簡介
漸進分析法最常用的表示方法是用於描述函式漸近行為的數學符號,更確切地說,它是用另一個(通常更簡單的)函式來描述一個函式數量級的 漸近上界。大O符號是由德國數論學家保羅·巴赫曼(Paul Bachmann)在其1892年的著作《解析數論》( Analytische Zahlentheorie)首先引入的。
我們常用大O表示法表示時間複雜度,注意它是某一個算法的時間複雜度。大O表示只是說有上界,由定義如果f(n)=O(n),那顯然成立f(n)=O(n^2),它給你一個上界,但並不是上確界,但人們在表示的時候一般都習慣表示前者。此外,一個問題本身也有它的複雜度,如果某個算法的複雜度到達了這個問題複雜度的下界,那就稱這樣的算法是最佳算法。
通常我們需要一種方法來對不同的算法來進行比較,一般來說,解決同樣的問題有多種算法,那么在不同的客觀條件下如何對不同的算法進行取捨呢?
算法的目標
容易理解
編碼和調試
優秀的算法通常是簡潔而清晰的,這樣帶來的直接好處就是易於編碼和理解,同時這樣算法也必定是健壯的,如果一個算法晦澀難懂,則很可能其中會隱藏較多的錯誤。
最小的代價
算法的代價的最小化是指其執行時間最短且占用的存儲空間最少,它們之間 往往是相互矛盾的,然而一般而言,算法的執行時間是主要的評價標準。
算法的執行時間
算法的執行時間等於它所有基本操作執行時間之和, 而一條基本操作的執行時間等於它執行的次數和每一次執行的時間的積,
如下:
算法的執行時間 = 操作1 + 操作2 + ... + 操作n
操作的執行時間 = 操作執行次數 X 執行一次的時間
然而存在一個問題,不同的程式語言,不同的編譯器,或不同的CPU等因素將導致執行一次操作的時間各不相同,這樣的結果會使算法的比較產生歧義, 於是我們假定所有計算機執行相同的一次基本操作所需時間相同,而把算法中基本操作所執行的最大次數作為量度。就是說我們把算法的執行時間簡單地用基本操作的執行次數來代替了。
那么除此之外,基本操作是什麼? 它可以是基本運算,賦值,比較,交換等,如在排序中,基本操作指的是元素的比較及交換。而線上性查找中,它是數據的比較。
時間複雜度和大O表示法
當問題規模即要處理的數據增長時, 基本操作要重複執行的次數必定也會增長, 那么我們關心地是這個執行次數以什麼樣的數量級增長。所謂數量級可以理解為增長率。這個所謂的數量級就稱為算法的漸近時間複雜度(asymptotic time complexity), 簡稱為時間複雜度。如何分析這個數量級呢? 由於基本操作的執行次數是問題規模n 的一個函式T(n), 所以問題就是我們要確定這個函式T(n)是什麼, 然後分析它的數量級, 擁有相同數量級的函式 f(n) 的集合表示為 O(f(n)), O是數量級的標記。如果T(n)的數量級和f(n)相同,
顯然T(n) ∈ Of(n)。這個函式的值表示當我要處理的數據量增長時,基本操作執行次數以什麼樣的比例增長。即n增長時,T(n)增長多少?
例子
首先看一個簡單的示例:
分析:
⒈
語句int num1,num2;的頻度為1;
語句i=0;的頻度為1;
語句i<n; i++; num1+=1; j=1; 的頻度為n;
 大O表示法 大O表示法
大O表示法 大O表示法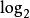 大O表示法
大O表示法語句j<=n;j =2; num2+=num1;的頻度為n n;
大O表示法 大O表示法T(n) = 2 + 4n +3n n
⒉
忽略掉T(n)中的常量、低次冪和最高次冪的係數
大O表示法f(n) = n* n
⒊
大O表示法 大O表示法lim(T(n)/f(n)) = (2+4n+3n* n) / (n* n)
大O表示法 大O表示法= 2*(1/n)*(1/ n) + 4*(1/ n) + 3
大O表示法當n趨向於無窮大,1/n趨向於0,1/ n趨向於0
所以極限等於3。
大O表示法T(n) = O(n* n)
簡化的計算步驟
再來分析一下,可以看出,決定算法複雜度的是執行次數最多的語句,這裡是num2 += num1,一般也是最內循環的語句。
並且,通常將求解極限是否為常量也省略掉?
