![深度學習[人工神經網路的研究的概念]](/img/2/cbb/nBnauM3XzczM1gDN1UTMwADO1UTM1QDN5MjM5ADMwAjMwUzL1EzL3QzLt92YucmbvRWdo5Cd0FmL0E2LvoDc0RHa.jpg "深度學習[人工神經網路的研究的概念]")
背景
機器學習(Machine Learning)是一門專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能的學科。機器能否像人類一樣能具有學習能力呢?1959年美國的塞繆爾(Samuel)設計了一個下棋程式,這個程式具有學習能力,它可以在不斷的對弈中改善自己的棋藝。4年後,這個程式戰勝了設計者本人。又過了3年,這個程式戰勝了美國一個保持8年之久的常勝不敗的冠軍。這個程式向人們展示了機器學習的能力,提出了許多令人深思的社會問題與哲學問題。
深度概念
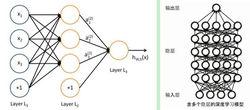 含多個隱層的深度學習模型
含多個隱層的深度學習模型從一個輸入中產生一個輸出所涉及的計算可以通過一個流向圖(flow graph)來表示:流向圖是一種能夠表示計算的圖,在這種圖中每一個節點表示一個基本的計算以及一個計算的值,計算的結果被套用到這個節點的子節點的值。考慮這樣一個計算集合,它可以被允許在每一個節點和可能的圖結構中,並定義了一個函式族。輸入節點沒有父節點,輸出節點沒有子節點。
這種流向圖的一個特別屬性是深度(depth):從一個輸入到一個輸出的最長路徑的長度。
傳統的前饋神經網路能夠被看做擁有等於層數的深度(比如對於輸出層為隱層數加1)。SVMs有深度2(一個對應於核輸出或者特徵空間,另一個對應於所產生輸出的線性混合)。
人工智慧研究的方向之一,是以所謂 “專家系統” 為代表的,用大量 “如果-就” (If - Then) 規則定義的,自上而下的思路。人工神經網路 ( Artificial Neural Network),標誌著另外一種自下而上的思路。神經網路沒有一個嚴格的正式定義。它的基本特點,是試圖模仿大腦的神經元之間傳遞,處理信息的模式。
問題
需要使用深度學習解決的問題有以下的特徵:
深度不足會出現問題。
人腦具有一個深度結構。
認知過程逐層進行,逐步抽象。
深度不足會出現問題
在許多情形中深度2就足夠表示任何一個帶有給定目標精度的函式。但是其代價是:圖中所需要的節點數(比如計算和參數數量)可能變的非常大。理論結果證實那些事實上所需要的節點數隨著輸入的大小指數增長的函式族是存在的。
我們可以將深度架構看做一種因子分解。大部分隨機選擇的函式不能被有效地表示,無論是用深的或者淺的架構。但是許多能夠有效地被深度架構表示的卻不能被用淺的架構高效表示。一個緊的和深度的表示的存在意味著在潛在的可被表示的函式中存在某種結構。如果不存在任何結構,那將不可能很好地泛化。
大腦有一個深度架構
例如,視覺皮質得到了很好的研究,並顯示出一系列的區域,在每一個這種區域中包含一個輸入的表示和從一個到另一個的信號流(這裡忽略了在一些層次並行路徑上的關聯,因此更複雜)。這個特徵層次的每一層表示在一個不同的抽象層上的輸入,並在層次的更上層有著更多的抽象特徵,他們根據低層特徵定義。
需要注意的是大腦中的表示是在中間緊密分布並且純局部:他們是稀疏的:1%的神經元是同時活動的。給定大量的神經元,仍然有一個非常高效地(指數級高效)表示。
認知過程逐層進行,逐步抽象
人類層次化地組織思想和概念;
人類首先學習簡單的概念,然後用他們去表示更抽象的;
工程師將任務分解成多個抽象層次去處理;
學習/發現這些概念(知識工程由於沒有反省而失敗?)是很美好的。對語言可表達的概念的反省也建議我們一個稀疏的表示:僅所有可能單詞/概念中的一個小的部分是可被套用到一個特別的輸入(一個視覺場景)。
基本思想
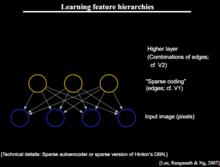 深度學習的核心思想
深度學習的核心思想假設我們有一個系統S,它有n層(S1,…Sn),它的輸入是I,輸出是O,形象地表示為: I =>S1=>S2=>…..=>Sn => O,如果輸出O等於輸入I,即輸入I經過這個系統變化之後沒有任何的信息損失,設處理a信息得到b,再對b處理得到c,那么可以證明:a和c的互信息不會超過a和b的互信息。這表明信息處理不會增加信息,大部分處理會丟失信息。保持了不變,這意味著輸入I經過每一層Si都沒有任何的信息損失,即在任何一層Si,它都是原有信息(即輸入I)的另外一種表示。現在回到主題Deep Learning,需要自動地學習特徵,假設我們有一堆輸入I(如一堆圖像或者文本),假設設計了一個系統S(有n層),通過調整系統中參數,使得它的輸出仍然是輸入I,那么就可以自動地獲取得到輸入I的一系列層次特徵,即S1,…, Sn。
對於深度學習來說,其思想就是對堆疊多個層,也就是說這一層的輸出作為下一層的輸入。通過這種方式,就可以實現對輸入信息進行分級表達了。
另外,前面是假設輸出嚴格地等於輸入,這個限制太嚴格,可以略微地放鬆這個限制,例如只要使得輸入與輸出的差別儘可能地小即可,這個放鬆會導致另外一類不同的Deep Learning方法。上述就是Deep Learning的基本思想。
把學習結構看作一個網路,則深度學習的核心思路如下:
①無監督學習用於每一層網路的pre-train;
②每次用無監督學習只訓練一層,將其訓練結果作為其高一層的輸入;
③用自頂而下的監督算法去調整所有層
主要技術
