![雲模型[概念詞]](/img/2/7f6/nBnauM3XwQjN3ETMxgjN0ETN1UTM1QDN5MjM5ADMwAjMwUzL4YzL0EzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg "雲模型[概念詞]")
概述
隨著不確定性研究的深入,越來越多的科學家相信,不確定性是這個世界的魅力所在,只有不確定性本身才是確定的。在眾多的不確定性中,隨機性和模糊性是最基本的。針對機率論和模糊數學在處理不確定性方面的不足,1995年我國工程院院士李德毅教授在機率論和模糊數學的基礎上提出了雲的概念,並研究了模糊性和隨機性及兩者之間的關聯性 。自李德毅院士等人提出雲模型至今,雲模型已成功的套用到自然語言處理、數據挖掘、決策分析、智慧型控制、圖像處理等眾多領域 。
基本概念
定義
![雲模型[概念詞]](/img/d/248/wZwpmL4czMxQDOwITO5ADN0UTMyITNykTO0EDMwAjMwUzLykzLxEzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞]![雲模型[概念詞]](/img/c/30c/wZwpmL4UTOzgDOxETN0ETN1UTM1QDN5MjM5ADMwAjMwUzLxUzL4QzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg) 雲模型[概念詞] 雲模型[概念詞]
雲模型[概念詞] 雲模型[概念詞]![雲模型[概念詞]](/img/d/0c6/wZwpmL0UzM5gTO3UjMzATN1UTM1QDN5MjM5ADMwAjMwUzL1IzLyMzLt92YucmbvRWdo5Cd0FmLyE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞]![雲模型[概念詞]](/img/1/036/wZwpmL3QzM5YjNzMjM0EDN0UTMyITNykTO0EDMwAjMwUzLzIzL3EzLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞]![雲模型[概念詞]](/img/4/d3b/wZwpmL2AzM4IzM4YDN0ETN1UTM1QDN5MjM5ADMwAjMwUzL2QzLwYzLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞]
雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞]![雲模型[概念詞]](/img/8/778/wZwpmL2MzN5UzM2MzNwIDN0UTMyITNykTO0EDMwAjMwUzLzczL4MzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg) 雲模型[概念詞] 雲模型[概念詞]
雲模型[概念詞] 雲模型[概念詞]![雲模型[概念詞]](/img/8/26a/wZwpmL4cjNxAjNxcDN0ETN1UTM1QDN5MjM5ADMwAjMwUzL3QzLxUzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) 雲模型[概念詞] 雲模型[概念詞]
雲模型[概念詞] 雲模型[概念詞]![雲模型[概念詞]](/img/5/01f/wZwpmLxMjMwkDN5YzNwMzM1UTM1QDN5MjM5ADMwAjMwUzL2czL1EzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg) 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞]
雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞] 雲模型[概念詞]設是一個普通集合。, 稱為論域。關於論域中的模糊集合,是指對於任意元素都存在一個有穩定傾向的隨機數,叫做對的隸屬度。 如果論域中的元素是簡單有序的,則可以看作是基礎變數,隸屬度在上的分布叫做隸屬雲;如果論域中的元素不是簡單有序的,而根據某個法則,可將映射到另一個有序的論域上,中的一個且只有一個和對應,則為基礎變數,隸屬度在上的分布叫做隸屬雲 。
數字特徵
雲模型表示自然語言中的基元——語言值,用雲的數字特徵——期望Ex,熵En和超熵He表示語言值的數學性質 。
期望 Ex:雲滴在論域空間分布的期望,是最能夠代表定性概念的點,是這個概念量化的最典型樣本。
熵 En:“熵”這一概念最初是作為描述熱力學的一個狀態參量,此後又被引入統計物理學、資訊理論、複雜系統等,用以度量不確定的程度。在雲模型中,熵代表定性概念的可度量粒度,熵越大,通常概念越巨觀,也是定性概念不確定性的度量,由概念的隨機性和模糊性共同決定。一方面, En是定性概念隨機性的度量,反映了能夠代表這個定性概念的雲滴的離散程度;另一方面,又是定性概念亦此亦彼性的度量,反映了在論域空間可被概念接受的雲滴的取值範圍。用同一個數字特徵來反映隨機性和模糊性,也必然反映他們之間的關聯性。
超熵 He:熵的不確定性度量,即熵的熵,由熵的隨機性和模糊性共同決定。反映了每個數值隸屬這個語言值程度的凝聚性,即雲滴的凝聚程度。超熵越大,雲的離散程度越大,隸屬度的隨機性也隨之增大,雲的厚度也越大。
