
計算風格學
語體風格是人們在語言表達活動中的個人言語特徵,是人格在語言活動中的某種體現。這種風格可在一定程度上通過數量特徵來刻畫。計算風格學就是通過量化的方法反映語體或作家風格的研究。能夠區別文學作品的特徵主要有用詞、句式、修辭手法、中心意象、主題等等。但是能用於統計的特徵有語音、字、詞、句子、段落,語篇結構等等可以量化考察的信息。因此它反映的不是作者想表現的內容,而是作者行文中不經意間體現出的用詞造句習慣。最常用的方法是字、詞頻率統計。除了使用詞語頻率的方法以外,許多文本信息都可供使用。例如句長和詞長可以代表人們造詞句的風格。句長是句子中的單詞數,詞長是詞中的音節數,反映作者風格的不是單個詞的詞長和單個句子的句長,而是以一定數量的語料為基礎的平均句長和平均詞長。平均詞長M=語料中音節總數L/單詞總數N平均句長=語料中音節總數L/句子總數N此外還有作者在同義詞使用中的傾向性。是值得利用但較困難的。計算風格學可用來解決“作者考證”的問題。當然,由於沒有嚴格的可行性,操作要十分謹慎。
正文
數理語言學的一個分支。採用計算機技術和統計方法,編制特定的數學程式和數量模型來研究文章風格的學科。主要研究內容有:①根據語言單位之間的數量關係,對不同的比率進行比較,歸入不同的類型,確定文章風格的差異;②把語言成分看作變數,研究語言變數之間的相關程度,推斷風格的變異情形;③把語言集團的語言變異與語言集團的地理位置結合起來研究,測定不同地理區域的人群之間的語言關係,確定相關性最高的區域;④通過語言單位出現頻率的統計,揭示語言成分在較大序列中的分布特徵,了解不同文章的風格,判斷文章的作者或寫作年代。目前,在電子計算機上一般可以採用相關矩陣的方法來確定作者的文體風格特徵。設某一作者m 的二階相關矩陣為m(i,j),則他的語言與標準語之間的偏離指數δ(m)可按如下公式計算:
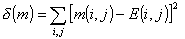
設有兩個作者m與n,作者m的二階相關矩陣為m(i,j),作者 n的二階相關矩陣為n(i,j),則這兩個作者的風格的接近程度可用相關指數S來表示:
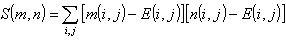
關於計算風格學的思考
關於計算風格學的基礎張首映指出,單個作家的“語言風格”是不可求證的,(文學自由談,1988(4))單個作家的“語言風格”,無論在時間之軸上,還是在空間之維中,都必定不可能產生。林語堂式的幽默,沈從文式的淡雅,都是不同的言語風格,而不是語言風格。因此計算起來可能很難。 這一論斷表明,我們不可能以量化的數值來表示絕對的作家風格。計算風格學的量化指標都只能作相對參考。
關於現有的研究方法
目前的研究中利用到的特徵主要分為以下幾類:常用字——優點是能夠反映作者的寫作傾向,但是必須要考慮是否應去掉文中專有名詞,使結果不受單部作品的影響。虛詞——能獨立於文本的內容。罕用字——只有當頻次較高的時候才比較有說服力,否則只能看作偶然出現。句型——優點是直接關係到作者與文體的風格;缺點是目前自動識別容易出錯,影響結論。
