基本信息
TR規劃提供了一種通用的架構,可以套用到必須協調控制各個複雜子系統以實現更高層目標的很多領域。因此它融合了層次控制結構的從頂至下方法和基於主體的從底至上方法。產生的系統可以通過針對任務的簡單主體的合作來實現複雜的問題求解。這樣做的理由是簡單主體具有工作在較小的具有更多約束的問題空間內的優勢。另一方面,較高層的控制程式可以做出關於整個系統的更加全局性的決策,例如當前的純粹局部決策可能如何影響整個問題求解人物的結果。
Teleo意味著達到一個終點或者完成一個目標,Reactive意味著容易適應感知刺激(perceptual stimulus)。
發展背景
teleo-reactive(TR)規劃最初是由Nilsson(1994)和Benson(1995)在史丹福大學提出的。史丹福大學的Nilsson教授和他的學生們(尤其是Scott Benson)為teleo-reactive主體控制設計了一個系統。MIT的Rodney Brook(1991a,b)在人工生命的前提上創建了一個研究課題,也就是通過很多的簡單自治的主體的相互作用產生智慧型。與Brooks的工作相比,Nillson的研究提供了更為全局化的主體結構,並提供一些構件子系統,這些構件子系統能夠進行功能集成,在動態環境中提供健壯、靈活的性能。這些能力包括:對基於主體目標的環境情況做出適當的反應;選擇性地注意多個競爭的目標;當革新超過了設計者提供的常規範圍時計畫出新的行動方案;最後,知道行為的效果,以便計畫者能夠使用它們來創建出更可靠的計畫。
Nilsson和他的學生(Nilsson 1994,Benson 1995, Benson and Nilsson 1995)為主體控制設計了一個teleo-reactive(T-R)程式,這個程式不斷考慮改變的環境因素,為主體提供向目標前進的方向。這個程式的運行非常類似產生式系統,但也支持持續行為,或是在任意的時間周期中發生的行為,例如“向前直到……”,因此,與普通的產生式系統不同,條件值必須被不斷的計算,與當前最準確的條件關聯的行為通常是被執行的行為。
總結:
1)這項研究支持一個能做出計畫的體系結構,這個計畫需要模式化的反應程式。同時,這個結構也支持這樣的計畫:它允許主體對經常出現的環境做出適當的快速反應(因而是反應式的)。主體的行為還是動態的和目標驅動的(因而是遠程的)。
2)主體必須能維持隨時間變化的多個目標,並且能夠對這個目標組織採取相應的行動。
3)因為主體不可能存儲所有環境,所以對於主體來說,動態計畫出行動序列,並當環境發生變化時如有必要重新做出計畫,就顯得很重要。
4)與針對環境變化重新計畫關聯的是,系統學習的能力很重要。這項研究除了允許人偶爾去重新編碼T-R程式之外,還結合了學習和適應性方法,使主體能自動地改變它的程式。
特點
teleo-reactive控制組合了基於反饋控制和離散動作規劃的特徵。teleo-reactive程式序列化的執行已經彙編進一個面向計畫的動作。與更傳統的AI規劃環境(Weld,1994)不同,它不對動作的離散性和不可中斷性以及每個動作效果的完全可預測性做出任何假定。相反,teleo動作可以維持很長一段時期,也就是說只要teleo動作的前件事被滿足的而且與其關聯的目標還沒有實現,那么就執行這個動作。Nilsson(1994)稱這種類型的動作為可持續的。可持續動作可以在某個其他的更靠近頂層目標的動作被激活時打斷。一個很短的感知-反應循環保證了當環境變化時控制動作也會迅速改變以反映問題解得最新狀態。
算法內容
teleo-reactive動作序列使用一種被稱之為TR樹的數據結構來表示,如圖所示。TR樹是用一系列條件-動作對來描述的(也就是產生式規則)例如:
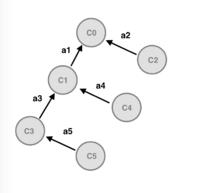 TR樹
TR樹C0 ->A0 , C1->A1 , C2->A2 , … ,Cn -> An
其中Ci是條件,Ai是與之關聯的動作。我們把C0稱為樹的最頂層目標,把A0稱為空動作,意思是一旦最頂層目標已經實現了,那么就不要再做任何事了。在teleo-reactive系統的每次循環中,從規則的最頂層向下評估每個Ci(C0,C1,……,Cn),直到找到第一個成立的條件。然後便執行與這個成立條件相關聯的動作。然後重複這個評估循環,重複頻率與電路控制的反應頻率接近。