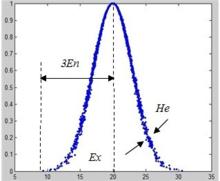 雲模型的三個數字特徵示意圖
雲模型的三個數字特徵示意圖雲發生器
雲的生成算法既可以用軟體的方式實現,又可以固化成硬體實現,稱為雲發生器(Cloud Generator)。雲發生器分為正向雲發生器和逆向雲發生器。
正向雲發生器
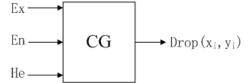 一維正向雲發生器
一維正向雲發生器正向雲發生器(Forward Cloud Generator)是從定性概念到其定量表示的映射,它根據云的數字特徵(Ex,En,He)產生雲滴,每個雲滴都是該概念的一次具體實現。
一維正向正態雲發生器的算法實現如下 :
輸入:表示定型概念A的三個數字特徵值Ex,En,He以及雲滴數N;
輸出:N個雲滴的定量值,以及每個雲滴代表概念A的確定度;
步驟:
(1)產生一個期望值為En,標準差為He的正態隨機數;
![雲模型[概念詞]](/img/4/913/wZwpmLyEjM0IzM4YzMwEDN0UTMyITNykTO0EDMwAjMwUzL2MzLygzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](2)產生一個期望值為Ex,標準差為abs(En’)的正態隨機數;
![雲模型[概念詞]](/img/5/831/wZwpmL0AjN3gzMzETN0ETN1UTM1QDN5MjM5ADMwAjMwUzLxUzL2YzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](3)計算:;
![雲模型[概念詞]](/img/9/9c2/wZwpmL0gjN2EDN1gTM2EzM1UTM1QDN5MjM5ADMwAjMwUzL4EzLyMzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞]![雲模型[概念詞]](/img/5/e10/wZwpmL3UTOxgTO5YTM5czN0UTMyITNykTO0EDMwAjMwUzL2EzL1EzLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](4)令為一個雲滴,它是該雲表示的語言值在數量上的一次具體實現,其中x為定性概念在論域中這一次對應的數值,為屬於這個語言值的程度的量度;
(5)重複步驟(1)到步驟(4),直到產生滿足要求數目的雲滴數。
逆向雲發生器
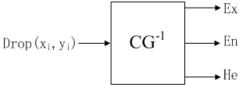 一維逆向雲發生器
一維逆向雲發生器逆向雲發生器(Backward Cloud Generator)是實現定量值到定性概念的轉換模型。它可以將一定數量的精確數據轉換為以數字特徵 ( Ex, En, He)表示的定性概念。
一維逆向正態雲發生器的算法實現如下:
雲模型[概念詞]輸入:N個雲滴的定量值及每個雲滴代表概念的確定度;
輸出:這N個雲滴表示的定性概念A的期望值Ex,熵En和超熵He ;
步驟:
雲模型[概念詞]![雲模型[概念詞]](/img/0/662/wZwpmLwMzM1kTOyIjN0ETN1UTM1QDN5MjM5ADMwAjMwUzLyYzLzczLt92YucmbvRWdo5Cd0FmL0E2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞]![雲模型[概念詞]](/img/d/7c8/wZwpmL4cjN0gjNwUDN0ETN1UTM1QDN5MjM5ADMwAjMwUzL1QzLxczLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞]![雲模型[概念詞]](/img/5/98d/wZwpmL2ITOzAzNycjN0ETN1UTM1QDN5MjM5ADMwAjMwUzL3YzLxEzLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](1)由計算這組數據的樣本均值,一階樣本絕對中心矩,樣本方差;
![雲模型[概念詞]](/img/2/b03/wZwpmLzADO5AzNzEjN0ETN1UTM1QDN5MjM5ADMwAjMwUzLxYzL2EzLt92YucmbvRWdo5Cd0FmLyE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](2)由(1)可得期望;
![雲模型[概念詞]](/img/f/9c9/wZwpmL2QDM4EjN2UTN0ETN1UTM1QDN5MjM5ADMwAjMwUzL1UzL2QzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](3)同時由樣本均值可得熵;
![雲模型[概念詞]](/img/9/eb7/wZwpmLxIDN1UTMxQTN0ETN1UTM1QDN5MjM5ADMwAjMwUzL0UzLxAzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) 雲模型[概念詞]
雲模型[概念詞](4)由(1)中的樣本方差和(3)中的熵可得。
