
歷史介紹
自人類的文字產生起,如何快速地從大量的,記錄在各種各樣的存儲媒體中查找或獲取信息就成為一個引人注目的問題。這個問題關係到人類如何能夠主動地獲取自己需要的知識。因此,文本信息檢索技術甚至可以追述到古代的書籍編目。但是直到近一個世紀,隨著人類的知識以前所未有的速度急劇膨脹,信息存儲方式越來越豐富,使得在海量的,多模態的信息庫中進行快速、準確的檢索成為急迫的需求。1945年,Vannevar Bush的論文《就像我們可能會想的……》 第一次提出了設計自動的,在大規模的存儲數據中進行查找的機器的構想。這被認為是現在信息檢索技術的開山之作。進入50年代後,研究者們開始為逐步的實現這些構想而努力。在50年代中期,在利用計算機對文本數據進行檢索的研究上,研究者獲取了一些成果。其中最有代表性的是Luhn在IBM公司的工作,他提出了利用詞對文檔構建索引並利用檢索與文檔中詞的匹配程度進行檢索 的方法,這種方法就是目前常用的倒排文檔技術的雛形。
在60年代,信息檢索技術的一些關鍵技術獲取了突破。其間出現了一些優秀的系統以及評價指標。在評價指標方面,由Cranfield的研究組組織的Cranfield評測提出了許多目前仍然被廣泛採用的評價指標,而在系統方面,Gernard Salton開發的SMART 系統構建了一個很好的研究平台,在此平台上,研究者可以定義自己的文檔相關性測度,以改進檢索性能。這樣,作為一個研究課題,信息檢索技術擁有了較為完善實驗平台與評價指標,其研究理所當然地步入了快車道。也正因為如此,在70年代到80年代,許多信息檢索的理論與模型被提出,並且被證明對當時所能獲得的數據集是有效的。其中最為著名的是Gerard Salton提出的向量空間模型。至今該模型還是信息檢索領域最為常用的模型之一。但是,檢索的對象——文本集合的缺乏使得這些技術在海量文本上的可靠性無法得到驗證。當時的研究大多針對數千篇的文檔組成的集合。這時,美國國家標準技術研究所(NIST)組織的文本檢索會議(Text Retrieval Conference, TREC)的召開改變了這一情況。TREC是一個評測性質的會議,為參評者提供了大規模的文本語料,從而大大推動了信息檢索技術的快速發展。會議的第一次召開是1992年,不久後,網際網路興起為信息檢索技術提供了一個巨大的實驗場。從Yahoo到Google,大量實用的文本信息檢索系統開始出現並得到廣泛套用。這些系統從事實上改變了人類獲取信息與知識的方式。
目前,在文本檢索領域,簡單的信息檢索已經開始向更加複雜且人性化的垂直搜尋演化,引入了信息抽取技術以提取文檔中的結構化信息。
模型
早期的信息檢索系統採用“布爾查詢”的方法來進行全文檢索。這種方法無疑將構造一個合適的查詢的責任推到用戶身上。用戶必須詳細的規劃自己的查詢,其複雜程度不亞於程式語言。這種檢索方式並不提供任何的文檔相關性測度,對於文檔與查詢的評價就只有“匹配”,“不匹配”兩種而已。這兩點問題決定了布爾查詢不能被廣泛套用。但是,由於布爾檢索能夠給用戶提供更多的可控制性,今天我們仍然可以在搜尋引擎的“高級搜尋”中找到布爾查詢的身影。
對於大規模的語料庫,任何檢索都可能返回數量眾多的結果,因此對檢索結果進行排序是必須的。因此,一個好的信息檢索模型必須提供文檔相關性測度。一個好的測度應該使與用戶查詢需求最相關的那些結果,排在最前面,同時允許儘可能多的,與用戶查詢有一定關係的結果被包括進來。目前,最為常用的信息檢索模型有三種:
•向量空間模型 (Vector Space Model, VSM)
•機率模型 (Probabilistic Model)
•推理網路模型 (Inference Network Model)
向量空間模型
