
基本概念
針對帶有時滯、不確定性的工業過程, 模糊自適應預測控制不需要過程的數學模型,只要線上檢測過程的實際輸出和期望輸出,通過模糊預測控制校正無辨識自適應控制律,即可以對時滯、建模困難的工業過程實現自適應控制。
帶有不確定性工業過程的控制問題一直是困擾控制理論和控制工程實踐的難題,而帶有時滯、不確定性工業過程的控制更加困難。但是不確定、滯後現象是實現工業過程中普遍存在的一種現象,因此對於這類對象控制問題的研究具有重要理論和現實意義。目前對於帶有不確定性對象的控制主要採用自適應控制、魯棒控制等方法,而過程的時滯特性通常用預測控制等方法加以克服,但是這些先進技術都是建立在過程模型確定的基礎上 。
結構
由Marsik和Strejc提出的無辨識自適應控制算法不需要辨識過程參數,只需線上檢測過程實際輸出及期望輸出,這種自適應算法簡單,並且在工業過程控制中己得到成功的套用。
模糊自適應預測控制器中模糊預測的功能是在每個採樣時刻,根據過程實際輸出逼近期望輸出來估計控制系統的性能並修正無辨識自適應控制律。
模糊自適應預測控制器結構圖如下 :
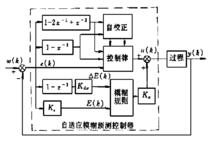 模糊自適應預測控制
模糊自適應預測控制圖1
模糊自適應控制方法
自適應預測控制方法
(1)預測模型
預測控制應具有預測功能,即能夠根據系統的現時刻的控制輸入以及過程的歷史信息,預測過程輸出的未來值,因此,需要一個描述系統動態行為的模型作為預測模型。
在預測控制中的各種不同算法,採用不同類型的預測模型,如最基本的模型算法控制(MAC)採用的是系統的單位脈衝回響曲線,而動態矩陣控制(DMC)採用的是系統的階躍回響曲線。這兩者模型互相之間可以轉換,且都屬於非參數模型,在實際的工業過程中比較容易通過實驗測得,不必進行複雜的數據處理,儘管精度不是很高,但數據冗餘量大,使其抗干擾能力較強。
預測模型具有展示過程未來動態行為的功能,這樣就可像在系統仿真時那樣,任意的給出未來控制策略,觀察過程不同控制策略下的輸出變化,從而為比較這些控制策略的優劣提供了基礎。
(2)反饋校正
在預測控制中,採用預測模型進行過程輸出值的預估只是一種理想的方式,在實際過程中。由於存在非線性、模型失配和干擾等不確定因素,使基於模型的預測不可能準確地與實際相符。因此,在預測控制中,通過輸出的測量值Y(k)與模型的預估值Ym(k)進行比較,得出模型的預測誤差,再利用模型預測誤差來對模型的預測值進行修正。
由於對模型施加了反饋校正的過程,使預測控制具有很強的抗擾動和克服系統不確定性的能力。預測控制中不僅基於模型,而且利用了反饋信息,因此預測控制是一種閉環最佳化控制算法。
(3)滾動最佳化
預測控制是一種最佳化控制算法,需要通過某一性能指標的最最佳化來確定未來的控制作用。這一性能指標還涉及到過程未來的行為,它是根據預測模型由未來的控制策略決定的。
但預測控制中的最佳化與通常的離散最優控制算法不同,它不是採用一個不變的全局最優目標,而是採用滾動式的有限時域最佳化策略。即最佳化過程不是一次離線完成的,而是反覆線上進行的。在每一採樣時刻,最佳化性能指標只涉及從該時刻起到未來有限的時間,而到下一個採樣時刻,這一最佳化時段會同時向前。所以,預測控制不是用一個對全局相同的最佳化性能指標,而是在每一個時刻有一個相對於該時刻的局部最佳化性能指標。
(4)參考軌跡
在預測控制中。考慮到過程的動態特性,為了使過程避免出現輸入和輸出的急劇變化,往往要求過程輸出y(k)沿著一條期望的、平緩的曲線達到設定值r。這條曲線通常稱為參考軌跡y,。它是設定值經過線上“柔化”後的產物。
