研究現狀
預測控制
始於20世紀70年代的模型預測控制,經歷了模型預測控制搜尋(MPHC),動態矩陣控制(DMC),廣義預測控制(GPC),和其他一些重要的里程碑。由於預測控制有多步預測、滾動最佳化和反饋校正機制,它可以克服過程模型的不確定性,體現出色的操控性能,在工業過程控制中套用成功,成為一個重要的先進控制方法。預測控制的參數化模型,容易和自校正控制結合,通過引入不相等的預測和控制步長,形成自適應預測控制,從而減少了計算量,使系統的設計更加靈活,工程套用更方便。
近年來,預測控制的理論和套用有著相當大的進展,出現了各種實用的方法。自動化產品商家,如殼牌公司,霍尼韋爾公司等許多製造商,都對他們的DCS集散控制系配備了商業預測控制方案,並將其廣泛套用於石油、化工、冶金等行業。但是,一些複雜的非線性工業控制過程中使用的線性模型預測控制器,基木上不能達到理想的效果。並且由於未知性質、時變、隨機突變等原因,往往複雜的工業過程中的結構和參數,有不完整的信息、不確定大純滯後和非線性等因素,簡單預測控制算法似乎是不夠的。對現代工業生產過程的要求發展越來越高,往往不只需要一個生產單元達到最佳的控制,還希望能在多個生產環節實現控制和最佳化的整個過程,以追求提高產品質量和降低成木。這些現實問題需要預測控制引入新思路,新方法,追求更高層次目標的發展。
在另一方面,研究智慧型控制的成果從1990年以來大量湧現。智慧型控制不僅在複雜的系統(如非線性,快時變的,複雜的數量,環境擾動等)中可以得到有效控制處理,而且還具有學習能力、組織能力、適應能力和最佳化能力。因此,預測控制與智慧型手段結合成一種新的研究方法。智慧型預測控制解決複雜工業過程的不確定性和多目標最佳化問題具有十分重要的意義。
為了解決複雜工業過程的不確定性、多目標等問題,國內外學者引入智慧型控制方法到預測控制中,使其向智慧型化的方向發展,從而形成了目前預測控制研究的一個方向—智慧型預測控制。智慧型預測控制方法的內容是非常豐富的,具體的算法層出不窮。根據預測控制和智慧型控制融合點,大致可分為以下幾類:
(1)模糊預測控制
預測控制和模糊控制是控制理論中兩個獨立開發的區域,根據兩者的思想而全面發展的模糊預測控制有其內在的合理性:預測控制和模糊控制都是對不確定系統的有效控制方法,結合模糊及預測控制會進一步提高效果;模糊控制的發展趨勢是規則溝通模型的改變,預測控制對象的模型,可作為雙方的橋樑,因此,模糊預測控制的研究能擴大預測控制的套用範圍。
(2)基於神經網路的預測控制
自80年代中期,人工神經網路以其獨特的優勢引起了極大關注。對於控制領域,神經網路的吸引力在於:充分逼近複雜的非線性關係:能夠學習和適應不確定系統的動態特性;所有定量或定性的信息被存儲在單個神經元的分散式網路,所以有魯棒性和容錯性;利用並行分布處理方法,使得它可以快速地計算密集型的數據。這些特性使其成為非線性系統建模與控制的重要方法。因為神經網路在求解非線性系統方面的巨大優勢,很快就在預測控制中使用,並且形成許多不同的算法。崔鍾泰等人(2004)提出了一種基於模糊神經網路控制的混沌非線性系統預測模型,夏曉華等(2005)提出了一種基於小波神經網路的預測控制,宮赤坤等(2005)提出了一種基於RBF神經網路的預測控制。
(3)基於遺傳算法的預測控制
雖然遺傳算法被廣泛認為是一個具有很強魯棒性、可以處理大規模複雜問題的最佳化算法。隨著社會和電腦本身的計算速度不斷進步,遺傳算法不斷改進,近年來開始被引入到非線性模型預測控制的線上最佳化。張強和李韶遠(2004)用遺傳算法解決了存在約束最佳化問題的廣義預測控制,實現了基於遺傳算法的廣義預測控制算法,同時對工業過程對象進行仿真,驗證了該方法的有效性和良好的控制效果。Naeem. W.等(2005)設計了一種基於線上調整遺傳算法的模型預測控制,並套用於水下機器人。
自適應控制
自20世紀50年代末,美國麻省理工學院提出第一個自適應控制系統以來,世界上己經出現許多不同形式的自適應控制系統。自校正調節器是一類比較成熟的自適應控制系統。
