
簡介
TF-IDF是一種統計方法,用以評估一字詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度。字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。TF-IDF加權的各種形式常被搜尋引擎套用,作為檔案與用戶查詢之間相關程度的度量或評級。除了TF-IDF以外,網際網路上的搜尋引擎還會使用基於連結分析的評級方法,以確定檔案在搜尋結果中出現的順序。
原理
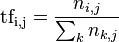 tf-idf
tf-idfTFIDF的主要思想是:如果某個詞或短語在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。TFIDF實際上是:TF * IDF,TF詞頻(Term Frequency),IDF逆向檔案頻率(Inverse Document Frequency)。TF表示詞條在文檔d中出現的頻率。IDF的主要思想是:如果包含詞條t的文檔越少,也就是n越小,IDF越大,則說明詞條t具有很好的類別區分能力。如果某一類文檔C中包含詞條t的文檔數為m,而其它類包含t的文檔總數為k,顯然所有包含t的文檔數n=m+k,當m大的時候,n也大,按照IDF公式得到的IDF的值會小,就說明該詞條t類別區分能力不強。但是實際上,如果一個詞條在一個類的文檔中頻繁出現,則說明該詞條能夠很好代表這個類的文本的特徵,這樣的詞條應該給它們賦予較高的權重,並選來作為該類文本的特徵詞以區別與其它類文檔。這就是IDF的不足之處. 在一份給定的檔案里, 詞頻(term frequency,TF)指的是某一個給定的詞語在該檔案中出現的頻率。這個數字是對 詞數(term count)的歸一化,以防止它偏向長的檔案。(同一個詞語在長檔案里可能會比短檔案有更高的詞數,而不管該詞語重要與否。)對於在某一特定檔案里的詞語來說,它的重要性可表示為:
以上式子中分子是該詞在檔案中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
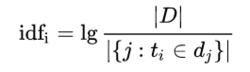 tf-idf
tf-idf逆向檔案頻率(inverse document frequency,IDF)是一個詞語普遍重要性的度量。某一特定詞語的IDF,可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取以10為底的對數得到:
其中
•|D|:語料庫中的檔案總數
•:包含詞語的檔案數目(即的檔案數目)如果該詞語不在語料庫中,就會導致分母為零,因此一般情況下使用
•作為分母。
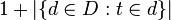 idf公式分母
idf公式分母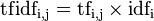 tf-idf
tf-idf然後再計算TF與IDF的乘積。
某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。
舉例
例1
有很多不同的數學公式可以用來計算TF-IDF。這邊的例子以上述的數學公式來計算。詞頻 (TF) 是一詞語出現的次數除以該檔案的總詞語數。假如一篇檔案的總詞語數是100個,而詞語“母牛”出現了3次,那么“母牛”一詞在該檔案中的詞頻就是3/100=0.03。一個計算檔案頻率 (IDF) 的方法是檔案集裡包含的檔案總數除以測定有多少份檔案出現過“母牛”一詞。所以,如果“母牛”一詞在1,000份檔案出現過,而檔案總數是10,000,000份的話,其逆向檔案頻率就是 lg(10,000,000 / 1,000)=4。最後的TF-IDF的分數為0.03 * 4=0.12。
例2
在某個一共有一千詞的網頁中“原子能”、“的”和“套用”分別出現了 2 次、35 次 和 5 次,那么它們的詞頻就分別是 0.002、0.035 和 0.005。 我們將這三個數相加,其和 0.042 就是相應網頁和查詢“原子能的套用” 相關性的一個簡單的度量。概括地講,如果一個查詢包含關鍵字 w1,w2,...,wN, 它們在一篇特定網頁中的詞頻分別是: TF1, TF2, ..., TFN。 (TF: term frequency)。 那么,這個查詢和該網頁的相關性就是:TF1 + TF2 + ... + TFN。
讀者可能已經發現了又一個漏洞。在上面的例子中,詞“的”占了總詞頻的 80% 以上,而它對確定網頁的主題幾乎沒有用。我們稱這種詞叫“應刪除詞”(Stopwords),也就是說在度量相關性是不應考慮它們的頻率。在漢語中,應刪除詞還有“是”、“和”、“中”、“地”、“得”等等幾十個。忽略這些應刪除詞後,上述網頁的相似度就變成了0.007,其中“原子能”貢獻了 0.002,“套用”貢獻了 0.005。細心的讀者可能還會發現另一個小的漏洞。在漢語中,“套用”是個很通用的詞,而“原子能”是個很專業的詞,後者在相關性排名中比前者重要。因此我們需要給漢語中的每一個詞給一個權重,這個權重的設定必須滿足下面兩個條件:
