
 分層顯示結構化信息,實現結構化數據
分層顯示結構化信息,實現結構化數據定義
對於來源繁多的信息資料,專業人士根據信息的格式加以劃分,將其分為結構化信息和非結構化信息兩大類。
結構化信息,我們通常接觸的資料庫所管理的信息,包括生產、業務、交易、客戶信息等方面的記錄。
非結構化信息,專業術語為內容,所涵蓋的信息更為廣泛,可分為:營運內容(operationalcontent):如契約、發票、書信與採購記錄;部門內容(workgroupcontent):如文書處理、電子表格、簡報檔案與電子郵件;Web內容:如HTML與XML等格式的信息;多媒體內容(RichMediaContent):如聲音、影片、圖形等。
類型
互連網上出現的海量信息,大概分為結構化、半結構化和非結構化三種。結構化信息如電子商務信息,信息的性質和量值的出現的位置是固定的;半結構化的信息如專業網站上的細分頻道,其標題和正文的語法相當規範,關鍵字的範圍相當局限;非結構化的信息如BLOG和BBS,所有內容都是不可預知的。結構化信息和非結構化信息是IT套用的兩個世界,它們有著各自不同的套用進化特點和規律。但是,這兩個世界之間還缺少相互連線的橋樑,而這種缺失使企業中不可避免地存在“活動”、“信息和知識”的分離,其後果就是:雖然它們都在進行著“知識化”的努力,但兩個世界分離的IT套用模式,注定使其難以真正實現它們的初衷——“在最合適的時間,將最合適的信息傳送給最合適的人”。
特點
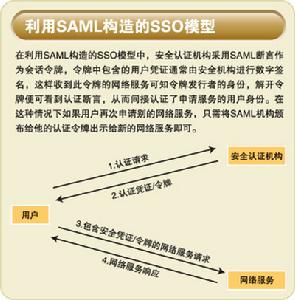 被結構化信息標準促進組織(OASIS)
被結構化信息標準促進組織(OASIS) 了使信息更有效、更有針對性、更便於被查找、更有秩序,“傻目錄”全球首創的“坐標信息定位”體系,可以將地域大小和行業分類分別設定為信息坐標的兩個主坐標軸,讓有效的信息內容在首頁或次頁呈現給查詢者面前。橫坐標是地域大小、位置選擇,範圍大到國家、省、市、行政區,小至三公里社區、一公里社區,查詢者將滑鼠放置在每個地域上面,則會提示出下一級地域的推薦。縱坐標則類似於Windows軟體的資源管理器,呈現的是行業的目錄,從最大的行業分類如生活服務、商業服務、消費品、工業品和原材料到最小的行業分類如生活類的美容美髮、美體減肥等,使用起來極其便利。
網頁抽取
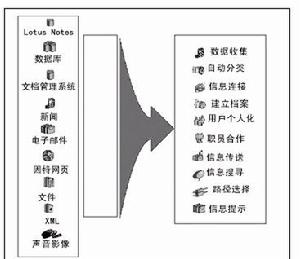 結構化信息資料庫
結構化信息資料庫如:比較購物搜尋那就需要抓取網頁後,對網頁中的商品信息進行抽取,抽取出商品名稱、價格、簡介……甚至可以進一步將筆記本簡介細分成“品牌、型號、CPU、記憶體、硬碟、顯示屏、……”
房產信息搜尋那就應該抽取出那應該抽取出:類型、地域、地址、房型、面積、裝修情況、租金、聯繫人、聯繫電話公司企業信息搜尋那就應該抽取出:公司名稱、地址、電話、聯繫人。
結構化信息抽取有兩種方式可以實現,比較簡單的是模板方式,還有一種是對網頁不依賴的網頁庫級的結構化信息抽取方式。
模板方式是事先對特定的網頁進行配置模板,抽取模板中設定好的需要的信息,可以針對有限個網站的信息進行精確的採集。
特點:簡單、精確、技術難度低、方便快速部署。
缺點:需要針對每一個信息源的網站模板進行單獨的設定在信息源多樣性的情況下維護量巨大是不可完成的維護量。所以這種方式適合少量信息源的信息處理,不是搜尋引擎級的套用,很難滿足用戶對查全率的需求。
網頁庫結構化信息抽取是採用頁面結構分析與智慧型節點分析轉換的方法,自動抽取結構化的數據。
特點:可對任意的正常網頁進行抽取,完全自動化,不用對具體網站事先生成模板,對每個網頁自動實時得生成抽取規則,完全不需要人工干預。智慧型抽取準確率高,不是機械的匹配,採用智慧型分析技術,準確率能達到98%以上。能保證較快處理速度,由於採用頁面的智慧型分析技術,先去除了垃圾塊,降低分析的壓力,是處理速度大大提高。通用性較好,易於維護,只需設定參數、配置相應的特徵就能改進相應的抽取性能;一般的非專業人員經過簡單培訓就能維護。
缺點:技術難度高,前期研發成本高,周期長。適合網頁庫級別結構化數據採集和搜尋的高端套用。
套用意義
 結構化信息
結構化信息非結構化信息處理類似於20世紀70年代以前的結構化信息套用。割裂、無法進行數據互操作的套用是其主流。以人們最常用的文檔軟體來看,DOC文檔是MSWORD的專用格式,WPS、永中、中文2000等OFFICE產品廠商則各有各的“自留地”。這種情況下,由於文檔格式的束縛而使信息四分五裂,信息流無法通暢流轉,信息處理更加困難,信息資源因為“信息流的不通暢”而喪失了其應有的巨大價值。
從非結構化到半結構化,從半結構化到結構化,從結構化到關聯數據體系,從關聯數據體系到數據挖掘,從數據挖掘到故事化呈現,從故事化呈現到決策導向。
