
參數範數懲罰
 正則化方法
正則化方法 正則化方法
正則化方法通過向目標函式添加一個參數範數懲罰 項來降低模型的容量,是一類常用的正則化方法。將正則化後的損失函式記作 :
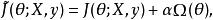 正則化方法
正則化方法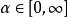 正則化方法
正則化方法其中 權衡範數懲罰項的相對貢獻,越大的αα對應越多的正則化。
通常情況下,深度學習中只對網路權重θθ添加約束,對偏置項不加約束。主要原因是偏置項一般需要較少的數據就能精確的擬合,不對其正則化也不會引起太大的方差。另外,正則化偏置參數反而可能會引起顯著的欠擬合。
L2參數正則化
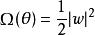 正則化方法
正則化方法常用的L2參數正則化通過向目標函式添加一個正則項
,使權重更加接近原點。L2參數正則化方法也叫做權重衰減,有時候也叫做嶺回歸(ridge regression)。L2參數正則化之後的模型具有以下總的目標函式:
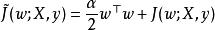 正則化方法
正則化方法與之對應的梯度為:
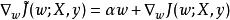 正則化方法
正則化方法使用單步梯度下降更新權重,即執行以下更新:
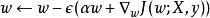 正則化方法
正則化方法換種寫法就是:
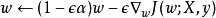 正則化方法
正則化方法 正則化方法
正則化方法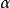 正則化方法
正則化方法我們可以看到,加入權重衰減後會引起學習規則的修改,即在每步執行通常的梯度更新之前先收縮權重向量(將權重向量乘以一個常數因子)。由於 和 都是大於0的數,因此相對於不加正則化的模型而言,正則化之後的模型權重在每步更新之後的值都要更小。
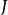 正則化方法
正則化方法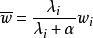 正則化方法
正則化方法假設 是一個二次最佳化問題(比如採用平方損失函式)時,模型參數可以進一步表示為 ,即相當於在原來的參數上添加了一個控制因子,其中λλ是參數Hessian矩陣的特徵值。由此可見
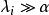 正則化方法
正則化方法當 時,懲罰因子作用比較小。
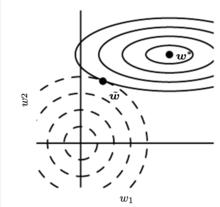 圖一
圖一 正則化方法
正則化方法當 時,對應的參數會縮減至0。
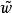 正則化方法
正則化方法 正則化方法
正則化方法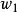 正則化方法 正則化方法
正則化方法 正則化方法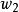 正則化方法
正則化方法如圖一所示,實線表示未經過正則化的目標函式的等高線,虛線圓圈表示L2正則項的等高線。在點 處這兩個互相競爭的目標達到均衡。在橫軸這個方向,從點 處開始水平移動,目標函式並沒有增加太多,也就是在這個方向上目標函式並沒有很強的偏好,因而正則化在這個方向上有較強的效果,表現為把 往原點拉動了較長的距離。另一方面,在縱軸這個方向上,目標函式對應遠離 的移動很敏感,即目標函式在這個方向的曲率很高,因此正則化對於 的影響就較小。
在原目標函式的基礎上增加L2範數懲罰,將原函式進行了一定程度的平滑化,這個可以從其梯度函式有所體現。
對於一類存在大量駐點(Stationary point,即梯度為0的點),增加L2範數意味著將原本導數為零的區域,加入了先驗知識進行區分(幾何上,意味著原本一個平台的區域向0點方向傾斜),這樣可以幫助最佳化算法至少收斂到一個局部最優解,而不是停留在一個鞍點上。
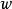 正則化方法
正則化方法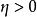 正則化方法
正則化方法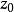 正則化方法
正則化方法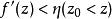 正則化方法
正則化方法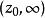 正則化方法
正則化方法通過限制參數 在0點附近,加快收斂,降低最佳化難度。回憶一下,對於一類常見激活函式,如Sigmoid,滿足:單調有界。根據單調有界定理,對於任意小的 ,我們可以取得足夠大的 ,使得 。換句話說,對於該變數,我們可以找到一個足夠大的區域 使得其導數接近於0,這意味著通過梯度方法改進該變數會變得極其緩慢(回憶後向傳播算法的更新),甚至受浮點精度等影響其收斂。那么,採用範數控制變數的大小在0附近,可以避免上述情況,從而在很大程度上可以讓最佳化算法加快收斂。
