP 4X | 32 位元 | 66 MHz | 1.0 GiB/s |
| AGP 8X | 32 位元 | 66 MHz | 2.1 GiB/s |
| PCI-E 1X | 8 位元 | 2.5 GHz | 512 MiB/s(雙工) |
| PCI-E 2X | 8 位元 | 2.5 GHz | 1.0 GiB/s(雙工) |
| PCI-E 4X | 8 位元 | 2.5 GHz | 2.0 GiB/s(雙工) |
| PCI-E 8X | 8 位元 | 2.5 GHz | 4.0 GiB/s(雙工) |
| PCI-E 16X | 8 位元 | 2.5 GHz | 8.0 GiB/s(雙工) |
甚至對於某些 PCI-E 1X插槽,我們完全可以將其鋸開(這樣有可能會失去質保),比如可以用來插上NVIDIA的顯示卡做為物理加速卡與ATI顯示卡一同工作。
協定問題
在開發第一塊基於PCI Express的SoC過程中,ClearSpeed公司為了在有限的時間和預算條件下確保PCI Express協定一致性而面臨重重困難。PCI Express是一種複雜的協定,具有特別大的覆蓋範圍。從管理的角度看,保證協定一致性沒有其它更好的方法,只有採用標準驅動的驗證過程。遺憾的是,即使做了上千次覆蓋相關場景的測試,仍留有相當大的覆蓋漏洞,從而使得這個方法沒有可預測性,成本也很高。而另外一種普通的隨機測試方法也沒有足夠的可預測性。
ClearSpeed公司開始意識到,理想的方法可以產生顯著的好處:它能最小化技術開發工作量,同時最大化測試套用控制。ClearSpeed公司率先採用Cadence公司提供的商用化PCIe驗證IP。這種驗證IP被稱為UVC,包含了一致性管理系統(CMS),該系統將覆蓋空間劃分和映射到了PCIe規範。CMS還提供受限隨機測試(稱為測試序列)形式的一致性測試套件,用於自動取得針對每個PCIe規範部分的高功能性覆蓋。
ClearSpeed公司還在UVC基礎上創建了自己的受限隨機測試套件。相關覆蓋在每次測試組運行之後都會進行分析,從而能清楚地理解覆蓋漏洞出現在什麼地方,並指導新的測試應在什麼地方進行以到達未被覆蓋的場景。這種方法還向ClearSpeed提供了無價的項目管理工具,因為它能幫助理解和報告驗證狀態。ClearSpeed公司能夠在每個主要的規範領域正常地跟蹤覆蓋、缺陷統計和測試故障。
工程背景
ClearSpeed公司的產品範圍包括晶片、加速器卡、機架模組、軟體和支持。ClearSpeed公司的晶片、加速器卡和機架模組都可以與工業標準的x86系統一起使用。ClearSpeed公司的晶片採用C語言進行編程,並且公司向用戶提供可與所有標準軟體開發工具協同工作的完整IDE.
與以前的CXS600晶片相比,主要變化如下:
⒈ 一個晶片上有兩個處理器核心(“MTAP”)
⒉晶片上有一個標準的PCIe接口(相對私有PCIx接口而言)
⒊ MTAP有多項的改進
總體驗證需求
圖1給出了ClearSpeed產品的架構。為了確保這個複雜產品的質量,需要對以下性能進行驗證:
⒈ 驅動程式代碼與晶片的緊密集成
⒉ 眾多軟體庫和應用程式的集成
⒊ 與各種主機(作業系統和晶片組)環境的兼容性
⒋ 高性能和低功率
從晶片本身看,主要驗證挑戰是最新引入的PCIe接口。為了應對這些驗證挑戰,ClearSpeed公司採用了一種適合待測複雜設計的先進驗證策略。整個驗證策略中有一些要點是可以明確的:
⒈ 這種驗證策略是以仿真為基礎,並採用了覆蓋驅動的偽隨機方法。
⒉ 使用了分層仿真策略,從模組級開始,並逐漸向外擴展。
⒊ 與軟體的協同仿真非常重要,它有助於展示產品的正確性,並在晶片回廠時為矽片取得成功取得了良好開端。
⒋軟體協同仿真也是分層執行的,從驅動程式開始,一直擴展到應用程式。
⒌ 模組和層次體系之間的驗證再利用。
⒍ 使用驗證IP。這樣做有利於充分利用該領域專家的現有知識,並有利於加快測試平台的開發速度。
總的驗證指導原則是在晶片開發初期從商業和技術角度獲得簽字確認標準。這些確認標準是客觀性的,可以使用合適的準則進行測量。這樣做具有很多優點,包括:
⒈ 能夠使所有感興趣方預先同意用於驗證的對象。
⒉ 能夠在項目執行中跟蹤向驗證簽字確認方向發展的進程。
⒊ 能夠建立流片時的信心。
為了與上述原則保持一致,預先對CSX700驗證確認標準進行了定義。所選的關鍵指標有:
⒈ 功能覆蓋目標:
⑴ 優先權1覆蓋目標達到100%
⑵ 所有其它覆蓋目標至少達到95%,並檢查所有未實現的覆蓋目標。
⒉ 編寫和支持的所有系統級測試。
⒊ 在所有可用PCIe伺服器中工作的原型PCIe。
