![統計模式識別[統計分類方法]](/img/4/81d/nBnauM3X1cjMwgTOwEzM5ITN1UTM1QDN5MjM5ADMwAjMwUzLxMzL4QzLt92YucmbvRWdo5Cd0FmL0E2LvoDc0RHa.jpg "統計模式識別[統計分類方法]")
內容
一個模式識別系統一般工作在兩個方面:訓練和分類;統計模式識別的理論依據就是貝葉斯理論,當然也可採用修正的bayes理論(風險估計) ;當然bayes理論要求類的分布情況,在已知分布情況下就可直接使用,但一般這種可能性較小,對於只是知道分布函式,但不知道參數的情況,就是估計參數的過程,而在更一般情況下,對應分布是一點信息沒有,這樣可採用Parzen窗核函式估計其分布或直接基於訓練數據建立決策邊界。實際上多層感知器就是一個非參數的過程。
統計模式的一種分類方法分為指導性訓練和非指導性訓練;非指導性訓練一般對於數據的已知信息很少,如遠程的空間遙感套用,這裡一般採用聚類的方法。另一種分類方法是基於決策邊界是直接獲得還是間接獲得,前者一般是在幾何空間就可完成。無論採用那種方法,訓練集非常關鍵,主要訓練的數據量要足夠大而且要足夠典型,這樣才能保證算法的可靠性,訓練集的套用上注意以下幾點:訓練樣本的個數應該在10倍於特性數據維數;相對於訓練樣本,分類器的未知參數不能過多;分類器不能出現過度訓練的問題。
統計模式識別方法就是用給定的有限數量樣本集,在已知研究對象統計模型或已知判別函式類條件下根據一定的準則通過學習算法把 d維特徵空間劃分為c個區域,每一個區域與每一類別相對應。模式識別系統在進行工作時只要判斷被識別的對象落入哪一個區域,就能確定出它所屬的類別。由噪聲和感測器所引起的變異性,可通過預處理而部分消除;而模式本身固有的變異性則可通過特徵抽取和特徵選擇得到控制,儘可能地使模式在該特徵空間中的分布滿足上述理想條件。因此一個統計模式識別系統應包含預處理、特徵抽取、分類器等部分。
基本過程
數據採集與預處理
數據的採集是進行統計模式識別驗證的前提條件。一個性能良好的識別系統一定需要首先捕獲到好的特徵數據。利用這些數據,我們就可以進行後續的預處理、特徵提取、特徵選擇等工作。一般來說,這裡的數據採集肯定需要藉助相應的硬體設備,諸如,聲音感測器、圖像感測器等等。如果感測器的靈敏度不高,或者感測器的精確度不高,那么勢必會對所採集到的數據產生一定的噪聲污染。這樣一來,儘管可以通過後續的預處理來減弱甚至消除一部分噪聲,但是,終究無法做到完全去除噪聲的干擾。所以,數據採集部分應該儘量保證所得到的數據純正、乾淨。通常我們可以採集相當數量的數據,並從中選擇最優、最好、最具有代表性的數據來作為原始的輸入。這樣,就從源頭上保證了數據取樣對最終生物識別驗證系統的干擾最小。
另外,需要注意的是,針對不同的生物特徵,數據採集的方法和原理是不同的。掌紋識別,是基於人的手掌脈絡的不同分叉、線條的粗細等特徵為依據來進行最終的識別。筆跡識別則是利用了不同的人在簽名時筆劃的長度、角度、偏移,握筆的力度、書寫時的速度,加速度等特徵來進行區分的。
在基於統計方法的模式識別技術領域,所謂的預處理一般是指去除噪聲的干擾,加強有效信息的過程。前面已經提到,原始數據的採集不可避免的要引入一些噪聲的干擾,對於一個實際的生物識別系統而言,預處理是一個必要的環節。但是,需要注意的是,雖說預處理的作用都是減弱甚至消除噪聲的干擾,同時增強有用信息的強度,不過,針對不同的特徵,預處理的方法也是千差萬別。
特徵提取
一般來說,從感測器得到的數據屬於原始測量空間的數據,而原始測量空間的數據是無法直接進行判別分類的,或者說,直接利用原始測量空間得到的數據進行判別分類往往達不到期望的效果。通常來說,我們需要將數據從原始的測量空間“變換”到二次空間,而這個二次空間,研究人員一般將它稱為特徵空間。將數據從原始空間變換到特徵空間後,我們就得到了表征某模式的二次特徵,一般我們所指的特徵就是這裡所謂的二次特徵。