L1參數正則化
L2權重衰減是權重衰減最常見的形式,我們還可以使用其他的方法限制模型參數的規模。 比如我們還可以使用L1參數正則化。
L2權重衰減是權重衰減最常見的形式,我們還可以使用其他的方法限制模型參數的規模。 比如我們還可以使用L1參數正則化。
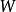 正則化方法
正則化方法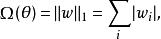 正則化方法
正則化方法形式地,對模型參數 的L1正則化被定義為: ,即各個參數的絕對值之和。
接著我們將討論L1正則化對簡單線性回歸模型的影響,與分析L2正則化時一樣不考慮偏置參數。
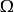 正則化方法 正則化方法
正則化方法 正則化方法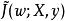 正則化方法
正則化方法我們尤其感興趣的是找出L1和L2正則化之間的差異。與L2權重衰減類似,我們也可以通過縮放懲罰項 的正超參數 來控制L1權重衰減的強度。 因此,正則化的目標函式 如下所示
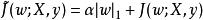 正則化方法
正則化方法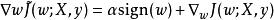 正則化方法
正則化方法對應的梯度(實際上是次梯度):
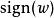 正則化方法 正則化方法
正則化方法 正則化方法其中 只是簡單地取 各個元素的正負號。
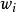 正則化方法
正則化方法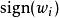 正則化方法
正則化方法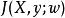 正則化方法
正則化方法觀察上述等式,我們立刻發現L1的正則化效果與L2大不一樣。 具體來說,我們可以看到正則化對梯度的影響不再是線性地縮放每個 ;而是添加了一項與 同號的常數。使用這種形式的梯度之後,我們不一定能得到 二次近似的直接算術解(L2正則化時可以)。
正則化方法由於 是一個大於0的數,因此L1參數正則化相對於不加正則化的模型而言,每步更新後的權重向量都向0靠攏。
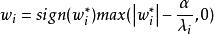 正則化方法
正則化方法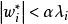 正則化方法
正則化方法特殊情況下,對於二次最佳化問題,並且假設對應的Hessian矩陣是對角矩陣,可以推導出參數遞推公式為 ,從中可以看出 當 i時,對應的參數會縮減到0,這也是和L2正則不同地方。對比L2最佳化方法,L2不會直接將參數縮減為0,而是一個非常接近於0的值。
L1正則化和L2正則化的區別
通過上面的分析,L1相對於L2能夠產生更加稀疏的模型,即當L1正則在參數w比較小的情況下,能夠直接縮減至0.因此可以起到特徵選擇的作用,該技術也稱之為 LASSO。
如果從機率角度進行分析,很多範數約束相當於對參數添加先驗分布,其中L2範數相當於參數服從高斯先驗分布;L1範數相當於拉普拉斯分布。
1.通過上面的分析,L1相對於L2能夠產生更加稀疏的模型,即當L1正則在參數w比較小的情況下,能夠直接縮減至0.因此可以起到特徵選擇的作用,該技術也稱之為 LASSO。
2.如果從機率角度進行分析,很多範數約束相當於對參數添加先驗分布,其中L2範數相當於參數服從高斯先驗分布;L1範數相當於拉普拉斯分布。
 L1和L2正則化區別
L1和L2正則化區別數據集增強
使用更多的樣本數據訓練模型可以獲得更好的泛化性能,然而,實踐中我們很難獲得更多的訓練數據。一種解決方法是人為創造一些合理的假數據並把它們添加到訓練集。
 正則化方法
正則化方法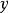 正則化方法 正則化方法 正則化方法
正則化方法 正則化方法 正則化方法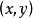 正則化方法
正則化方法這樣的方法對於分類任務來說是最簡單的。一個分類器需要有能力把一個複雜高維的輸入 映射到單一類目的輸出 ,因此分類器需要對大量 的變換保持預測結果的不變,即對於相似的輸入需要有相同的輸出。因此,我們可以輕易地轉換訓練集中的 來生成新的 對。例如,對於圖像識別任務來說,像素的部分平移、縮放、旋轉操作並不會改變圖片中物體對語義表達,因而我們可以使用這些操作來生存新對訓練數據。數據集增強對於語音識別任務也是有效的。
另一種數據集增強的方法是向網路的輸入層注入噪聲。神經網路已被證明對噪聲不是非常健壯。簡單地將隨機噪聲施加到輸入再進行訓練可以改善神經網路的健壯性。對於某些模型,在模型的輸入上添加方差極小的噪聲等價於對權重施加範數懲罰(Bishop)。
