
簡介
Big Data大數據,談的不僅僅是數據量,其實包含數據量(Volume)、時效性(Velocity)、多樣性(Variety)、可疑性(Veracity):
Volume:數據量大量數據的產生、處理、保存,談的就是Big Data就字面上的意思,就是談海量數據。
Velocity:時效性這個詞我有看到幾個解釋,但我認為用IBM的解釋來說是比較恰當的,就是處理的時效,既然前頭提到Big Data其中一個用途是做市場預測,那處理的時效如果太長就失去了預測的意義了,所以處理的時效對Big Data來說也是非常關鍵的,500萬筆數據的深入分析,可能只能花5分鐘的時間。
Variety:多變性指的是數據的形態,包含文字、影音、網頁、串流等等結構性、非結構性的數據。
Veracity:可疑性指的是當數據的來源變得更多元時,這些數據本身的可靠度、質量是否足夠,若數據本身就是有問題的,那分析後的結果也不會是正確的。
Big Data技術綜述
Big Data是近來的一個技術熱點,但從名字就能判斷它並不是什麼新詞。畢竟,大是一個相對概念。歷史上,資料庫、數據倉庫、數據集市等信息管理領域的技術,很大程度上也是為了解決大規模數據的問題。被譽為數據倉庫之父的Bill Inmon早在20世紀90年代就經常將Big Data掛在嘴邊了。
然而,Big Data作為一個專有名詞成為熱點,主要應歸功於近年來網際網路、雲計算、移動和物聯網的迅猛發展。無所不在的移動設備、RFID、無線感測器每分每秒都在產生數據,數以億計用戶的網際網路服務時時刻刻在產生巨量的互動……要處理的數據量實在是太大、增長太快了,而業務需求和競爭壓力對數據處理的實時性、有效性又提出了更高要求,傳統的常規技術手段根本無法應付。
在這種情況下,技術人員紛紛研發和採用了一批新技術,主要包括分散式快取、基於MPP的分散式資料庫、分散式檔案系統、各種NoSQL分散式存儲方案等。
10年前,Eric Brewer提出著名的CAP定理,指出:一個分散式系統不可能滿足一致性、可用性和分區容忍性這三個需求,最多只能同時滿足兩個。系統的關注點不同,採用的策略也不一樣。只有真正理解了系統的需求,才有可能利用好CAP定理。
架構師一般有兩個方向來利用CAP理論。
Key-Value存儲,如Amazon Dynamo等,可以根據CAP理論靈活選擇不同傾向的資料庫產品。
領域模型+分散式快取+存儲,可根據CAP理論結合自己的項目定製靈活的分散式方案,但難度較高。
對大型網站,可用性與分區容忍性優先權要高於數據一致性,一般會儘量朝著A、P的方向設計,然後通過其他手段保證對於一致性的商務需求。 架構設計師不要將精力浪費在如何設計能滿足三者的完美 分散式系統,而應該懂得取捨。
不同的數據對一致性的要求是不同的。SNS網站可以容忍相對較長時間的不一致,而不影響交易和用戶體驗;而像支付寶這樣的交易和賬務數據則是非常敏感的,通常不能容忍超過秒級的不一致。
Cache篇
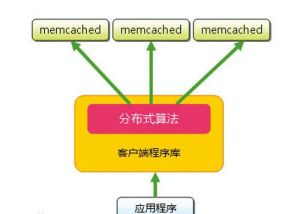 memcached構成
memcached構成快取在Web開發中運用越來越廣泛,mem-cached是danga(運營LiveJournal的技術團隊)開發的一套分布 式記憶體對象快取系統,用於在 動態系統中減少資料庫負載,提升性能。
memcached具有以下特點:
協定簡單;基於libevent的事件處理;內置記憶體存儲方式;memcached不互相通信的分散式。
memcached處理的原子是每一個(Key,Value)對(以下簡稱KV對),Key會通過一個hash算法轉化成hash-Key,便於查找、對比以及做到儘可能的散列。同時,memcached用的是一個二級散列,通過一張大hash表來維護。
memcached由兩個核心組件組成: 服務端(ms)和 客戶端(mc),在一個memcached的查詢中,mc先通過計算Key的hash值來確定KV對所處在的ms位置。當ms確定後,mc就會傳送一個查詢請求給對應的ms,讓它來查找確切的數據。因為這之間沒有互動以及多播協定,所以memcached互動帶給網路的影響是最小化的。
MemcacheDB是一個分散式、Key-Value形式的持久存儲系統。它不是一個快取組件,而是一個基於對象存取的、可靠的、快速的持久存儲引擎。協定與memcached一致(不完整),所以很多memcached 客戶端都可以跟它連線。MemcacheDB採用Berkeley DB作為持久存儲組件,因此很多Berkeley DB的特性它都支持。
類似這樣的產品也很多,如淘寶Tair就是Key-Value結構存儲,在淘寶得到了廣泛使用。後來Tair也做了一個持久化版本,思路基本與新浪MemcacheDB一致。
分散式資料庫篇
 Greenplum數據引擎軟體
Greenplum數據引擎軟體支付寶公司在國內最早使用 Greenplum資料庫,將數據倉庫從原來的Oracle RAC平台遷移到Greenplum集群。 Greenplum強大的計算能力用來支持支付寶日益發展的業務需求。 Greenplum數據引擎 軟體專為新一代 數據倉庫所需的大規模數據和複雜查詢功能所設計,基於MPP(海量 並行處理)和Shared-Nothing(完全無共享)架構,基於 開源軟體和x86商用硬體設計(性價比更高)。