⒋ 檢查缺陷發現率以確保(與功能覆蓋一起)我們正在接近所有最重要缺陷已經被發現的點。
⒌ 檢查任何突出並已知未修復的問題,並評估它們的影響。
下面將在上文描述的總體驗證策略框架下討論PCIe驗證策略。
模組級驗證
PCIe模組級測試平台。ClearSpeed公司已經開發過圖中所示的AVCI、PVCI和私有協定,因此PCIe接口提出了主要的驗證挑戰。由於我們使用的IP來自不同的管線PHY和端點核心供應商,因此這種挑戰越發艱巨。
測試平台採用了許多UVC。除了PCIe UVC外,其它UVC都是ClearSpeed公司自己開發的。測試平台的其它部分使用公司自己的UVC有利於建立同質的eRM一致性系統(uRM和OVM)。
選用第三方ⅥP的原因是因為:PCIe協定的複雜性;驗證任務的工作量以及缺少內部資源;ⅥP的成熟度;獨立的ⅥP可以由與內部開發小組不相干的外部PCIe專家組開發。
系統級測試
系統級測試平台包括了晶片和軟體驅動堆疊。實際的軟體驅動程式基本原樣投入使用,除了在堆疊底部做了一些修改,即將調用做進了仿真環境中,並由軟體驅動PCIe UVC。更多細節請參考圖4。在本例中,驅動程式完成與硬體對話要做的所有事情,並且每個事務都要傳送給仿真器。這樣運行起來雖然比較慢,但確實能讓我們測試DMA引擎等。
驅動程式可以連線到PCIe層上面的仿真器。這樣無需花費時間在完整仿真每個PCI事務上面就可以實現對更高層單元的仿真。這對仿真在處理器上運行的程式來說是非常有用的。
雖然通過使用UVC可以在測試規範允許的地方(例如在一些要寫入的數據中,在定義範圍內的地址中)使用受限隨機激勵,但在系統級主要套用定向測試方法。在系統級存在許多現成的定向測試,主要目標是用它們擴展測試這個晶片的變化(如前所列出的)。許多vPlanning會話被保持以獲得測試規範,然後我們就能跟蹤這些測試的實現。一旦驅動程式堆疊經驗證能與RTL一起工作,就可以運行較高層的軟體。
運行這些應用程式能給功能驗證和性能驗證帶來高度的信心。
在CSX700的開發過程中,ClearSpeed公司生產了一種基於現有矽片(CSX600)但用FPGA提供PCIe接口的產品,這樣允許我們模擬PCIe接口並執行兼容性測試。也就是說,我們能將被模擬的PCIe接口連線到運行各種OS的眾多伺服器上,從而在流片前確定兼容性問題。它還能讓我們更徹底地測試帶PCIe的軟體驅動程式堆疊接口。
該方法可以識別主要位於PCIe堆疊物理層中的缺陷(FPGA中的PHY不同於我們晶片中的PHY),也讓我們注意到我們連線的伺服器中PCIe實現的變化數量,並促使我們提升取得很高覆蓋的重要性:我們對覆蓋劃分優先等級,並為最高優先權對象設定100%的目標。然而,該方法不能識別通過仿真&;覆蓋也不能發現的PHY外的任何缺陷。這使我們相信,PCIe仿真中的高覆蓋將有助於取得很高的首次流片成功率。
原型的其它優勢還表現在軟體開發方面。它能幫助PCIe軟體驅動程式遠早於CSX700矽片開發出來,加快基於CSX700的產品的上市時間。
驗證環境
用於PCI Express的Incisive UVC能讓用戶專注於設計的任何部分或整個設計,並針對驗證過程中每一階段的特殊需要最佳化驗證環境。Incisive UVC一般用於在模組、晶片和系統級對PCI Express器件進行功能驗證。它也可以通過配置有選擇地激活或關閉各個功能模組以及功能覆蓋和檢測機制來最佳化特殊任務的驗證。這樣可以提供到驗證收斂的最可預測路徑,並最大化在仿真器和工作站方面做出的投資回報。
自動激勵產生
與使用上千次定向測試的其它解決方案不同,用於PCI Express的UVC採用自動激勵發生器來減少用戶需要做的工作量。利用包含所供序列庫在內的自動化情景產生功能,用戶可以覆蓋主要協定功能以及難以到達的情景和邊界案例。通過增加少量測試,剩餘的邊界案例就能被一一驗證。這種方法有助於用戶更快地發現更多缺陷,並讓設計師有更多的時間進行DUT的私有功能測試。CMS可以實現整個過程的自動化。
CMS驗證
CMS向用戶提供了可執行的驗證計畫(vPlan)。vPlan與Enterprise Manager以及內置功能覆蓋模型一起可以提供清晰地報告哪些被覆蓋、還有哪些沒被覆蓋所需的標準。這給用戶提供了驗證過程的路線圖、收斂標準以及可預測的驗證過程,並向項目或管理方提供明晰的狀態報告。這種方法被稱為覆蓋驅動的驗證,可以幫助驗證人員方便地識別覆蓋漏洞,並將資源集中用於DUT的有問題部分。
Cadence的再利用方法可以快速建立功能驗證環境,確保在從模組級驗證向晶片級、系統級驗證轉移以及派生設計時能立即再利用基於UVC的環境。這種方法通過消除重複工作而節省了時間與資源。