研究表明,將噪聲施加到網路的隱藏層也是有效的,這可以被看成是在多個抽象層上進行數據集增強。著名的Dropout方法可以看作是對隱藏層輸出乘以一個噪聲後輸出到下一層。
噪音的魯棒性
一般情況下,噪聲注入遠比簡單的收縮參數強大,特別是噪聲被添加到隱藏單元時。
另一種正則化模型的噪聲使用方法是將其直接添加到學習到的權重上。這項技術主要被用於循環神經網路的情況下。這種方法可以看作是權重的貝葉斯推斷的一種隨機實現。貝葉斯方法認為學習到的模型權重上不確定的,並且這種不確定性可以通過權重的機率分布來表示。添加噪音到學習到的權重上可以看著是反映這種不確定行的一種隨機的、實用的方式。
在適當的假設下,施加噪聲到權重可以被解釋與傳統的正則化形式等價,鼓勵學習到的函式保存一定的穩定性。這種形式的正則化鼓勵模型的參數進入到參數空間中相對較穩定的區域,在這些區域小的權重擾動對於模型的輸出影響較小。
向輸出目標註入噪聲
正則化方法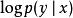 正則化方法 正則化方法 正則化方法
正則化方法 正則化方法 正則化方法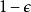 正則化方法 正則化方法
正則化方法 正則化方法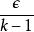 正則化方法 正則化方法
正則化方法 正則化方法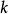 正則化方法
正則化方法大多數數據集的標籤yy都有一定錯誤,錯誤的 不利於最大化 。 避免這種情況的一種方法是顯式地對標籤上的噪聲進行建模。 例如,我們可以假設,對於一些小常數 ,訓練集標記 是正確的機率是 ,(以 的機率)任何其他可能的標籤也是正確的。這個假設很容易就能解析地與代價函式結合,而不用顯式地抽取噪聲樣本。 例如,標籤平滑(label smoothing) 通過把確切分類目標從0和1替換成 和 ,正則化具有 個輸出的softmax函式模型。標準交叉熵損失可以用在這些非確切目標的輸出上。 使用softmax函式和明確目標的最大似然學習可能永遠不會收斂, 因為softmax函式永遠無法真正預測0機率或1機率,因此它會繼續學習越來越大的權重,使預測更極端。使用如權重衰減等其他正則化策略能夠防止這種情況。標籤平滑的優勢是能夠防止模型追求確切機率而不影響模型學習正確分類。這種策略自20世紀80年代就已經被使用,並在現代神經網路繼續保持顯著特色。
半監督學習
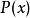 正則化方法
正則化方法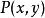 正則化方法
正則化方法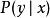 正則化方法 正則化方法 正則化方法
正則化方法 正則化方法 正則化方法在半監督學習的框架下, 產生的未標記樣本和 中的標記樣本都用於估計 或者根據 預測 。
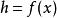 正則化方法
正則化方法在深度學習的背景下,半監督學習通常指的是學習一個表示 。 學習表示的目的是使相同類中的樣本有類似的表示。無監督學習可以為如何在表示空間聚集樣本提供有用線索。在輸入空間緊密聚集的樣本應該被映射到類似的表示。在許多情況下,新空間上的線性分類器可以達到較好的泛化。這種方法的一個經典變種是使用主成分分析作為分類前(在投影后的數據上分類)的預處理步驟。
正則化方法 正則化方法 正則化方法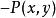 正則化方法
正則化方法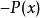 正則化方法 正則化方法 正則化方法
正則化方法 正則化方法 正則化方法我們可以構建這樣一個模型,其中生成模型 或 與判別模型 共享參數,而不用分離無監督和監督部分。 我們權衡監督模型準則 和無監督或生成模型準則(如 或 )。生成模型準則表達了對監督學習問題解的特殊形式的先驗知識,即P(x)P(x)的結構通過某種共享參數的方式連線到 。通過控制在總準則中的生成準則,我們可以獲得比純生成或純判別訓練準則更好的權衡。
多任務學習
多任務學習是通過合併幾個任務中的樣例(可以視為對參數施加的軟約束)來提高泛化的一種方式。額外的訓練樣本以同樣的方式將模型的參數推向泛化更好的方向,當模型的一部分在任務之間共享時,模型的這一部分更多地被約束為良好的值(假設共享是合理的),往往能更好地泛化。
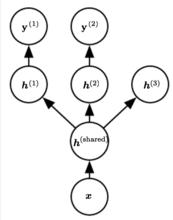 多任務學習
多任務學習 正則化方法
正則化方法 正則化方法
正則化方法 正則化方法
正則化方法右圖是深度學習中多任務學習的一個例子,網路中的輸入層和第一個隱藏層是在多個任務之間共享的,上層的 和 (對應一個無監督學習任務)是不同任務特有的參數。這裡假設 是對原始輸入的某種公共的抽象表示,可以在多個任務間共享。
因為共享參數,其統計強度可大大提高(共享參數的樣本數量相對於單任務模式增加的比例),並能改善泛化和泛化誤差的範圍。當然,僅當不同的任務之間存在某些統計關係的假設是合理(意味著某些參數能通過不同任務共享)時才會發生這種情況。