自校正調節器發展的第一階段是1958年至1975年。1958年,Kalman發表的一篇文章一最優控制系統設計,首先提出了自校正控制的思想。在1970年,Petra把這個原理延伸到參數未知但恆定的線性離散時間單輸入輸出系統。由於理論和技術的限制,這些原理並沒有得到成功套用。直到1973年由瑞典學者Astorm和Wiittenmark提出最小方差自校正調節器。該方法的突出優點是容易實現,即使只用一個單板微處理器就能夠實現,它的缺點是,該系統不能用於不穩定系統,存在工程上的限制,並且結構簡單。
為了解決這個問題,在1975年克拉克提出廣義最小方差控制,自校正調節器的主要缺點都被它克服,從而獲得了廣泛的關注。然而,該算法是不穩定的,當用逆系統處理,控制權必須在目標函式中選擇。因為不確定性,控制權的選擇往往要依靠試錯法。第二階段是1976年至1980年。1976年,劍橋大學茲大學提出極點配置自校正技術,Wellstead, Prager, Zanker和Sanoff,做出卓有成效的工作。除了最優性,其他方面均超過上述自校正控制器,但自校正結構太複雜。第三階段是1980年至今。80年代來,在神經網路基礎上,自校正控制器快速發展,並顯示出其在高度非線性和不確定系統中控制的巨大的潛力。
神經網路自適應控制理論是自適應控制理論和神經網路相結合的產物,神經網路具有很強的逼近非線性函式的能力,即非線性映射能力,把神經網路用於控制正是利用了其獨特的優勢能力。神經網路模型能模擬人腦神經元的活動過程,包括信息加工、處理、存儲和搜尋的過程,它具有以下特性:
(1)信息分散式存儲在神經網路中,即使局部網路被破壞,仍然可以恢復原始信息;
(2)神經網路平行地處理和推斷信息,每個神經元可以基於所接收的信息獨立計算和處理,然後將結果輸出;
(3)神經網路處理信息具有自組織、自學習特性。
現在神經網路自適應控制方案已經出現很多,其中典型的控制程式有神經網路模型參考自適應控制(NNMRAC)等。使用NNMRAC直接結構,基於穩定性理論選擇控制律,提高仿射非線性系統的跟蹤精度,並使全閉環系統漸近穩定。使用自適應神經網路間接結構,首先由神經網路離線識別前饋控制過程模型,然後線上學習和修改。
自適應神經網路控制需要神經網路線上學習,所以學習速度是一個關鍵問題。現有的自適應神經控制器採用BP算法,所以一般運行速度較慢,因此如何提高線上自適應神經控制速度,是目前研究的熱點之一。
自適應控制
概述
自適應控制的研究對象是具有一定程度不確定性的系統,這裡所謂的“不確定性”是指描述被控對象及其環境的數學模型不是完全確定的,其中包含一些未知因素和隨機因素。
任何一個實際系統都具有不同程度的不確定性,這些不確定性有時表現在系統內部,有時表現在系統的外部。從系統內部來講,描述被控對象的數學模型的結構和參數,設計者事先並不一定能準確知道。作為外部環境對系統的影響,可以等效地用許多擾動來表示。這些擾動通常是不可預測的。此外,還有一些測量時產生的不確定因素進入系統。面對這些客觀存在的各式各樣的不確定性,如何設計適當的控制作用,使得某一指定的性能指標達到並保持最優或者近似最優,這就是自適應控制所要研究解決的問題。
自適應控制和常規的反饋控制和最優控制一樣,也是一種基於數學模型的控制方法,所不同的只是自適應控制所依據的關於模型和擾動的先驗知識比較少,需要在系統的運行過程中去不斷提取有關模型的信息,使模型逐步完善。具體地說,可以依據對象的輸入輸出數據,不斷地辨識模型參數,這個過程稱為系統的線上辯識。隨著生產過程的不斷進行,通過線上辯識,模型會變得越來越準確,越來越接近於實際。既然模型在不斷的改進,顯然,基於這種模型綜合出來的控制作用也將隨之不斷的改進。在這個意義下,控制系統具有一定的適應能力。比如說,當系統在設計階段,由於對象特性的初始信息比較缺乏,系統在剛開始投入運行時可能性能不理想,但是只要經過一段時間的運行,通過線上辯識和控制以後,控制系統逐漸適應,最終將自身調整到一個滿意的工作狀態。再比如某些控制對象,其特性可能在運行過程中要發生較大的變化,但通過線上辯識和改變控制器參數,系統也能逐漸適應。