優先權劃分
通過使用能用來禁止掉與DUT無關的覆蓋區/條目的“透視圖(perspective)”,ClearSpeed公司能夠只考慮與實現有關的覆蓋點。ClearSpeed使用以下這個透視圖:
“端點,AER = On,VC 1-7 = Off,完成器退出 = Off,配置請求重試狀態 = Off,抑制 = Off"
CMS允許由主要的PCIe模組TPL、TXN、DLL、PHY、PMG、SYS和CONFIG報告覆蓋,這有助於ClearSpeed公司根據技術風險劃分驗證工作的優先權。
我們認為物理層(PHY)存在較高的風險,因為物理層有兩個不同的IP供應商,而且FPGA原型測試中沒有覆蓋PHY(因為FPGA使用不同的PHY);Power mgt是下一個最高優先權對象,因為在FPGA原型中沒有覆蓋到它(由於技術限制的原因);數據鏈路層是下一優先等級,因為它靠近PHY。
我們還要求更細顆粒的優先權劃分:模組內的優先權劃分。雖然一般來說可以使用透視圖進行優先權劃分,但這種方法不能滿足所有需要和優先權劃分的使用模型。它缺少更細的顆粒和一些對CMS專業用戶(如ClearSpeed和IP開發人員)來說更重要的再利用因素。
測試套件
CMS提供的一致性測試可以使你一開始就有一個很好的基本覆蓋,並因此而快速啟動驗證工作。ClearSpeed公司是比較早介入的,在整個項目中也在不斷自我修正(附加的覆蓋項目和一致性測試),因此一致性測試取得的覆蓋在項目過程中會有變化。據Cadence公司估計,用戶通過使用現成的CMS測試套件能夠達到約70%的覆蓋。
CMS測試也能經過配置進入PCIe協定的邊界案例。然後,我們就可以寫出許多自己的測試來驅動UVC達到想要的覆蓋水平。
版本區別
PCI Express 2.0是PCI Express匯流排家族中的第二代版本。其中第一代的PCI Express 1.0標誌於2002年正式發布,它採用高速串列工作原理,接口傳輸速率達到2.5GHz,而PCI Express 2.0則在1.0版本基礎上更進了一步,將接口速率提升到了5GHz,傳輸性能也翻了一番。新一代晶片組產品均可支持PCI Express 2.0匯流排技術,X1模式的擴展口頻寬總和可達到1GB/s,X16圖形接口更可以達到16GB/s的驚人頻寬值。
硬體協定
PCIe的連線是建立在一個雙向的序列的(1-bit)點對點連線基礎之上,這稱之為“傳輸通道”。與PCI 連線形成鮮明對比的是PCI是基於匯流排控制,所有設備共同分享的單向32位並行匯流排。PCIe是一個多層協定,由一個對話層,一個數據交換層和一個物理層構成。物理層又可進一步分為邏輯子層和電氣子層。邏輯子層又可分為物理代碼子層(PCS)和介質接入控制子層(MAC)。
物理層
各式不同的PCI Express插槽(由上而下:x4,x16,x1,與 x16),相較於傳統的32-bit PCI插槽(最下方),取自於DFI的LanParty nF4 Ultra-D機板
於使用電力方面,每組流水線使用兩個單向的低電壓差分信號(LVDS)合計達到2.5兆波特。傳送及接收不同數據會使用不同的傳輸通道,每一通道可運作四項資料。兩個PCIe設備之間的連線成為“連結”,這形成了1組或更多的傳輸通道。各個設備最少支持1傳輸通道(x1)的連結。也可以有2,4,8,16,32個通道的連結。這可以更好的提供雙向兼容性。(x2模式將用於內部接口而非插槽模式)PCIe卡能使用在至少與之傳輸通道相當的插槽上(例如x1接口的卡也能工作在x4或x16的插槽上)。一個支持較多傳輸通道的插槽可以建立較少的傳輸通道(例如8個通道的插槽能支持1個通道)。PCIe設備之間的連結將使用兩設備中較少通道數的作為標準。一個支持較多通道的設備不能在支持較少通道的插槽上正常工作,例如x4接口的卡不能在x1的插槽上正常工作(插不入),但它能在x4的插槽上只建立1個傳輸通道(x1)。PCIe卡能在同一數據傳輸通道內傳輸包括中斷在內的全部控制信息。這也方便了與PCI的兼容。多傳輸通道上的數據傳輸採取交叉存取,這意味著連續位元組交叉存取在不同的通道上。這一特性被稱之為“數據條紋”,需要非常複雜的硬體支持連續數據的同步存取,也對連結的數據吞吐量要求極高。由於數據填充的需求,數據交叉存取不需要縮小數據包。與其它高速數傳輸協定一樣,時鐘信息必須嵌入信號中。在物理層上,PCIe採用常見的8B/10B代碼方式來確保連續的1和0字元串長度符合標準,這樣保證接收端不會誤讀。編碼方案用10位編碼比特代替8個未編碼比特來傳輸數據,占用20%的總頻寬。有些協定(如SONET)使用另外的編碼結構如“不規則”在數據流中嵌入時鐘信息。PCIe的特性也定義了一種“不規則化”的運算方法,但這種方法與SONET完全不同,它的方法主要用來避免數據傳輸過程中的數據重複而出現數據散射。第一代PCIe採用2.5兆位單信號傳輸率,PCI-SIG計畫在未來版本中增強到5~10兆位。