線性代數、機率和資訊理論
欠擬合、過擬合、正則化
最大似然估計和貝葉斯統計
隨機梯度下降
監督學習和無監督學習
深度前饋網路、代價函式和反向傳播
正則化、稀疏編碼和dropout
自適應學習算法
卷積神經網路
循環神經網路
遞歸神經網路
深度神經網路和深度堆疊網路
LSTM長短時記憶
主成分分析
正則自動編碼器
表征學習
蒙特卡洛
受限波茲曼機
深度置信網路
softmax回歸、決策樹和聚類算法
KNN和SVM
生成對抗網路和有向生成網路
機器視覺和圖像識別
自然語言處理
語音識別和機器翻譯
有限馬爾科夫
動態規劃
梯度策略算法
增強學習(Q-learning)
轉折點
2006年前,嘗試訓練深度架構都失敗了:訓練一個深度有監督前饋神經網路趨向於產生壞的結果(同時在訓練和測試誤差中),然後將其變淺為1(1或者2個隱層)。
2006年的3篇論文改變了這種狀況,由Hinton的革命性的在深度信念網(Deep Belief Networks, DBNs)上的工作所引領:
Hinton, G. E., Osindero, S. and Teh, Y.,A fast learning algorithm for deep belief nets.Neural Computation 18:1527-1554, 2006
Yoshua Bengio, Pascal Lamblin, Dan Popovici and Hugo Larochelle,Greedy LayerWise Training of Deep Networks, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems 19 (NIPS 2006), pp. 153-160, MIT Press, 2007
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra and Yann LeCun Efficient Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS 2006), MIT Press, 2007
在這三篇論文中以下主要原理被發現:
表示的無監督學習被用於(預)訓練每一層;
在一個時間裡的一個層次的無監督訓練,接著之前訓練的層次。在每一層學習到的表示作為下一層的輸入;
用有監督訓練來調整所有層(加上一個或者更多的用於產生預測的附加層);
DBNs在每一層中利用用於表示的無監督學習RBMs。Bengio et al paper 探討和對比了RBMs和auto-encoders(通過一個表示的瓶頸內在層預測輸入的神經網路)。Ranzato et al paper在一個convolutional架構的上下文中使用稀疏auto-encoders(類似於稀疏編碼)。Auto-encoders和convolutional架構將在以後的課程中講解。
從2006年以來,大量的關於深度學習的論文被發表。
成功套用
1、計算機視覺
ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, NIPS 2012.
Learning Hierarchical Features for Scene Labeling, Clement Farabet, Camille Couprie, Laurent Najman and Yann LeCun, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013.
Learning Convolutional Feature Hierarchies for Visual Recognition, Koray Kavukcuoglu, Pierre Sermanet, Y-Lan Boureau, Karol Gregor, Michaël Mathieu and Yann LeCun, Advances in Neural Information Processing Systems (NIPS 2010), 23, 2010.
香港中文大學的多媒體實驗室是最早套用深度學習進行計算機視覺研究的華人團隊。在世界級人工智慧競賽LFW(大規模人臉識別競賽)上,該實驗室曾力壓FaceBook奪得冠軍,使得人工智慧在該領域的識別能力首次超越真人。
2、語音識別
微軟研究人員通過與hinton合作,首先將RBM和DBN引入到語音識別聲學模型訓練中,並且在大辭彙量語音識別系統中獲得巨大成功,使得語音識別的錯誤率相對減低30%。但是,DNN還沒有有效的並行快速算法,很多研究機構都是在利用大規模數據語料通過GPU平台提高DNN聲學模型的訓練效率。
在國際上,IBM、google等公司都快速進行了DNN語音識別的研究,並且速度飛快。
國內方面,阿里巴巴,科大訊飛、百度、中科院自動化所等公司或研究單位,也在進行深度學習在語音識別上的研究。
3、自然語言處理等其他領域
很多機構在開展研究,2013年Tomas Mikolov,Kai Chen,Greg Corrado,Jeffrey Dean發表論文Efficient Estimation of Word Representations in Vector Space建立word2vector模型,與傳統的詞袋模型(bag of words)相比,word2vector能夠更好地表達語法信息。 深度學習在自然語言處理等領域主要套用於機器翻譯以及語義挖掘等方面。