常規的反饋控制系統對於系統內部特性的變化和外部擾動的影響都具有一定的抑制能力,但是由於控制器參數是固定的,所以當系統內部特性變化或者外部擾動的變化幅度很大時,系統的性能常常會大幅度下降,甚至是不穩定。所以對那些對象特性或擾動特性變化範圍很大,同時又要求經常保持高性能指標的一類系統,採取自適應控制是合適的。但是同時也應當指出,自適應控制比常規反饋控制要複雜的多,成本也高的多,因此只是在用常規反饋達不到所期望的性能時,才會考慮採用。
系統的功能及特點
自適應控制系統的研究劉一象有著不確定性,其中“不確定性”的意思是指被控對象和它的環境是不完全確定的數學模型。這種不確定性主要表現在:現代工業設備和工藝的複雜性,使得模擬系統的數學模型與實際系統總有差異,得到的數學模型是近似的;該系統的自身結構和參數是未知或時變的;外部環境的干擾是不可避免的,作用在系統上的干擾常常是隨機的,無法測量;控制對象的特性隨時間或工作環境的變化而改變,並且它的變化難以預料。
對於一個不確定性控制系統,,如何設計一個良好的控制器是自適應控制有待研究的問題。在日常的生活中,生物可以通過有意識地改變自己的習慣調整自己的參數,以適應新的環境特點,成為自適應控制器思想的主要參考依據。自適應控制器應能及時修改它們的特性,以適應對象和其擾動的動態變化特徵,整個控制系統總有令人滿意的性能。因此,自適應控制方法就是依靠對控制對象的信息連續採集並處理,確定當前的實際運行狀態,按照一定的性能標準,產生適當的自適應控制律,用以實時地調整控制結構或參數,該系統總是自動地在最佳或次最佳的操作條件下工作。
預測控制
算法框圖
雖然預測控制有許多算法,一般的意義上說,它們的原理都是一樣的,算法框圖如圖所示:
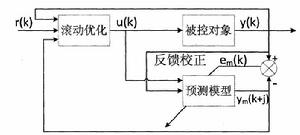 自適應預測控制
自適應預測控制三個基本原則
(1)預測模型
預測控制是一種基於模型的控制算法,該模型被稱為預測模型。對於預測控制而言,只注重模型功能,而不是模型的形式。預測模型是基於對象的歷史信息和輸入,預測其未來的輸出。從方法論的角度來看,只要信息的收集具有預測功能,無論什麼樣的表現,可以作為預測模型。這樣的狀態方程、模型傳遞函式都可以用來作為一個傳統的預測模型。例如線性穩定對象,甚至階躍回響、脈衝回響的非參數模型,,都可直接作為預測
模型。此外,非線性系統,分散式參數系統模型,只要具備上述功能也可以在這樣的預測控制系統中時用來作為預測模型。因此,預測控制打破了嚴格的控制模型結構的傳統要求,可按照功能要求根據最方便的信息集中方式基礎建模。在這種方式中,可以使用預測模型為預測控制進行最佳化,.以提供的先驗知識來確定什麼樣的控制輸入,從而使下一次受控對象的輸出變化與預定的目標行一致。
(2)滾動最佳化
預測控制是一種基於最佳化的控制,但其控制的輸入不是根據模型和性能指標一次解決並實現它,而是在實時的時間裡來滾動最佳化解決。在每一步的控制中,定義從目前到未來有限時域的最最佳化問題,通過參數最佳化求解時域的最優控制輸入,但是只有真正的即時輸入控制才給予實現。到下一個控制周期,重複上述步驟,整個最佳化領域向前一步滾動。在每個採樣時刻,最佳化性能指標只涉及從現在到未來有限的時間,並且下一個採樣時刻,最佳化時段向前推移。因此,預測控制全局最佳化指標是不一樣的,在每一個時刻有一個相對該時刻的最佳化指標。因此,預測控制的最佳化不是一次離線進行,而是線上反覆進行,這是滾動最佳化的意義,預測控制的這一點也是不同於傳統最優控制的根本。
(3)反饋校正
基礎的預測模型中,對象的動態特性只有粗略的描述,由於實際系統中有非線性、時變、模型不匹配、干擾等因素,基於相同模型的預測,與實際情況是無法完全匹配的,這需要用其他手段補充預測模型和實際對象的誤差,或對基礎模型進行校正。滾動最佳化只有建立在反饋校正的基礎上,才能體現其優越性。因此,通過預測控制算法的最佳化,確定一系列未來的控制作用,為了防止模型失配或環境干擾引起的控制措施對理想狀態造成的影響,這些控制沒有完全逐一實現,只實現即時控制作用。到下一個採樣時間,首先監測對象的實際輸出,並使用此信息在預測模型的基礎上進行實時校正,然後進行新的最佳化。因此,預測控制最佳化不僅基於模型,並使用了反饋信息,從而構成一個閉環最佳化。
基本特徵
(1)預測控制算法利用過去,現在和未來(預測模型)的信息,而傳統的算法,如PID等,只取過去和現在的信息;