於是, 以上步驟可以簡化為:
⒈ 找到執行次數最多的語句
⒉ 計算語句執行次數的數量級
⒊ 用大O來表示結果
繼續以上述算法為例,進行分析:
⒈
執行次數最多的語句為num2 += num1
⒉
T(n) = n*log2n
f(n) = n*log2n
⒊
// lim(T(n)/f(n)) = 1
T(n) = O(n*log2n)
--------------------------------------------------------------------------------
一些補充說明
最壞時間複雜度
算法的時間複雜度不僅與語句頻度有關,還與問題規模及輸入實例中各元素的取值有關。一般不特別說明,討論的時間複雜度均是最壞情況下的時間複雜度。這就保證了算法的運行時間不會比任何更長。
求數量級
即求對數值(log),默認底數為10,簡單來說就是“一個數用標準科學計數法表示後,10的指數”。例如,5000=5x10 3 (log5000=3) ,數量級為3。另外,一個未知數的數量級為其最接近的數量級,即最大可能的數量級。
求極限的技巧
要利用好1/n。當n趨於無窮大時,1/n趨向於0
--------------------------------------------------------------------------------
一些規則(引自:時間複雜度計算)
1) 加法規則
T(n,m) = T1(n) + T2(n) = O (max (f(n),g(m))
2) 乘法規則
T(n,m) = T1(n) * T2(m) = O (f(n) * g(m))
3) 一個特例(問題規模為常量的時間複雜度)
在大O表示法裡面有一個特例,如果T1(n) = O(c), c是一個與n無關的任意常數,T2(n) = O (f(n)) 則有
T(n) = T1(n) * T2(n) = O (c*f(n)) = O(f(n))
也就是說,在大O表示法中,任何非0正常數都屬於同一數量級,記為O⑴。
4) 一個經驗規則
複雜度與時間效率的關係:
c < log2n < n < n*log2n < n2 < n3 < 2n < 3n < n! (c是一個常量)
|--------------------------|--------------------------|-------------|
較好 一般 較差
其中c是一個常量,如果一個算法的複雜度為c 、 log2n 、n 、 n*log2n,那么這個算法時間效率比較高 ,如果是 2n,3n,n!,那么稍微大一些的n就會令這個算法不能動了,居於中間的幾個則差強人意。
--------------------------------------------------------------------------------------------------
複雜情況的分析
以上都是對於單個嵌套循環的情況進行分析,但實際上還可能有其他的情況,下面將例舉說明。
⒈並列循環的複雜度分析
將各個嵌套循環的時間複雜度相加。
例如:
for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++;
解:
第一個for循環
T(n) = n
f(n) = n
時間複雜度為Ο(n)
第二個for循環
T(n) = n2
f(n) = n2
時間複雜度為Ο(n2)
整個算法的時間複雜度為Ο(n+n2) = Ο(n2)。
⒉函式調用的複雜度分析
例如:
public void printsum(int count){
int sum = 1;
for(int i= 0; i<n; i++){
sum += i;
}
System.out.print(sum);
}
分析:
記住,只有可運行的語句才會增加時間複雜度,因此,上面方法裡的內容除了循環之外,其餘的可運行語句的複雜度都是O⑴。
所以printsum的時間複雜度 = for的O(n)+O⑴ = 忽略常量 = O(n)
*這裡其實可以運用公式 num = n*(n+1)/2,對算法進行最佳化,改為:
public void printsum(int count){
int sum = 1;
