介紹
機器學習, 尤其是基於人工神經網路的深度學習近年來得到了迅猛發展. 而在量子信息科學領域,它與量子計算技術的結合也正在成為一個飛速發展的研究方向. 事實上, 機器學習的思想很早就套用於量子力學系統的最佳化控制中, 並在量子化學和物理實驗的廣泛套用中獲得巨大成功. 近年來, 隨著深度學習的流行, 各種機器學習算法被用來探索量子多體物理中許多難於解析分析的問題, 並得到了許多有趣的結果.
 圖1
圖1機器學習與量子物理結合的另一個自然思路是利用量子狀態的疊加和量子算法的加速, 來解決當前數據科學中數據量巨大, 訓練過程緩慢的困難. 這方面的研究在量子計算的發展初期實際已經有人開始研究, 但是限於實驗條件和當時學術界對量子計算發展前景的困惑, 並沒有得到長足的發展. 近年來, 隨著量子計算機在計算規模和穩定性的突破, 基於量子算法的機器學習重新得到關注, 並成為一個迅速發展的研究方向.事實上, 從經典–量子的二元概念出發可以將機器學習問題按照數據和算法類型的不同分為4類(如圖1), 將對C–Q(利用經典算法解決量子物理問題)進行簡單介紹, 然後重點對Q–C(利用量子算法加速機器學習)進行綜合討論, 因為本文認為後者更體現量子機器學習的本質所在, 對未來機器學習的發展推動作用更為巨大. Q–Q是一個開放的領域, 也在此不做評論.
量子系統控制中的一個基本問題是對控制對象的建模, 即對系統的哈密頓量以及確定擾動, 噪聲等參數特徵進行辨識, 這些問題都屬於C–Q的範疇. 例如,研究人員提出使用貝葉斯推斷中的似然函式對量子系統的哈密頓量進行學習, 並進行了實驗驗證, 結果表明學習算法具有一定的魯棒性, 即使假設模型結構中有缺項, 學習結果仍是實際模型的最佳近似.
基於一定量的量子測量數據出發判斷和確定其未知量子態的性質, 例如如何判別一個量子態是分離還是糾纏的, 也可以看作一類機器學習問題. 研究人員提出用監督式學習的方法對量子態做分類, 容易理解,直接使用量子模型, 量子數據的全量子方式, 其分類正確率比使用經典模型和經過量子隨機存儲器(quantum random access memory, QRAM)調用轉換的量子數據的半經典方式更高. 其後, 他們提出不需要使用QRAM的量子態分類方法, 且算法所需的經典存儲器規模僅隨訓練比特數以對數速度增長.此外, 他們還專門研究了光子相干態的分類問題, 發現對訓練樣本和反射信號進行聯合全局測量, 比先對訓練集進行基於高斯測量的幅值估計, 再對反射信號進行狀態判別的識別率要高. 對於量子系統演化所對應的酉變換, 如何從有限樣本集中進行辨識學習, 也是一個重要的問題. 該問題可以歸結為一個雙重最佳化問題, 同時需要最優輸入態和最優測量. 近年來, 也有學者開始著手於研究用機器學習方法獲取量子系統的屬性和統計參數, 如相變點, 期望值等. 該思想也可用於量子多體系統的模擬問題. 在此不做重點描述.
利用量子理論改進機器學習(Q–C)的方法大致可以分為兩種: 1) 通過量子算法使某些在經典計算機上不可計算的問題變為可計算的, 從而大幅降低機器學習算法的計算複雜度, 如量子退火(quantum annealing, QA)算法、Gibbs採樣等; 2) 量子理論的並行性等加速特點直接與某些機器學習算法深度結合, 催生出一批全新的量子機器學習模型, 如張量網路、機率圖模(probabilistic graphical model, PGM)等.
數數據的量子化表達和讀寫
 圖2
圖2量子機器學習的訓練數據必須以某種可以為量子計算機識別的格式載入, 經過量子機器學習算法處理以後形成輸出, 而此時的輸出結果是量子格式的, 需要經過測量讀出得到筆者所需的最終結果(如圖2所示). 因此, 量子機器學習的複雜度與這3個過程都有關係. 大致說來, 基於量子相位估計的學習算法可以實現算法的指數加速, 但是對數據的載入和完整結果的讀出要求很高, 而基於量子搜尋的算法相對較複雜,但是數據的讀入讀出則相對比較容易. 常用的兩種方式以及為之需要匹配的讀入讀出方式.