向量空間模型最早由Gerard提出。在此模型中,一個文檔(Document)被描述成由一系列關鍵字(Term)組成的向量。模型並沒有規定關鍵字如何定義,但是一般來說,關鍵字可以是字,詞或者短語。在語音文檔檢索中,還可以是混淆類、音子、音子串等等單元。假設我們用“詞”作為Term,那么在詞典中的每一個詞,都定義向量空間中的一維。如果一篇文檔包含這個詞,那么表示這個文檔的向量在這個詞所定義的維度上應該擁有一個非0值(對絕大多數系統來說,是正值)。
當一個查詢被提交時,由於這個查詢也是由文本構成,所以也可以被向量空間所表示。模型將對查詢與文檔,計算一個 相似度需要注意的是,模型也沒有對相似度給出確切的定義。它可以使歐氏距離,也可以是兩個向量的夾角的餘弦。
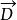 文本信息檢索技術
文本信息檢索技術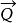 文本信息檢索技術
文本信息檢索技術假設 表示文檔向量,而 表示查詢向量,文檔與查詢的相關性可以用餘弦距離表示如下:
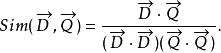 文本信息檢索技術
文本信息檢索技術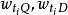 文本信息檢索技術
文本信息檢索技術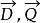 文本信息檢索技術
文本信息檢索技術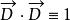 文本信息檢索技術
文本信息檢索技術如果我們用 表示 中的第 i維的值,並且對每個文檔矢量進行歸一化,即令 ,那么上式有可以表示為
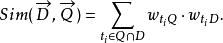 文本信息檢索技術
文本信息檢索技術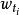 文本信息檢索技術
文本信息檢索技術在此,究竟如何取值是一個重要的問題,其取值一般被稱為關鍵字i在文檔D中的權重。關鍵字權重問題將在隨後進行專門的討論。
傳統向量空間模型的一個問題是各個維度間缺乏相關性,因而無法對文檔中各個詞的相關性提供信息。從巨觀上看,仍然沒有擺脫“關鍵字匹配”的窠臼。一個自然的想法就是對文檔特徵——文檔向量進行降維,將維數巨大的文檔向量投影到某個較小維度的空間中,使得關鍵字之間即使不完全匹配,也能夠根據語義發生關係。這就誕生了潛語義索引(Latent Semantic Indexing),它通過對向量空間進行奇異值分解,將高維文檔向量投射到低維潛語義空間中。潛語義索引隨後被融入機率模型框架中,形成了基於機率模型的PLSI(Probabilistic Latent Semantic Indexing), 和LDA(Latent Dirichlet Allocation)。
機率模型
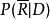 文本信息檢索技術
文本信息檢索技術機率模型的基本思想是估計文檔與查詢相 關聯機率,並對所有文檔根據關聯機率進行排序。這一模型最早由Maron和Kuhn在1960年提出。在給定查詢Q的情況下,用P(R|D)表示文檔與查詢相關的機率,而用表示文檔與查詢不相關的機率。 那么,就可以用
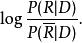 文本信息檢索技術
文本信息檢索技術對文檔進行排序。利用貝葉斯公式,可以很容易的將上面的公式變為產生式的形式:
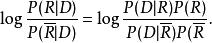 文本信息檢索技術
文本信息檢索技術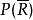 文本信息檢索技術
文本信息檢索技術由於P(R)和同文檔無關,上面的公式可以最終表示為:
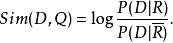 文本信息檢索技術