數據連結層
數據連結層採用按序的交換層信息包(Transaction Layer Packets,TLPs),是由交換層生成,按32位循環冗餘校驗碼(CRC,本文中用LCRC)進行數據保護,採用著名的協定(Ack and Nak signaling)的信息包。TLPs能通過LCRC校驗和連續性校驗的稱為Ack(命令正確應答);沒有通過校驗的稱為Nak(沒有應答)。沒有應答的TLPs或者等待逾時的TLPs會被重新傳輸。這些內容存儲在數據連結層的快取內。這樣可以確保TLPs的傳輸不受電子噪音干擾。
Ack和Nak信號由低層的信息包傳送,這些包被稱為數據連結層信息包(Data Link Layer Packet,DLLP)。DLLP也用來傳送兩個互連設備的交換層之間的流控制信息和實現電源管理功能。
交換層
PCI Express採用分離交換(數據提交和應答在時間上分離),可保證傳輸通道在目標端設備等待傳送回應信息傳送其它數據信息。它採用了可信性流控制。這一模式下,一個設備廣播它可接收快取的初始可信信號量。連結另一方的設備會在傳送數據時統計每一傳送的TLP所占用的可信信號量,直至達到接收端初始可信信號最高值。接收端在處理完畢快取中的TLP後,它會回送傳送端一個比初始值更大的可信信號量。可信信號統計是定製的標準計數器,這一算法的優勢,相對於其他算法,如握手傳輸協定等,在於可信信號的回傳反應時間不會影響系統性能,因為如果雙方設備的快取足夠大的話,是不會出現達到可信信號最高值的情況,這樣傳送數據不會停頓。第一代PCIe標稱可支持每傳輸通道單向每秒250兆位元組的數據傳輸率。這一數字是根據物理信號率2500兆波特除以編碼率(10位/每位元組)計算而得。這意味著一個16通道(x16)的PCIe卡理論上可以達到單向250*16=4000兆位元組/秒(3.7G位元組/每秒)。實際的傳輸率要根據數據有效載荷率,即依賴於數據的本身特性,這是由更高層(軟體)應用程式和中間協定層決定。PCI Express與其它高速序列連線系統相似,它依賴於傳輸的魯棒性(CRC校驗和Ack算法)。長時間連續的單向數據傳輸(如高速存儲設備)會造成>95%的PCIe通道數據占用率。這樣的傳輸受益於增加的傳輸通道,但大多數應用程式如USB或乙太網絡控制器會把傳輸內容拆成小的數據包,同時還會強制加上確認信號。這類數據傳輸由於增加了數據包的解析和強制中斷,降低了傳輸通道的效率。這種效率的降低並非只出現在PCIe上。
技術套用
| 產品名稱 | 詳細參數 |
| 特科芯特科芯(TEKISM)PER970芯紀戰艦系列 1TB PCI-E 固態硬碟 | 快取:128MB*5讀寫速度:最大讀:2000MB/s 最大寫:1970MB/s主控:Marvell +SF2200 系列主控顆粒:原廠東芝顆粒快閃記憶體類型:MLC原廠顆粒啟動功率:寫入:20W 空閒:12W尺寸:193.1*127.1*21.7(mm) 工作溫度:0℃~-+60℃保存溫度:-40℃~-+85℃ |
| 影馳9600GT中將版 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9600GT 製造工藝:65納米 顯存類型:GDDR3 顯存容量(MB):512 匯流排接口:PCI Express 2.0 16X 顯存速度(ns):1.0ns 顯存位寬:256bit 核心頻率:650MHz 顯存頻率:1800MHz |
| 七彩虹逸彩9600GT-GD3 CF黃金版 512M N1 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9600GT 製造工藝:55納米 顯存類型:GDDR3 顯存容量(MB):512 顯存速度(ns):1.0ns 匯流排接口:PCI Express 2.0 16X 顯存位寬:256bit 核心頻率:600MHz 顯存頻率:1800MHz |
| 七彩虹逸彩9800GT-GD3 冰封騎士3F 512M | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9800 GT 製造工藝:55納米 顯存類型:GDDR3 顯存容量(MB):512 顯存速度(ns):1.0ns 匯流排接口:PCI Express 2.0 16X 顯存位寬:256bit 核心頻率:600MHz 顯存頻率:1800MHz |