分散式檔案系統篇
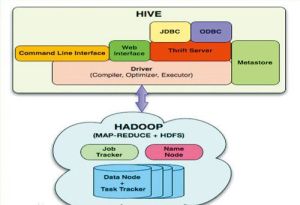 引自Facebook工程師的Hive與Hadoop關係圖
引自Facebook工程師的Hive與Hadoop關係圖談到 分散式檔案系統,不得不提的是Google的GFS。基於大量安裝有 Linux作業系統的普通PC構成的 集群系統,整個集群系統由一台Master(通常有幾台 備份)和若干台TrunkServer構成。GFS中檔案 備份成固定大小的Trunk分別存儲在不同的TrunkServer上,每個Trunk有多份(通常為3份)拷貝,也存儲在不同的TrunkServer上。Master負責維護GFS中的 Metadata,即檔案名稱及其Trunk信息。 客戶端先從Master上得到檔案的Metadata,根據要讀取的數據在檔案中的位置與相應的TrunkServer通信,獲取檔案數據。
在Google的論文發表後,就誕生了Hadoop。截至今日,Hadoop被很多中國最大網際網路公司所追捧,百度的搜尋日誌分析,騰訊、淘寶和支付寶的數據倉庫都可以看到Hadoop的身影 。
Hadoop具備低廉的硬體成本、開源的 軟體體系、較強的靈活性、允許用戶自己修改代碼等特點,同時能支持海量 數據存儲和計算任務。
Hive是一個基於Hadoop的數據倉庫平台,將轉化為相應的MapReduce程式基於Hadoop執行。通過Hive,開發人員可以方便地進行ETL開發。
如圖所示,引用一張Facebook工程師做的Hive和Hadoop的關係圖。
Yonghong Data Mart的Data Grid的分散式檔案存儲系統(DFS) 是在Hadoop HDFS基礎上進行的改造和擴展,將伺服器集群內所有節點上存儲的檔案統一管理和存儲。這些節點包括唯一的一個NamingNode,在 DFS 內部提供元數據服務;許多MapNode,提供存儲塊。存儲在 DFS 中的檔案被分成塊,然後將這些塊複製到多個計算機中(Map Node)。這與傳統的 RAID 架構大不相同。塊的大小和複製的塊數量在創建檔案時由客戶機決定。Naming Node監控存在伺服器集群內所有節點上的檔案操作,例如檔案創建、刪除、移動、重命名等等。
數據集市篇
數據集市(Data Mart) ,也叫數據市場,是一個從操作的數據和其他的為某個特殊的專業人員團體服務的數據源中收集數據的倉庫。從範圍上來說,數據是從企業範圍的資料庫、數據倉庫,或者是更加專業的數據倉庫中抽取出來的。數據中心的重點就在於它迎合了專業用戶群體的特殊需求,在分析、內容、表現,以及易用方面。數據中心的用戶希望數據是由他們熟悉的術語表現的。
國外知名的Garnter關於數據集市產品報告中,位於第一象限的敏捷商業智慧型產品有QlikView, Tableau和SpotView,都是全記憶體計算的數據集市產品,在大數據方面對傳統商業智慧型產品巨頭形成了挑戰。國內BI產品起步較晚,知名的敏捷型商業智慧型產品有PowerBI, 永洪科技的Z-Suite, SmartBI等,其中永洪科技的Z-Data Mart是一款熱記憶體計算的數據集市產品。國內的德昂信息也是一家數據集市產品的系統集成商。
Yonghong Data Mart是永洪科技基於自有技術研發的一款數據存儲、數據處理的軟體。
Yonghong Data Mart底層技術:
1. 分散式計算
2. 分散式通信
3. 記憶體計算
4. 列存儲
5. 庫內計算
NoSQL篇
隨著數據量增長,越來越多的人關注NoSQL,特別是2010年下半年,Facebook選擇 HBase來做實時訊息 存儲系統,替換原來開發的Cassandra系統。這使得很多人開始關注 HBase。Facebook選擇 HBase是基於短期小批量臨時數據和長期增長的很少被訪問到的數據這兩個需求來考慮的。
HBase是一個高可靠性、高性能、面向列、可伸縮的 分散式存儲系統,利用HBase技術可在廉價PC Server上搭建大規模結構化存儲集群。 HBase是BigTable的開源實現,使用HDFS作為其檔案 存儲系統。Google運行MapReduce來處理BigTable中的海量數據, HBase同樣利用MapReduce來處理HBase中的海量數據;BigTable利用Chubby作為協同服務,HBase則利用Zookeeper作為對應。
總結
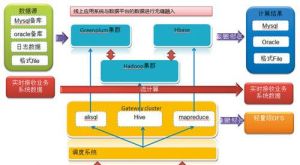 圖4 線上套用系統與數據平台的無縫融入
圖4 線上套用系統與數據平台的無縫融入近來NoSQL資料庫的使用越來越普及,幾乎所有的大型網際網路公司都在這個領域進行著實踐和探索。在享受了這類資料庫與生俱來的擴展性、 容錯性、高讀寫吞吐外(儘管各主流NoSQL仍在不斷完善中),越來越多的實際需 求把人們帶到了NoSQL並不擅長的其他領域, 比如搜尋、準實時統計分析、簡單事務等。實踐中一般會在NoSQL的外圍組合一些其他技術形成一個 整體解決方案。