文本信息檢索技術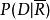 文本信息檢索技術
文本信息檢索技術機率模型的主要任務就集中在估計P(D|R)和上。
推理網路模型
推理網路模型是一種較上述兩中模型更為一般化的模型,上述模型都可以歸結為推理網路模型的一種實現。在此模型下,僅僅規定文檔以某種 “力度”產生某個來自查詢的關鍵字,至於力度如何定義,則完全沒有規定,即可以是機率,也可以是關鍵字權重。
倒排文檔索引技術
在信息檢索系統的具體實現中,需要快速地找到文檔中所包含的關鍵字。相比文檔來說,關鍵字的個數是較少的,因此,以關鍵字為核心對文檔進行索引是更加可行的方法。這就是信息檢索領域常用的“倒排文檔索引”技術。倒排文檔索引可以被看成一個鍊表數組,每個鍊表的表頭包含關鍵字,其後續單元則包括所有包括這個關鍵字的文檔標號,以及一些其他信息。這些信息可以是文檔中該詞的頻率,也可以是文檔中該詞的位置等信息。
倒排文檔索引的優勢不僅在於關鍵字個數少帶來的檢索效率提高,還在於其特別易於同信息檢索技術結合。在實際套用中,查詢中所包含的關鍵字往往是很少的,完全不包含查詢中的所有關鍵字的文檔,一般來說是不會被列入結果集的。因此,以關鍵字為主鍵進行索引,只需要用查詢中包括的關鍵字,進行幾次簡單的查詢就能夠找出所有可能的文檔。
倒排文檔索引的具體數據結構可以進行進一步的最佳化。在關鍵字查詢上,往往採用B-Tree或哈希表進行快速查詢。而文檔列表的數據結構則可以採用簡單的無序列表進行存儲,但是此種無序列表存在一個問題,就是當多個關鍵字對應的文檔集需要進行比較的時候,比較效率將比較低。因此,在實際套用中往往採用二叉搜尋樹組織文檔列表。
關鍵字權重
關鍵字對於區分文檔的作用是不同的。例如一些虛詞對於區分文檔的內容與查詢是否相關並沒有多大的意義。
對於機率模型而言,可以有完備的理論來估計每篇文檔生成某個詞的機率,因而其主要工作集中於如何確定較好的機率估計方法。而對於向量 空間模型來說,確定關鍵字權重在很大程度上依賴於研究者的經驗及對文檔特性的分析。
目前,對關鍵字權重的確定方法一般都需要獲取一些關於關鍵字的統計量,而後根據這些統計量,套用某種認為規定的計算公式來得到權重。 最常用的統計量包括:
•tf,Term Frequency的縮寫,表示某個關鍵字在某個文檔中出現的頻率。
•qtf,Query Term Frequency的縮寫。表示查詢中某關鍵字的出現頻率。
•N,集合中的文檔總數
•df,Document Frequency的縮寫,表示文檔集合中,出現某個關鍵字的文檔個數。
•idf,Inversed Document Frequency的縮寫。
•dl,文檔長度
•adl,平均文檔長度
在向量空間模型下,構造關鍵字權重計算公式有三個基本原則:
如果一個關鍵字在某個文檔中出現次數越多,那么這個詞應該被認為越重要。
如果一個關鍵字在越多的文檔中出現,那么這個詞區分文檔的作用就越低,於是其重要性也應當相應降低。
一篇文檔越長,那么其出現某個關鍵字的次數可能越高,而每個關鍵字對這個文檔的區分作用也越低,相應的應該對這些關鍵字予以一定的折扣。
1.如果一個關鍵字在某個文檔中出現次數越多,那么這個詞應該被認為越重要。
2.如果一個關鍵字在越多的文檔中出現,那么這個詞區分文檔的作用就越低,於是其重要性也應當相應降低。
3.一篇文檔越長,那么其出現某個關鍵字的次數可能越高,而每個關鍵字對這個文檔的區分作用也越低,相應的應該對這些關鍵字予以一定的折扣。
早期的權重往往直接採用 tf,但是顯然這種權重並沒有考慮上述第二條原則,因此在大規模系統中是不適用的。目前,常用的關鍵字權重計算公式大多基於 tf和 df進行構建,同時,一些較為複雜的計算公式也考慮了文檔長度。現簡要列舉如下:
TF-IDF得分。嚴格地說,TF/IDF得分並不特指某個計算公式,而是一個計算公式集合。其中TF與IDF都可以進行各種變換,究竟何種變換較能匹配實際需求,需要由實驗和套用來驗證。