| 影馳9800GT+中將版 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9800 GT 製造工藝:55納米 顯存類型:GDDR3 顯存容量(MB):512 顯存速度:0.8ns 匯流排接口:PCI Express 2.0 16X 顯存位寬:256bit 核心頻率:650MHz 顯存頻率:2200MHz |
| 影馳GTX260+上將 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce GTX 260 製造工藝:55納米 顯存類型:GDDR3 顯存容量(MB):896 顯存速度:0.8ns 匯流排接口:PCI Express 2.0 16X 顯存位寬:448bit 核心頻率:625MHz 顯存頻率:2000MHz |
| 影馳9600GT節能加強版 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9600GT 顯存類型:GDDR3 顯存容量(MB):512 匯流排接口:PCI Express 2.0 16X 顯存速度:1.0ns 顯存位寬:256bit 核心頻率:600MHz 顯存頻率:1600MHz |
| 影馳9600GT加強版 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9600GT 製造工藝:55納米 顯存類型:GDDR3 顯存容量(MB):512 顯存速度(ns):1.0ns 匯流排接口:PCI Express 2.0 16X 顯存位寬:256bit 核心頻率:650MHz 顯存頻率:1800MHz |
| 藍寶石HD4850 512M 海外版 HDMI | 晶片廠商:ATI 顯示卡晶片:Radeon HD 4850 製造工藝:55納米 顯存類型:GDDR3 顯存容量(MB):512 顯存速度(ns):1.0ns 匯流排接口:PCI Express 2.0 16X 顯存位寬:256bit 核心頻率:650MHz 顯存頻率:2000MHz |
| nⅥDIA Quadro NVS 290 | 適用類型:工作站 製造工藝:80納米 顯存位寬:64bit 核心頻率:300MHz 顯示卡接口:PCI Express x16或PCI Express x1 DirectX版本:10 |
| 藍寶石HD3850藍曜天刃PRO 512MB | 晶片廠商:ATI 顯示卡晶片:Radeon HD 3850 顯存類型:DDRⅢ 顯存容量(MB):512 顯存位寬:256bit 匯流排接口:PCI Express 2.0 顯存速度(ns):1.0ns |
| 影馳9600GTE上將版 | 晶片廠商:NⅥDIA 顯示卡晶片:GeForce 9600GT 顯存類型:DDRⅢ 顯存容量(MB):512 顯存位寬:256bit 匯流排接口:PCI Express 2.0 顯存速度(ns):1.0ns |
4路採集卡
SVC404E是一款高性價比、高清晰度、質量穩定的PCI-E專業流媒體採集卡。該產品主要針對流媒體領域的要求,採用通用的 DirectShow 驅動架構,具有高效率的視頻和聲音採集能力。高性能的模擬視頻前端濾波處理能力、高精度的音頻採樣能力,大大提升了視音頻採集的清晰度。
注釋
PCI Express是新一代能夠提供大量頻寬和豐富功能的新式圖形架構。PCI Express可以大幅提高中央處理器(CPU)和圖形處理器(GPU)之間的頻寬。它可以給視頻套用者更完美地享受影院級的圖象效果,並獲得無縫多媒體體驗。
套用領域
基於網際網路流媒體線上直播、視頻會議系統、VOD點播、遠程監控、教學、 DVD製作,硬碟播出、廣告截播、媒體資產管理。
技術特點
四路獨立的視音頻採集處理。
每路獨立可以調成NTSC或PAL制。
四路視頻輸入和四路音頻輸入。
每路支持最大解晰度為NTSC:720x480;PAL:720X576。
支持大多數的視音頻採集軟體,如Media Encoder,Helix Real Producer等。
支持最大幀率30fps。
四路無壓縮視音頻數據DMA信道,使得四路視音頻預覽零CPU占用率。
高性能的模擬視頻前端濾波處理能力,使原信號得到低碼率高清晰的還原。
支持軟體。