sum = count * (count+1)/2;
System.out.print(sum);
}
這樣算法的時間複雜度將由原來的O(n)降為O⑴,大大地提高了算法的性能。
⒊混合情況(多個方法調用與循環)的複雜度分析
例如:
public void suixiangMethod(int n){
printsum(n);//1.1
for(int i= 0; i<n; i++){
printsum(n); //1.2
}
for(int i= 0; i<n; i++){
for(int k=0; k<n;k++){
System.out.print(i,k); //1.3
}
}
suixiangMethod 方法的時間複雜度需要計算方法體的各個成員的複雜度。
也就是1.1+1.2+1.3 = O⑴+O(n)+O(n2) ----> 忽略常數 和 非主要項 == O(n2)
--------------------------------------------------------------------------------------------------
更多的例子
O⑴
交換i和j的內容
temp=i;
i=j;
j=temp;
以上三條單個語句的頻度為1,該程式段的執行時間是一個與問題規模n無關的常數。算法的時間複雜度為常數階,記作T(n)=O⑴。如果算法的執行時間不隨著問題規模n的增加而增長,即使算法中有上千條語句,其執行時間也不過是一個較大的常數。此類算法的時間複雜度是O⑴。
O(n2)
sum=0; /* 執行次數1 */
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
sum++; /* 執行次數n2 */
解:T(n) = 1 + n2 = O(n2)
for (i=1;i<n;i++)
{
y=y+1; ①
for (j=0;j<=(2*n);j++)
x++; ②
}
解:語句1的頻度是n-1
語句2的頻度是(n-1)*(2n+1) = 2n2-n-1
T(n) = 2n2-n-1+(n-1) = 2n2-2
f(n) = n2
lim(T(n)/f(n)) = 2 + 2*(1/n2) = 2
T(n) = O(n2).
O(n)
a=0;
b=1; ①
for (i=1;i<=n;i++) ②
{
s=a+b; ③
b=a; ④
a=s; ⑤
}
解:語句1的頻度:2,
語句2的頻度:n,
語句3的頻度:n,
語句4的頻度:n,
語句5的頻度:n,
T(n) = 2+4n
f(n) = n
lim(T(n)/f(n)) = 2*(1/n) + 4 = 4
T(n) = O(n).
O(log2n)
i=1; ①
while (i<=n)
i=i*2; ②
解:語句1的頻度是1,
設語句2的頻度是t,則:2^t<=n; t<=log2n
考慮最壞情況,取最大值t=log2n,
T(n) = 1 + log2n
f(n) = log2n
lim(T(n)/f(n)) = 1/log2n + 1 = 1
T(n) = O(log2n)
O(n3)
for(i=0;i<n;i++)
{
for(j=0;j<i;j++)
{
for(k=0;k<j;k++)
x=x+2;
}
}
解:當i=m,j=k的時候,內層循環的次數為k當i=m時,j 可以取 0,1,...,m-1,所以這裡最內循環共進行了0+1+...+m-1=(m-1)m/2次所以,i從0取到n,則循環共進行了: 0+(1-1)*1/2+...+(n-1)n/2=n(n+1)(n-1)/2次
T(n) = n(n+1)(n-1)/2 = (n3-n)/2
f(n) = n3
所以時間複雜度為O(n3)。
拓展
定義一:Θ(g(n))={f(n) | 如果存在正常數c1、c2和正整數n0,使得當n>=n0時,0<c1g(n)<=f(n)<=c2g(n)恆成立}
定義二:Ο(g(n))={f(n) | 如果存在正常數c和正整數n0,使得當n>=n0時,0<=f(n)<=cg(n)恆成立}
定義三:Ω(g(n))={f(n) | 如果存在正常數c和正整數n0,使得當n>=n0時,0<=cg(n)<=f(n)恆成立}