(2)對模型要求低,現代控制理論難以大規模套用於過程工業,重要原因之一就是對模型精度過於苛刻,預測控制成功地克服這一點;
(3)模型預測控制算法具有全局滾動最佳化,每個控制周期持續的最佳化計算,不僅在時間上滿足實時性要求,還通過全局最佳化打破傳統局限,組合了穩定最佳化和動態最佳化;
(4)用多變數控制思想來取代單一的可變控制傳統手段。因此,在套用到多變數的問題時,預測控制通常被稱為多變數預測控制;
(5)最重要的是能有效地處理約束。因為在實際生產中,通常將製造過程工藝設備的狀態設定為在邊界條件(安全邊界,設備功能邊界,工藝條件邊界等)上操作,該操作狀態下,操作變數往往產生飽和以及被控變數超出約束的問題。所以可以處理多個目標,有約束控制能力成為一個控制系統長期、穩定和可靠運行的關鍵技術。
種類
1978年,Richalet等首先闡述了預測控制的思想,預測控制是以模型為基礎,採用二次線上滾動最佳化性能指標和反饋校正的策略,來克服受控對象建模誤差和結構、參數與環境等不確定因素的影響,有效的彌補了現代控制理論對複雜受控對象所無法避免的不足之處。
預測控制自發展以來,算法種類非常繁多,但按其基本結構形式,大致可以分為三類:
(I)由Cutler等人提出的以非參數模型為預測模型的動態矩陣控制(Dynamic Matrix Control, DMC), Rauhani等人提出的模型算法控制(Model Algorithmic Control,MAC).這類非參數模型建模方便,只需通過受控對象的脈衝回響或階躍回響測試即可得到,無須考慮模型的結構與階次,系統的純滯後必然包括在回響值中。其局限性在於開環自穩定對象,當模型參數增多時,控制算法計算量大。
(2)與經典的自適應控制相結合的一類長程預測控制算法(Generalized Predictive Control, GPC).這一類基於辨識模型並且有自校正的預測控制算法,以長時段多步最佳化取代了經典的最小方差控制中的一步預測最佳化,從而適用於時滯和非最小相位對象,並改善了控制性能,具有良好的魯棒性。
(3)基於機構設計不同的另一類預測控制算法:包括由Garcia提出的內模控制(Internal Model Control, IMC), Brosilow等人提出的推理控(Inference Control)等。這類算法是從結構上研究預測控制的一個獨特分支。
以上述典型預測控制為基礎結合近幾年發展起來的各種先進控制策略,形成了一些先進的預測控制算法,包括極點配置預測控制、解禍預測控制、前饋補償預測控制、自適應預測控制,魯棒預測控制等。本文重點研究自適應預測控制,即基於自適應雙重控制的預測控制算法。
另外,諸如模糊預測控制,神經網路預測控制等智慧型預測控制算法的發展為解決複雜受控系統提供了強有力的支持。
許多新型的預測控制層出不窮,如預測函式控制、多速率採樣預測控制、多模型切換預測控制,有約束預測控制等。預測控制的算法種類越來越多,預測控制的性能在不斷改善,使其更好的套用在工業實際中。
無模型自適應預測控制
對未知非線性系統,研究綜合利用預測控制和無模型自適應控制各自優點的無模型自適應預測控制(Model Free Adaptive Predictive Control, MFAPC),也就是說,研究僅利用閉環系統I/O數據的非線性系統的預測控制方法,實現對某些無法獲取較精確數學模型的被控系統的穩定控制,對於非線性系統控制理論的發展和將理論在工業控制中實踐都非常重要。
利用等價的動態線性化數據模型方法,結合不同預測控制設計思想,可以給出不的預測控制方法,如無模型自適應控制與函式預測控制相結合的無模型自適應函式預測控制方法、無模型自適應控制與PI控制相結合的無模型自適應預測PI控制方法、無模型自適應控制與動態矩陣控制相結合的無模型自適應動態矩陣預測控制等。這些方法目前僅處於部分被控對象的實驗仿真階段,但都取得了良好的實驗結果。無模型自適應預測控制算法,綜合了無模型自適應控制的僅利用被控系統輸入輸出數據不需建立被控系統模型,和預測控制的預測未來時刻的輸入輸出的特點,是一種數據驅動的非線性系統自適應預測控制方法,與己有的基於模型的自適應預測控制方法相比,具有更強的魯棒性和更廣泛的可套用性。
