機器學習
 機器學習和數據挖掘
機器學習和數據挖掘根據訓練數據的類型和變化,機器學習可以大致分為三個框架:監督學習,無監督學習和強化學習。 多實例學習(MIL)屬於監督學習框架,其中每個訓練實例都具有離散或實值的標籤。 MIL處理訓練集中標籤知識不完整的問題。 更準確地說,在多實例學習中,訓練集由標記為“包”組成,每個包都是未標記實例的集合。 如果袋子中的至少一個是陽性,則袋子被正面標記,如果袋子中的所有實例都是陰性,則袋子被貼上標籤。 MIL的目標是預測新的,看不見的袋子的標籤。
歷史
Keeler等人在他20世紀90年代早期的工作中是第一個探索MIL領域的人。實際術語多實例學習是在20世紀90年代中期由Dietterich等人引入的。他們正在調查藥物活動預測的問題。他們試圖創建一種學習系統,通過分析已知分子的集合,可以預測新分子是否有資格製造某種藥物。分子可以具有許多替代的低能狀態,但是只有一種或一些能夠製造藥物。之所以出現這個問題,是因為科學家們只能確定分子是否合格,但是他們無法確切地說出其低能量形狀究竟是由哪種原因造成的。
提出的解決這個問題的方法之一是使用有監督的學習,並將合格分子的所有低能量形狀視為正向訓練實例,而將不合格分子的所有低能量形狀視為負實例。 Dietterich等。表明這種方法會產生很高的假陽性噪聲,從所有被錯誤標記為陽性的低能量形狀,因此並沒有真正有用 。他們的方法是將每個分子視為標記袋,並將該分子的所有替代低能量形狀視為袋中的實例,沒有單獨的標籤。從而制定多實例學習。
解決Dietterich等人的多實例學習問題。提出了三軸平行矩形(APR)算法。它試圖搜尋由特徵結合構造的適當的軸平行矩形。他們在Musk數據集上測試了算法,這是藥物活動預測的具體測試數據,也是多實例學習中最常用的基準。 APR算法取得了最好的結果,但應該注意到APR的設計考慮了Musk數據。
多實例學習的問題不是藥物發現所特有的。 1998年,Maron和Ratan發現了多實例學習在機器視覺中進行場景分類的另一種套用,並設計了Diverse Density框架。給定圖像,實例被視為一個或多個固定大小的子圖像,並且實例包被視為整個圖像。如果圖像包含目標場景(例如瀑布),則標記為正圖像,否則為負圖像。可以使用多實例學習來學習表征目標場景的子圖像的屬性。從那時起,這些框架已經套用於廣泛的套用,從圖像概念學習和文本分類到股票市場預測。
特徵
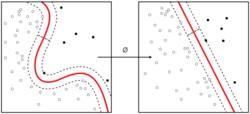
多示例學習中,定義“包”為多個示例的集合。與其他Classification方法不同,此方法僅對“包”作標籤,“包”中的示例並無標籤。定義“正包”:包中至少有一個正示例;反之,若且唯若“包”中所有示例為負示例時,該“包”為“負包”。
多示例學習的目的:①歸納出單個示例的標籤類別的概念。②計算機通過對這些已標註的“包”學習,儘可能準確地對新的“包”的標籤做出判斷。
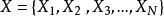 多示例學習
多示例學習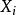 多示例學習
多示例學習我們就拿圖像分類舉個例子:圖像分類是基於圖像內容來確定圖像目標的類別。例如:一張圖片上存在“sand”、"water"等各種示例,我們研究的目標是"beach"。在多示例學習中,一張圖像作為一個“包”: 。 是特徵向量(也就是我們所說的示例),是從圖像中對應的第i個區域中提取出來的,總共存在N個示例區域。那么,“包”中若且唯若"sand"和"water"都存在時,此“包”才會作上“beach”標籤。顯然,利用這種方法來研究圖像分類就考慮到了圖像中元素之間關係,相比單示例方法在某些情況下得出的分類效果更好。
多示例學習方法是20世紀90年代人們在研究藥物活性時提出來的。1997年,T. G. Dietterich 等人對藥物活性預測問題進行了研究。其目的是構建一個學習系統,通過對已知適於或不適於製藥的分子進行學習,儘可能正確地預測其他新的分子是否適合製藥。由於每個分子都有很多種可能的穩定同分異構體共存,而生物化學家只知道哪些分子適於製藥,並不知道其中的哪一種同分異構體起到了決定性作用。如果使用傳統的有監督學習的方法,將適合製藥的分子的所有穩定同分異構體作為正樣本顯然會引入很多噪聲。因此,提出來多示例學習的問題。
多示例學習自提出十幾年以來,一直成為研究的熱點。從最初T. G. Dietterich等人提出該方法時給出的三個基於軸平行矩形的方法,到後來的DD、EMDD、Citation-kNN,以及SVM、神經網路、條件隨機場方法在多示例學習中的運用。
多示例學習具有廣泛的套用,例如:圖像檢索、文本分類等。