從深度學習的觀點看,底層的先驗知識如下:能解釋數據變化(在與之相關聯的不同任務中觀察到)的因素中,某些因素是跨兩個或更多任務共享的。例如,在出來圖像識別相關的任務時卷積層和pooling層可以在多個任務間共享。
提前終止
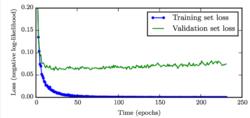 提前停止
提前停止在模型訓練過程中經常出現隨著不斷疊代,訓練誤差不斷減少,但是驗證誤差先減少然後開始增長,如下圖所示。
提前停止(Early Stopping)的策略是:在驗證誤差不在提升後,提前結束訓練;而不是一直等待驗證誤差到最小值。該策略可以用於任意的模型,不限於深度學習。GBDT算法天然適合採用Early Stopping策略來確定需要訓練多少顆子樹,因為GBDT是一個加法模型,採用提前終止策略都不需要額外存儲模型的副本。
參數綁定和共享
有時我們需要一種方式來表達我們對模型參數適當值的先驗知識。我們可能無法準確地知道應該使用什麼樣的參數,但我們根據領域和模型結構方面的知識得知模型參數之間應該存在一些相關性。
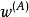 正則化方法
正則化方法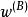 正則化方法
正則化方法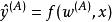 正則化方法
正則化方法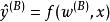 正則化方法
正則化方法我們經常想要表達的一種常見依賴是某些參數應當彼此接近。考慮以下情形:我們有兩個模型執行相同的分類任務(具有相同類別),但輸入分布稍有不同。 形式地,我們有參數為 的模型A和參數為 的模型B。 這兩種模型將輸入映射到兩個不同但相關的輸出: 和 。
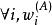 正則化方法
正則化方法 正則化方法
正則化方法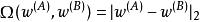 正則化方法
正則化方法我們可以想像,這些任務會足夠相似(或許具有相似的輸入和輸出分布),因此我們認為模型參數應彼此靠近: 應該與 接近。 我們可以通過正則化利用此信息。 具體來說,我們可以使用以下形式的參數範數懲罰: 。 在這裡我們使用L2懲罰,但也可以使用其他選擇。
正則化一個模型(監督模式下訓練的分類器)的參數,使其接近另一個無監督模式下訓練的模型(捕捉觀察到的輸入數據的分布)的參數。 這種構造架構使得許多分類模型中的參數能與之對應的無監督模型的參數匹配。
參數範數懲罰是正則化參數使其彼此接近的一種方式,而更流行的方法是使用約束:強迫某些參數相等。 由於我們將各種模型或模型組件解釋為共享獨立的一組參數,這種正則化方法通常被稱為參數共享。和正則化參數使其接近(通過範數懲罰)相比,參數共享的一個顯著優點是,只有參數(獨立一個集合)的子集需要被存儲在記憶體中。 對於某些特定模型,如卷積神經網路,這可能可以顯著減少模型所占用的記憶體。
 正則化方法
正則化方法 正則化方法
正則化方法最流行和廣泛使用的參數共享出現套用於計算機視覺的卷積神經網路中。 自然圖像有許多統計屬性是對轉換不變的。 例如,貓的照片即使向右邊移了一個像素,仍保持貓的照片。 CNN通過在圖像多個位置共享參數來考慮這個特性。 相同的特徵(具有相同權重的隱藏單元)在輸入的不同位置上計算獲得。 這意味著無論貓出當前圖像中的第 列或 列,我們都可以使用相同的貓探測器找到貓。
參數共享顯著降低了CNN模型的參數數量,並顯著提高了網路的大小而不需要相應地增加訓練數據。它仍然是將領域知識有效地整合到網路架構的最佳範例之一。
稀疏表示
深度學習可以看著時一種表示學習(representation learning),比如卷積神經網路可以學習圖像的不同層次的特徵表示,word2vec學習詞的Distributed representation,其共同特點是用隱層權重作為表示。
正則化方法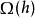 正則化方法 正則化方法
正則化方法 正則化方法L1懲罰可以誘導稀疏的參數,即許多參數為零(或接近於零)。
表示的範數懲罰正則化是通過向損失函式
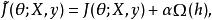 正則化方法 正則化方法 正則化方法
正則化方法 正則化方法 正則化方法其中 權衡範數懲罰項的相對貢獻,越大的 對應越多的正則化。
通過上述方法,含有隱藏單元的模型在本質上都能變得稀疏。
集成化方法
集成化方法是一種通用的降低泛化誤差的方法,通過合併多個模型的結果,也叫作模型平均。主要想法是分別訓練幾個不同的模型,然後讓所有模型表決測試樣例的輸出。
經驗:原始輸入每一個節點選擇機率0.8,隱藏層選擇機率為0.5。
Bagging是一種常用的集成學習方法。Bagging的策略很多,例如不同初始化方法、不同mini batch選擇方法、不同的超參數選擇方法。
與之對應的集成方法是Boosting,通過改變樣本權重來訓練不同模型。