1. 一個詞預測主題能力越強,權重就越大,反之,權重就越小。我們在網頁中看到“原子能”這個詞,或多或少地能了解網頁的主題。我們看到“套用”一次,對主題基本上還是一無所知。因此,“原子能“的權重就應該比套用大。
2. 應刪除詞的權重應該是零。
我們很容易發現,如果一個關鍵字只在很少的網頁中出現,我們通過它就容易鎖定搜尋目標,它的權重也就應該大。反之如果一個詞在大量網頁中出現,我們看到它仍然不是很清楚要找什麼內容,因此它應該小。概括地講,假定一個關鍵字 w 在 Dw 個網頁中出現過,那么 Dw 越大,w的權重越小,反之亦然。在信息檢索中,使用最多的權重是“逆文本頻率指數” (Inverse document frequency 縮寫為IDF),它的公式為log(D/Dw)其中D是全部網頁數。比如,我們假定中文網頁數是D=10億,應刪除詞“的”在所有的網頁中都出現,即Dw=10億,那么它的IDF=log(10億/10億)= log (1) = 0。假如專用詞“原子能”在兩百萬個網頁中出現,即Dw=200萬,則它的權重IDF=log(500) =2.7。又假定通用詞“套用”,出現在五億個網頁中,它的權重IDF = log(2)則只有 0.3。也就是說,在網頁中找到一個“原子能”的匹配相當於找到九個“套用”的匹配。利用 IDF,上述相關性計算的公式就由詞頻的簡單求和變成了加權求和,即 TF1*IDF1 + TF2*IDF2 +... + TFN*IDFN。在上面的例子中,該網頁和“原子能的套用”的相關性為 0.0069,其中“原子能”貢獻了 0.0054,而“套用”只貢獻了0.0015。這個比例和我們的直覺比較一致了。
套用
權重計算方法經常會和餘弦相似度(cosine similarity)一同使用於向量空間模型中,用以判斷兩份檔案之間的相似性。
理論假設
TFIDF算法是建立在這樣一個假設之上的:對區別文檔最有意義的詞語應該是那些在文檔中出現頻率高,而在整個文檔集合的其他文檔中出現頻率少的詞語,所以如果特徵空間坐標系取TF詞頻作為測度,就可以體現同類文本的特點。另外考慮到單詞區別不同類別的能力,TFIDF法認為一個單詞出現的文本頻數越小,它區別不同類別文本的能力就越大。因此引入了逆文本頻度IDF的概念,以TF和IDF的乘積作為特徵空間坐標系的取值測度,並用它完成對權值TF的調整,調整權值的目的在於突出重要單詞,抑制次要單詞。但是在本質上IDF是一種試圖抑制噪音的加權 ,並且單純地認為文本頻數小的單詞就越重要,文本頻數大的單詞就越無用,顯然這並不是完全正確的。IDF的簡單結構並不能有效地反映單詞的重要程度和特徵詞的分布情況,使其無法很好地完成對權值調整的功能,所以TFIDF法的精度並不是很高。
此外,在TFIDF算法中並沒有體現出單詞的位置信息,對於Web文檔而言,權重的計算方法應該體現出HTML的結構特徵。特徵詞在不同的標記符中對文章內容的反映程度不同,其權重的計算方法也應不同。因此應該對於處於網頁不同位置的特徵詞分別賦予不同的係數,然後乘以特徵詞的詞頻,以提高文本表示的效果。
模型機率
信息檢索概述
信息檢索是當前套用十分廣泛的一種技術,論文檢索、搜尋引擎都屬於信息檢索的範疇。通常,人們把信息檢索問題抽象為:在文檔集合D上,對於由關鍵字w[1] … w[k]組成的查詢串q,返回一個按查詢q和文檔d匹配度 relevance (q, d)排序的相關文檔列表D’。
對於這一基問題,先後出現了布爾模型、向量模型等各種經典的信息檢索模型,它們從不同的角度提出了自己的一套解決方案。布爾模型以集合的布爾運算為基礎,查詢效率高,但模型過於簡單,無法有效地對不同文檔進行排序,查詢效果不佳。向量模型把文檔和查詢串都視為詞所構成的多維向量,而文檔與查詢的相關性即對應於向量間的夾角。不過,由於通常詞的數量巨大,向量維度非常高,而大量的維度都是0,計算向量夾角的效果並不好。另外,龐大的計算量也使得向量模型幾乎不具有在網際網路搜尋引擎這樣海量數據集上實施的可行性。
tf-idf 模型
當前,真正在搜尋引擎等實際套用中廣泛使用的是 tf-idf 模型。tf-idf 模型的主要思想是:如果詞w在一篇文檔d中出現的頻率高,並且在其他文檔中很少出現,則認為詞w具有很好的區分能力,適合用來把文章d和其他文章區分開來。
信息檢索的機率視角
直觀上看,tf 描述的是文檔中詞出現的頻率;而 idf 是和詞出現文檔數相關的權重。我們比較容易定性地理解 tf-idf 的基本思想,但具體到 tf-idf 的一些細節卻並不是那么容易說清楚為什麼。
總結
TF-IDF 模型是搜尋引擎等實際套用中被廣泛使用的信息檢索模型,但對於 TF-IDF 模型一直存在各種疑問。本文為信息檢索問題一種基於條件機率的盒子小球模型,其核心思想是把“查詢串q和文檔d的匹配度問題”轉化為“查詢串q來自於文檔d的條件機率問題”。它從機率的視角為信息檢索問題定義了比 TF-IDF 模型所表達的匹配度更為清晰的目標。此模型可將 TF-IDF 模型納入其中,一方面解釋其合理性,另一方面也發現了其不完善之處。另外,此模型還可以解釋 PageRank 的意義,以及 PageRank 權重和 TF-IDF 權重之間為什麼是乘積關係。