就特徵的屬性而言,大體上可分為三類:(1)物理特徵,(2)結構特徵,(3)數學特徵。就特徵抽取方法而言,其研究的內容可分為二類:(1)若對象的屬性是明確的則研究的核心問題是如何將它們與目標物體的其它部分分離開來並轉化為能為計算機所接受的數據,(2)若對象的屬性不很明確,則需研究特徵抽取的一般原則。
在模式識別的文獻中,已提出多種準則函式供特徵抽取時參考和利用,基於Fisher判別準則的變換是最為重要的一種特徵抽取方法。此外,還有基於最小均方誤差的準則(它對應於K一L變換特徵抽取),基於瑞利商的準則,基於最小錯誤機率的準則等。人們已注意到,特徵壓縮的投影方向取決於選擇的準則,而不同的投影方向對於識別的效果將產生很大影響。
分類
屬於同一類別的各個模式之間的差異,部分是由環境噪聲和感測器的性質所引起的,部分是模式本身所具有的隨機性質。前者如紙的質量、墨水、污點對書寫字元的影響;後者表現為同一 個人書寫同一字元時,雖然形狀相似,但不可能完全一樣。
因此當用特徵向量來表示這些在形狀上稍有差異的字元時,同這些特徵向量對應的特徵空間中的點便不同一,而是分布在特徵空間的某個區域中。這個區域就可以用來表示該隨機向量實現的集合。假使在特徵空間中規定某種距離度量,從直觀上看,兩點之間的距離越小,它們所對應的模式就越相似。在理想的情況下,不同類的兩個模式之間的距離要大於同一類的兩個模式之間的距離,同一類的兩點間連線線上各點所對應的模式應屬於同一類。一個畸變不大的模式所對應的點應緊鄰沒有畸變時該模式所對應的點。在這些條件下,可以準確地把特徵空間劃分為同各個類別相對應的區域。在不滿足上述條件時,可以對每個特徵向量估計其屬於某一類的機率,而把有最大機率值的那一類作為該點所屬的類別。
分類器有多種設計方法,如貝葉斯分類器、樹分類器、線性判別函式、近鄰法分類、最小距離分類、聚類分析等。
分類器
Fisher分類器
Fisher線性判別分析的基本思想:通過尋找一個投影方向(線性變換,線性組合)將高維問題降低到一維問題來解決,並且要求變換後的一維數據具有如下性質:同類樣本儘可能聚集在一起,不同類的樣本儘可能地遠。
Fisher線性判別分析,就是通過給定的訓練數據,確定投影方向W和閾值y0,即確定線性判別函式,然後根據這個線性判別函式,對測試數據進行測試,得到測試數據的類別。
線性鑑別函式LDA
將樣本換算到某個空間,最大化組間差異,最小化組內差異,隨後將每個組求平均向量,求出組內所有向量與其的距離和矩陣X每個組的平均向量之間再平均得到全局平均向量,每個組內平均向量與全局平均向量的距離和矩陣Y。最後求這兩和的比例的Y/X最大值。
在向量空間裡就是求矩陣的特徵向量,投影到這個特徵向量後聚合度就明顯了。(對比主向量,主向量是說投影到這個主向量後特徵區分更明顯)
SVM
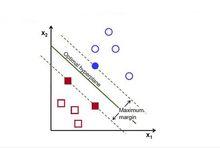 SVM分類器
SVM分類器SVM是一種經典分類器。支持向量機 (SVM) 是一個類分類器,正式的定義是一個能夠將不同類樣本在樣本空間分隔的超平面。 換句話說,給定一些標記(label)好的訓練樣本 (監督式學習),SVM算法輸出一個最最佳化的分隔超平面。SVM算法的實質是找出一個能夠將某個值最大化的超平面,這個值就是超平面離所有訓練樣本的最小距離。這個最小距離用SVM術語來說叫做間隔(margin)。 概括一下,SVM分類器就是最優分割超平面最大化訓練數據的間隔。
K-means
 K-means分類器
K-means分類器K-Means算法是以距離作為相似度的評價指標,用樣本點到類別中心的誤差平方和作為聚類好壞的評價指標,通過疊代的方法使總體分類的誤差平方和函式達到最小的聚類方法。
(1) 從 n個數據對象任意選擇 k 個對象作為初始聚類中心;
(2) 循環(3)到(4)直到每個聚類不再發生變化為止
(3) 根據每個聚類對象的均值(中心對象),計算每個對象與這些中心對象的距離;並根據最小距離重新對相應對象進行劃分;