支持國內大多數視頻會議軟體,例如:AVCON視頻會議系統、V2 Conference視頻會議系統、網動視頻會議系統。
支持Media Encoder,Helix Real Producer。
支持多種編碼格式,包括:Wmv9,Rmvb,Rm,MPEG-4,DivX多格式視頻編碼,混合不同碼率、解析度的視頻同步流暢輸出及播放。
實時預覽,全文互式與處理硬體參數能力。
支持可程式時間觸發(GPI,持續時調,自選鍵)。
從現存檔案中進行最佳化轉碼(AⅥ/Quicktime/Quicktime類型檔案)到多格式編碼 。
實際套用案例:
EP-H6200E MIL-STD-1553B/429/串口多協定通信PCI-E模組
EP-H6273E 1-2通道MIL-STD-1553B通訊PCI-E模組
EP-H6272E 16T/R ARINC429通訊PCI-E模組
EP-H6275E LVDS通訊接口PCI-E模組
EP-H6278E 雙通道CAN匯流排通信PCI-E模組
EP-H6276E 16CH全異步RS-232/422串口通信PCI-E模組
EP-H6331E AD/DA/IO多功能PCI-E模組
EP-H6110E 1000MSPS 8Bit 1Ch數據採集PCI-E模組
EP-H6024AE 1MSPS12-Bit 8Ch數據採集PCI-E模組
EP-H6027AE 64MSps 14Bit 1CH ADC+DDC+DSP數據採集PCI-E模組
EP-H6033E 64SE/32DI數據採集PCI-E模組
EP-H6279E 1CH GPS接收PCI-E模組
EP-H6172E 16-Bit 8Ch 模擬輸出PCI-E模組
EP-H6121CE 32通道隔離離散量輸入/輸出PCI-E匯流排模組
EP-H6121AE 64通道隔離開關量I/O PCI-E匯流排模組
EP-H6122CE 8CH標準RS-422電平計數器PCI-E匯流排模組
規範及改進
早在2007年上半年PCI-E 2.0版規範剛剛公布的時候,PCI Express技術標準組織PCI-SIG就準備用兩年多的時間將其快速進化到第三代,但是誰也沒想到PCI-E 3.0的醞釀過程會如此一波三折,直到今天才終於修成正果。
PCI-SIG主席兼總裁幾乎淚流滿面:“PCI-SIG始終致力於I/O創新,我們也很驕傲地向我們的成員發布PCI-E 3.0規範。PCI-E 3.0架構從細節上對前兩代PCI-E規範進行了極大地改進,為我們的成員在各自領域繼續創新提供了所必需的性能和功能。”
在對可製造性、成本、功耗、複雜性、兼容性等諸多方面進行綜合、平衡之後, PCI-E 3.0規範將數據傳輸率提升到8GHz|8GT/s(最初也預想過10GHz),並保持了對PCI-E 2.x/1.x的向下兼容,繼續支持2.5GHz、5GHz信號機制。基於此,PCI-E 3.0架構單信道(x1)單向頻寬即可接近1GB/s,十六信道(x16)雙向頻寬更是可達32GB/s。
PCI-E 3.0同時還特別 增加了128b/130b解碼機制,可以確保幾乎100%的傳輸效率,相比此前版本的8b/10b機制提升了25%,從而促成了傳輸頻寬的翻番,延續了PCI-E規範的一貫傳統。
新規範在信號和軟體層的其他增強之處還有數據復用指示、原子操作、動態電源調整機制、延遲容許報告、寬鬆傳輸排序、基地址暫存器(BAR)大小調整、I/O頁面錯誤等等,從而全方位提昇平台效率、軟體模型彈性、架構伸縮性。
PCI-E 3.0規範完整文檔現已向PCI-SIG組織成員公布其中詳細描述了PCI-E架構、互聯屬性、結構管理、編程接口等等,但沒有公開發表。另外,intel X79高端晶片組經已完整支持pci-e3.0規格,AMD最新架構旗艦顯示卡AMD Radeon 7970,以及其他採用pci-e 3.0規格的顯示卡將於2012年陸續發布。
AMD和HP將改進PCI Express 3.0規範
AMD和惠普公司的專家日前為PCI Express 3.0開發了兩個新的擴展功能規範,藉由這兩項新規範,除了可以降低相關微電路成本外還可以增加對多協定的支持,並且可以降低設備對中央處理器的訪問頻率。
開發人員希望他們的提案能夠被發布的PCI-E 3.0規範所採納。上述兩個擴展功能並不互相依賴,它們主要套用於內置系統或高速系統的圖形套用。第一個擴展功能被稱為多路復用協定,它利用板卡上的一系列模組,實現PCI-E和其他7種不同的協定之間的動態切換。利用該功能,我們可以構建這樣一個解決方案:通過PCI-E接口,處理器和顯示卡通過QPI(Quick Path Interconnect)或者HT(Hyper Transport)連線。
