
算法原理
冒泡排序算法的原理如下:
1.比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。
2.對每一對相鄰元素做同樣的工作,從開始第一對到結尾的最後一對。在這一點,最後的元素應該會是最大的數。
3.針對所有的元素重複以上的步驟,除了最後一個。
4.持續每次對越來越少的元素重複上面的步驟,直到沒有任何一對數字需要比較。
算法分析
時間複雜度
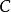 冒泡排序
冒泡排序 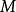 冒泡排序
冒泡排序  冒泡排序
冒泡排序  冒泡排序
冒泡排序 若檔案的初始狀態是正序的,一趟掃描即可完成排序。所需的關鍵字比較次數 和記錄移動次數 均達到最小值: , 。
 冒泡排序
冒泡排序 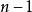 冒泡排序
冒泡排序 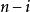 冒泡排序
冒泡排序 所以,冒泡排序最好的時間複雜度為
。若初始檔案是反序的,需要進行趟排序。每趟排序要進行次關鍵字的比較(1≤i≤n-1),且每次比較都必須移動記錄三次來達到交換記錄位置。在這種情況下,比較和移動次數均達到最大值:
 冒泡排序
冒泡排序  冒泡排序
冒泡排序  冒泡排序
冒泡排序 冒泡排序的最壞時間複雜度為 。
冒泡排序 綜上,因此冒泡排序總的平均時間複雜度為 。
算法穩定性
冒泡排序就是把小的元素往前調或者把大的元素往後調。比較是相鄰的兩個元素比較,交換也發生在這兩個元素之間。所以,如果兩個元素相等,是不會再交換的;如果兩個相等的元素沒有相鄰,那么即使通過前面的兩兩交換把兩個相鄰起來,這時候也不會交換,所以相同元素的前後順序並沒有改變,所以冒泡排序是一種穩定排序算法。
算法描述
Visual Fox Pro語言
Python3
Swift
C++
C++語言程式示例如下
RUBY
PHP
C#語言
Erlang
C語言
c語言程式示例如下
JAVA
JavaScript
控制台將輸出:[1, 2, 3, 4, 5, 6, 7, 8, 9]
並且彈窗;