數字型
眾所周知, 數字計算機中所有數據都是有限字長的. 假設某訓練數據向量為⃗x = [x1· · · xn], 若每個元素都用長度為m的二進制數據表示, 則整個向量需要 n · m 個比特, 在量子計算機中它們對應於 N =n · m個量子位. 每個數據向量都對應於輸入態希爾伯特空間的一個基矢|⃗x⟩.
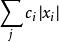 量子機器學習
量子機器學習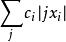 量子機器學習
量子機器學習 量子機器學習
量子機器學習這其實是一個量子化的過程. 類似的, 輸出數據⃗y= [y1· · · yq]也可以用適當長度的二進制數表示相應, 並通過量子化對應於輸出態希爾伯特空間的一個基矢. 對比下面將要提到的模擬型數據, 這種表示通過馮諾伊曼投影測量即可進行讀出, 其代價是最低的.進一步, 如果訓練數據集中有M個數據, 自然的方式是用N · M個量子位存儲這些數據, 但這樣耗費的資源無疑十分巨大, 特別在海量數據集的情形下. 為此可以充分利用量子系統的疊加特性, 將這些數據以“疊加”的方式存儲在N個比特上, 用狀態 表示. 這樣可以存儲最2N個數據向量, 並且數據處理可以並行進行, 其中單個或多個數據的提取根據數據特徵(模式)採用Grover算法搜尋得到, 因此稱作量子關聯存儲器(quantum associative memory, QAM). 另一種方式是用log(M)個比特標記數據下標(地址), 從而數據可以並行存儲在log(M) + n · m個比特中, 其中第j個數據表示為 可以通過設計存儲器根據定址請求調用相應的數據, 以疊加方式 並行載入數據, 這是與經典數據載入非常不同的地方.這裡的機率幅係數 對應於經典數據處理中的隨機採樣機率分布, 但是以相干疊加的方式進行, 使得後續的數據處理可以並行進行, 設計巧妙的算法利用相干性帶來的相長相消得到期望的結果, 以實現量子加速(quantum speed-up) .
模擬型
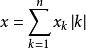 量子機器學習
量子機器學習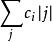 量子機器學習
量子機器學習訓練數據還可以用半模擬的方式編碼在量子態上.假設⃗x = [x1· · · xn]已經歸一化,則可以用log(n)個比特, 其中數據分量對應於用疊加態 中各基矢的機率幅係數. 與數字型數據相比, 這種編碼方式可以極大節省所需的量子位資源, 並避免數位化帶來的圓整誤差. 但它的最大問題是製備和讀出的困難, 精確製備這樣的量子態在實驗上是非常困難的事, 而讀出所需的精確層析技術也需要通過大量的重複實驗才能準確重構這樣的量子態. 由於所需重複樣本隨測控精度提高而上升, 因此也需要很大的時間複雜度代價.與數字型數據類似, 如果訓練數據集中有M個數據, 可以用log(M)個比特表示下標, 從而用log(n·M)個比特表示整個數據集, 而且數據可以以 .
量子數據集的轉換
從經典數據到量子數據的轉換, 需要通過存儲器來實現. 對於數字型數據, 其實對應於一個量子化的數字邏輯電路, 或者一個量子子程式, 通過執行該子程式將暫存器的狀態製備到訓練數據對應的狀態. 這個子程式是模組化的, 由於在機器學習中會經常隨機抽取或者檢索該數據集中的數據, 因此它常常作為一個oracle供Grover算法調用, 而調用的次數則成為衡量機器學習算法複雜度的重要指標之一. 這類存儲器具有專用名稱-量子關聯存儲器(quantum associativememory, QAM).
顯而易見, 模擬型量子數據是最節省資源的存儲方式, 但是從物理實現的角度上, 需要對量子暫存器進行精確地狀態製備和存儲, 利用所謂的QRAM調用.
在訓練過程中, 還應該能夠高效地根據訪問地址調用所需數據, 這些對量子系統的控制, 以及量子計算機體系結構和算法設計提出了重要挑戰. 此外, 數據的讀出是另外一個困難問題, 因為在這種情況下,通常需要對暫存器狀態的最終值進行測量讀出, 而這需要大量耗時的狀態層析, 如果不精心設計的話, 所需代價甚至可能超過存儲節省的資源.