第二個擴展功能被稱為輕信息,它允許協處理器及外圍設備在存儲系統的支持下,通過PCI-E接口互相通信,而不必再經過中央處理器。例如,乙太網交換機可以不通過中央處理器而獨立的編碼和解碼數據。
另外,這兩項擴展功能適用於工作頻率為2.5GHz、5GHz和8GHz版本的PCI-E規範。
PCI-E 3.0規範向下兼容PCI-E 2.0和PCI-E 1.0,最高傳輸速度可達32GB/s,有望在2010年出現相關產品。
PCI Express 2.0和PCI Express16的區別
PCI-E 2.0相對於1.0來說,的確是名副其實的雙倍規格:
頻寬翻倍:將單通道PCI-E X1的頻寬提高到了500MB/s,也就是雙向1GB/s;
通道翻倍:顯示卡接口標準升級到PCI-E X32,頻寬可達32GB/s;
插槽翻倍:晶片組/主機板默認應該擁有兩條PCI-E X32插槽;
功率翻倍:目前PCI-E插槽所能提供的電力最高為75W,2.0版本可能會提高至200W以上,還不確定中。
PCI-Express是當前主流的匯流排和接口標準,它原來的名稱為“3GIO”,是由Intel提出的,很明顯Intel的意思是它代表著下一代I/O 接口標準。交由PCI-SIG(PCI特殊興趣組織)認證發布後才改名為“PCI-Express”。這個新標準將全面取代現行的PCI和AGP,最終實現匯流排標準的統一。1990年引進PCI匯流排接口時,由於其具有處理器獨立性、緩衝隔絕以及匯流排控制和隨插即用等機制及特性,不久之後便一舉統一了包含ISA、VESA、VL BUS、EISA以及MCA等匯流排規格,成為個人計算機中的匯流排插槽主流。
不過其運作頻率的進步不若中央處理器那般突飛猛進,因此在面對新一代的擴充卡及周邊時,已經有力不從心的感覺,而共享式的設計,單一高速周邊(如Gb乙太網絡或IEEE 1394b)可能就會將PCI的所有頻寬吃光。雖然針對特定用途也有高頻率或具備獨立頻寬的版本(如PCI-X和AGP)出現,但是成本的高昂以及使用上的限制,這些特殊規格PCI並沒有成為通用標準。
於2007年1月通過的PCI Express 2.0標準,除了在維持與PCI Express 1.1版兼容性的前提下,對單一通道寬度倍增以外(由原先2.5Gbps提升至5Gbps),並且在原有的特性之下加入了幾項先進的功能,以期更為符合未來的需求。
I/O Vitualization-可套用於包括設備共享、地址轉換服務(ATS)以及單/多處理器系統的單獨規格。可提供給多部虛擬機器共享多種包含網卡等I/O設備,有助於系統管理者在開發以及管理上的方便性。
更強的安全保護機制-可允許軟體來看至互連的封包路由,以防止被不良意圖人士進行欺騙以及竊取封包數據,或者是對於數據進行假路由,在未來PCI Express 2.0規範中,這個特性將會被包含在晶片組、交換晶片以及多功能組件之中。
可自動調整的連結速度-當連結頻寬或速率下降時,控制軟體將會自動偵測並且對硬體進行通報,而自動對連結速度進行調整,動態配置PCI Express匯流排的信道。
更高的供電規格-未來高階顯示卡將會更為耗電,比如說NⅥDIA即將在11月發表的G80(代號)繪圖卡,其耗電量可能高達300W左右,1.1版的PCI Express規範只能提供70W左右,完全不敷及未來高階顯示卡之用,因此在2.0版規範中,將供電能力大幅提升至300W左右。
PCI Express纜線連線規範-這是屬於新的套用,就如同SATA連線規範中有一個eSATA的外部在線上標準,纜線化的PCI Express可提供更為靈活的使用性,比如說計算機的網路、儲存或顯示組件就不必連線至計算機主機板上,只要透過纜線連結,顯示周邊與儲存周邊都可以擁有獨立的電源以及配置空間。甚至也可以進行伺服器之間的互連,達到叢集的目的。
除了以上所提到的以外,更為高速的PCI Express也可以提供整合型圖形晶片對主存儲器更高的讀取速度,不過依照以往的經驗,在這方面的改進對於整合型圖形晶片的效能增長可能並不會很大,影響效能的主要因素還是在於繪圖晶片本身的設計。
不過高速序列架構不僅只於PCI Express一家而已,類似架構的標準還有HyperTransport、Infiniband、RapidIO以及StarFabric等,這些競爭對手也都有各自龐大勢力在支撐。除了背後勢力以外,在技術上也不見得會輸給PCI Express,比如說Infiniband、StarFabric可藉軟體追蹤拓樸結構變化,以實現熱插拔功能,而HyperTransport及RapidIO則是可藉由減少封包大小來加快反應速度,相較起來,PCI Express則是顯得較為中庸,延伸套用較少。