(4) 重新計算每個(有變化)聚類的均值(中心對象)
Boosting
在實際的分類中通常使用將多個弱分類器組合成強分類器進行分類的方法,統稱為集成分類方法(Ensemble Method)。比較簡單的如在Boosting之前出現Bagging的方法,首先從從整體樣本集合中抽樣採取不同的訓練集訓練弱分類器,然後使用多個弱分類器進行voting,最終的結果是分類器投票的優勝結果。這種簡單的voting策略通常難以有很好的效果。直到後來的Boosting方法問世,組合弱分類器的威力才被發揮出來。
Boosting意為加強、提升,也就是說將弱分類器提升為強分類器。而我們常聽到的AdaBoost是Boosting發展到後來最為代表性的一類。所謂AdaBoost,即Adaptive Boosting,是指弱分類器根據學習的結果反饋Adaptively調整假設的錯誤率,所以也不需要任何的先驗知識就可以自主訓練。
Adboosting
所有樣本作為訓練集,初始權重,訓練弱分類器分錯的增加權重,再訓練,最終得到的分類器是弱分類器的加權平均。
套用
脫機手寫識別
脫機手寫識別(offline handwriting recognition)是文字識別中最有挑戰性的一個問題。主要原因有二,一是手寫文字(樣本)變化很大,不同的人有不同的字型和風格,一些比較潦草的字,常常連人都難以辨認。二是脫機識別的對象是已經寫好的字,因此難以像在線上識別(onfine recognition)那樣提取出對識別很有幫助的筆順信息。
Bayes分類器模型是統計模式識別的基本模型。該模型基於各候選類的先驗機率密度函式(PDF)計算輸入樣本屬於各類的機率。因此要利用Bayes分類器進行文字識別,就要將各候選字的PDF事先估計出來,存儲在系統之中。由於各字的PDF難以用簡單的機率分布解析描述,因此須用數值描述。但由於漢字種類很多,存儲所有字
的PDF數值描述通常需要很大的空間。近年來有學者提出用分段線性近似的方法描述PDF,只用6個數據便能描述一個PDF。從而實現了一個低存儲開銷的基於Beyes分類器的手寫漢字識別系統。
語音識別
語音識別的主要困難來自於語音的多變性,即人們講話的聲音受性別、年齡、口音、語速、情緒、身體狀況、文化程度、社會地位等眾多因素的影響。克服語音多變性的手段同樣是特徵抽取和分類器建模。但適用於語音識別的方法與文字識別的方法有所不同。在特徵抽取方面,人們普遍採用線性預測倒譜係數(LPCC)、鎂爾頻率倒譜係數(MFCC)等方法;在分類器建模方面,早期主要採用動態時間彎曲(DTW)和矢量量化(VQ)的方法,而目前主要採用HMM。
HMM改變了以往利用觀測語音直接判斷含義(說話人要講的是什麼)的方法,而是先計算發音系統經歷了哪個運動(狀態轉移)過程產生的這個語音,然後再來判斷說話人要說什麼。這種方法在語音和含義之間搭建了一個橋樑,即發音系統的運動過程。從而降低了直接由具有多變性的語音判斷含義的困難。
圖像識別
圖像識別是模式識別的一個重要領域,涵蓋目標識別、指紋識別、掌紋識別、虹膜識別、人臉識別等多個方向。近年來,隨著生物信息識別技術在身份認證、信息安全以及反恐等領域中重要作用的突顯,圖像識別技術受到了廣泛的重視。
指紋識別是最成熟的一項生物信息識別技術。目前,各種類型的指紋識別系統已在公安、海關、公司門禁、PC機設鎖等多種場合得到套用,成為展現圖像識別技術實用價值的標誌。指紋識別系統既有套用於公司、家庭或個人計算機的嵌入式系統一指紋鎖,也有用於刑偵、護照通關、網路身份認證等領域的大型系統。嵌入式系統存儲的指紋(特徵)數較少(一般在100枚以內),可用簡單的算法實現高精度識別,所要解決的主要問題是如何用簡單、小巧、廉價的設備實現指紋的正確採集和識別。大型系統往往需要儲存上百萬的指紋,因此如何提高指紋的比對速度便成為關鍵。為了能夠進行快速處理,需要對指紋進行很好的組織和採用高速算法。