模糊自適應控制算法
對於隨機過程的動態系統,無法測辨其系統模型而採用模糊控制機制解決這一問題。如圖為模糊自適應控制器結構:
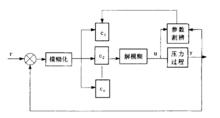 模糊自適應預測控制
模糊自適應預測控制圖2
模糊控制器的基本結構包括知識庫、模糊推理、輸入量模糊化、輸出量精確化四部分。
(1)知識庫
知識庫包括模糊控制器參數庫和模糊控制規則庫。模糊控制規則建立在語言變數的基礎上。語言變數取值為“大”、“中”、“小”等這樣的模糊子集,各模糊子集以隸屬函式表明基本論域上的精確值屬於該模糊子集的程度。因此,為建立模糊控制規則,需要將基本論域上的精確值依據隸屬函式歸併到各模糊子集中,從而用語言變數值(大、中、小等)代替精確值。這個過程代表了人在控制過程中對觀察到的變數和控制量的模糊劃分。由於各變數取值範圍各異,故首先將各基本論域分別以不同的對應關係,映射到一個標準化論域上。通常,對應關係取為量化因子。為便於處理,將標準論域等分離散化,然後對論域進行模糊劃分,定義模糊子集,如NB、PZ、PS等。
同一個模糊控制規則庫,對基本論域的模糊劃分不同,控制效果也不同。具體來說,對應關係、標準論域、模糊子集數以及各模糊子集的隸屬函式都對控制效果有很大影響。這3類參數與模糊控制規則具有同樣的重要性,因此把它們歸併為模糊控制器的參數庫,與模糊控制規則庫共同組成知識庫。
(2)模糊化
將精確的輸入量轉化為模糊量F有兩種方法:
a.將精確量轉換為標準論域上的模糊單點集。
精確量x經對應關係G轉換為標準論域x上的基本元素.
b.將精確量轉換為標準論域上的模糊子集。
精確量經對應關係轉換為標準論域上的基本元素,在該元素上具有最大隸屬度的模糊子集,即為該精確量對應的模糊子集。
(3)模糊推理
最基本的模糊推理形式為:
前提1 IF A THEN B
前提2 IF A′
結論 THEN B′
其中,A、A′為論域U上的模糊子集,B、B′為論域V上的模糊子集。前提1稱為模糊蘊涵關係,記為A→B。在實際套用中,一般先針對各條規則進行推理,然後將各個推理結果總合而得到最終推理結果。
(4)精確化
推理得到的模糊子集要轉換為精確值,以得到最終控制量輸出y。目前常用兩種精確化方法:
a.最大隸屬度法。在推理得到的模糊子集中,選取隸屬度最大的標準論域元素的平均值作為精確化結果。
b.重心法。將推理得到的模糊子集的隸屬函式與橫坐標所圍面積的重心所對應的標準論域元素作為精確化結果。在得到推理結果精確值之後,還應按對應關係,得到最終控制量輸出y。
優勢
基於模糊預測的無辨識自適應控制是一種適合於複雜工業過程控制的有效方法,具有廣闊的套用前景。其優點在於:
(1)控制算法非常簡單,適合於大滯後複雜過程的實時控制。
(2)對控制過程的數學模型沒有任何要求,適合於解決工業過程中難以建立數學模型的複雜對象的控制問題。
對於非線性、不確定的動態系統,採用自適應類控制,可以實時跟蹤受控過程的結構參數和模型參數,以達到自校正控制目吮但這類控制,對過程的數學模型的精度要求較高,大多數的實際控制都難以做到。針對受控過程表現出的“黑箱”特性和“灰箱”特性,採用模糊控制方案,可以克服自適應類控制的缺陷。控制算法是基於自適應採樣控制,這也同時保持了參數跟蹤特性,使得控制性能得到最佳化所給的算法簡潔實用,且易於實現,適合於大多數工業過程控制採用 。