截至2006年底,PCI Express已經成為個人計算機主機板的標準,由於其完全透明的軟體層設計讓軟硬體開發者可以在利用最少資源的情況下得到最好的效能表現,不僅成為高階3D加速卡的指定連線方式,對消費者來說,也成為了效能表現的代名詞。至於PCI Express在筆記型計算機上的延伸標準ExpressCard,雖然面世已有一段時間,但是在支持周邊仍不夠豐富的情況之下,僅少數筆記型計算機廠商具有較全面的支持。
1990年引進PCI匯流排接口時,由於其具有處理器獨立性、緩衝隔絕以及匯流排控制和隨插即用等機制及特性,不久之後便一舉統一了包含ISA、VESA、VL BUS、EISA以及MCA等匯流排規格,成為個人計算機中的匯流排插槽主流。
不過其運作頻率的進步不若中央處理器那般突飛猛進,因此在面對新一代的擴充卡及周邊時,已經有力不從心的感覺,而共享式的設計,單一高速周邊(如Gb乙太網絡或IEEE 1394b)可能就會將PCI的所有頻寬吃光。雖然針對特定用途也有高頻率或具備獨立頻寬的版本(如PCI-X和AGP)出現,但是成本的高昂以及使用上的限制,這些特殊規格PCI並沒有成為通用標準。
為了因應下一代周邊的I/O頻寬需求,以及對於整體架構上的統一化設計,Intel結合各大IT廠商,制訂出PCI-Express規格。PCI-Express架構中,包含了五個堆疊層,其中與過去PCI架構在軟體層(載入儲存架構以及平面地址空間)方面的兼容性,確保了現存應用程式與驅動程式不需要做出任何變革即可正常運作。而由於PCI-Express在設定組態上,也同樣使用了過去套用在PCI上的隨插即用標準機制。軟體層以封包為基礎的設計,並且藉由分割執行的通訊協定,產生可由執行曾傳送至I/O裝置的讀取以及寫入需求。而連結層則是為這些封包加入編號以及錯誤修正碼,以求達到可靠的數據傳輸結果。至於在傳輸實體層方面,則是實作了包含一傳輸對以及一接收對的雙重單通道,每個方向皆具備有2.5Gbps的初始速度,而且可以藉由增加訊號對,以行成多路徑來線性擴展。以一個信道2.5Gbps的速度為傳輸基礎,在實體曾提供了x1、x2、x4、x8、x16以及x32等代表信道數量以及路徑寬度來表示其實際傳輸速度。
pci Express把伺服器帶入新紀元
pci Express的傳輸速度已經達到20甚至100Gbps,pci Express具備即插即用與可擴展性,這些都是數據中心經理們夢寐以求的,當然也是需要衡量性價比的。
需要看一下底層的技術:pci Express。pci Express誕生於2004年,pci Express是一些自協定的合集,具有物理層、數據鏈路層與傳輸層標準定義。pci Express聽起來是OSI網路模型的一部分,而且就像網路一樣,你可以改變物理層。
pci Express只出現在電腦內部,但2011年之後所謂的Thunderbolt接口將pci Express接口擴展到了機箱外。
Thunderbolt接口非常快,傳輸速度在20Gbps,但其實際上是pci Express的不同物理轉接方式。事實上你還可以使用具有普通pci Express插槽的擴展Thunderbolt外殼。Thunderbolt被認為是光學組件,基於Intel矽光子學設計,而且Thunderbolt對非IT消費者來說是非常具有性價比的選擇
pci Express對系統管理的影響十分顯著。想想,如果你的存儲陣列是個即插即用的設備?不管你不信,但pci Express確實發生了。插上伺服器,Windows Update會搜尋驅動程式,pci Express接著將其分配到一個存儲組,大功告成。你還希望繁瑣、容易出錯的存儲管理方式嗎?這同樣還適用於網路。當誰需要IP時,你可以通過遠程直接訪問記憶體,將IP直接寫入。pci Express自動化是一塊創可貼;這種分類管理方法是對IT複雜性問題發起的一次挑戰。
pci Express是Intel即將商品化的領域,pci Express在多方面擁有巨大的好處:標準、成本、靈活性、運營成本,甚至資本支出。pci Express可以整合所有IT,pci Express不再利用乙太網和IP連結所有2U機箱,pci Express是將其全部接到分散式背板上。
電腦知識(二)
| 電腦已經成為人們工作學習生活中不可缺少的工具,相信越來越多的人會使用電腦。但是在使用的過程中您是不是經常遇到這樣或者那樣的問題,令您無法正常的使用?那么,讓我們一起來了解一些電腦的基本知識,讓您的工作學習生活變得更加的愜意! |
