介紹
在假設空間、損失函式以及訓練集確定的情況下,經驗風險函式就可以確定。假設給定一個數據集:
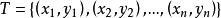 經驗風險最小化
經驗風險最小化模型f(x)關於訓練數據集的平均損失成為經驗風險或經驗損失:
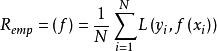 經驗風險最小化
經驗風險最小化經驗風險是模型關於訓練樣本集的平均損失。
策略
經驗風險最小化的策略認為,經驗風險最小的模型是最優的模型。根據這一策略,按照經驗風險最小化求最優模型就是求解最最佳化問題:
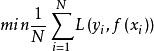 經驗風險最小化
經驗風險最小化當樣本容量足夠大時,經驗風險最小化能保證有很好的學習效果,在現實中被廣泛採用。例如,極大似然估計(MLE)就是經驗風險最小化的一個例子。當模型是條件機率分布,損失函式是對數損失函式時,經驗風險最小化就等於極大似然估計 。
但是,當樣本容量很小時,經驗風險最小化學習的效果就未必很好,會產生過擬合現象。而結構風險最小化是為了防止過擬合而提出的策略。結構風險最小化等價於正則化。結構風險在經驗風險的基礎上加上表示模型複雜度的正則化項。在假設空間、損失函式以及訓練集確定的情況下,結構風險的定義是:
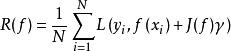 經驗風險最小化
經驗風險最小化其中,J(f)為模型的複雜度,是定義在假設空間上的泛函。模型f越複雜,複雜度J(f)就越大。也就是說,複雜度表示了對複雜模型的懲罰。結構風險小的模型往往對訓練數據和未知的測試數據都有較好的預測。比如,貝葉斯估計中的最大後驗機率估計(MAP)就是結構風險最小化的例子。當模型是條件機率分布,損失函式是對數損失函式,模型複雜度由模型的先驗機率表示時,結構風險最小化就等價於最大後驗機率估計。
結構風險最小化的策略認為結構風險最小的模型是最優的模型。所以求解模型,就是求解最最佳化問題:
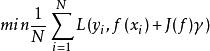 經驗風險最小化
經驗風險最小化