Ci -> Ai 產生式是以這樣一種方式組織:對於每個動作Ai來說,如果正常情況下不斷執行這個動作,那么它最終可以使TR規則樹(見圖)中某個更高的條件為真。可以把TR樹的執行看成是可適應的,因為如果在控制環境中某個未預料到的事件逆轉了前面動作的效果,那么TR執行過程會退回到較低層反映那個條件的規則條件。從這一點來看,它會根據滿足所有更高層目標的需要重新啟動。類似的,如果意外發生了某個好的現象,那么TR執行過程會自動切換到對應於這個成立條件的動作,從這個意義上來說,它具有機會性。
可以使用一種AI中很普遍的目標縮減方法來構建TR樹。規劃程式從頂層目標開始搜尋其結果包含要實現目標的動作。搜尋到動作的前件產生了新的子目標集合,因此這個過程是遞歸的。當環境中的當前狀態滿足葉子結點的前件時搜尋便終止。因此這種規划算法是從最頂層目標通過目標縮減方法回歸到當前狀態。當然,一些動作經常會有副作用,因此規劃程式必須仔細地驗證任何層的動作不會改變那些是TR樹上更高層動作前件的條件。因此,目標縮減是在有約束的情況下進行的,在這個過程中可以採用各種不同的動作排序策略來消除可能的約束衝突。
因此,TR規划算法是用來建立問題域中當前狀態可以滿足葉子結點的計畫。它通常不建立完整的計畫——即可以從任何世界狀態啟動的計畫,因為這樣的計畫通常過於龐大,難以存儲和被高效地執行。這一點是很重要的,因為有時一個未預料到的環境事件可能把世界切換到一種TR樹中的所有動作前件都不滿足因此有必要重新規劃的狀態。這通常是通過重新激活TR規劃程式來完成的。
Benson(1994)和Nilsson(1995)已經把teleo-reactive規劃套用到很多領域,包括控制分布機器人主體和建立飛行模擬器。Klein et al.(1999,2000)已經使用teleo-reactive規劃程式來建立和檢驗一種可移植的控制結構來加速粒子束。這些研究指出在粒子束控制領域使用teleo-reactive控制程式有很多好處:
1)加速器粒子束及其相關的診斷通常是動態的而且是有噪聲的。
2)加速器調節目標的實現經常是通過隨機過程、RF衰弱或粒子源的擺動來實現的。
3)調節所需的很多動作是可持續的。尤其當需要繼續調整和最佳化操作直到滿足特定標準的時候。
4)TR樹為加速器設計者提供了一種直觀的框架用來編排調節計畫。事實上在一點點幫助下,設計者們便能夠開發出自己的TR樹。
例子
我們考慮一個關於機器人的TR程式。機器人通過把罐子移動到倉庫中來
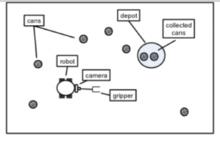 機器人與環境
機器人與環境清除地面上的罐子。機器人可以旋轉,可以掃描環境尋找罐子或倉庫,可以向前移動,也可以關閉或開啟它的夾子。機器人擁有評測機器人是否持有,看見或者觸碰到罐子的感測器。比如,如果一個機器人看見一個罐子,然後當它可以看見罐子的時候它會向前移動。假設環境不移動罐子,機器人最終會觸碰到它。使用它現在的位置,機器人可以看見倉庫並且知道它是否在倉庫的位置。
由上面的描述可以得到TR程式:
holding and at_depot → ungrasp
holding and see_depot → forward
holding → rotate
see_can and touching → grasp
see_can → forward
true → rotate
條件holding, see_can, at_depot, see_depot, 和touching是Boolean變數,其值等於機器人對應的感測器的值。機器人原始的動作時‘rotate’,‘foward’,‘grasp’,和‘ungrasp’,這些控制著機器人最基本的移動。
下面是機器人TR程式的分層版本:
Robot:
holding → Deliver
true → Collect
Collect:
see_can → Fetch
true → rotate
Fetch:
touching → grasp
true → forward
Deliver:
at_depot → ungrasp
true → Go_depot
Go_depot:
see_depot → forward
True → rotate
我們可以看出TR程式包含一個根目標(‘Robot’)和四個子目標。子目標的完成令機器人的系統進入了一個特定的狀態。動作(子目標)Deliver和Collect導致了機器人分別傳遞和罐子。除此之外,傳遞擴展到原始的動作‘ungrasp’和子目標 Go_depot。因為子目標Fetch是子目標Collect的最後一個動作,兩個子目標都在同一時間完成,系統最終持有相同的狀態(holding),到此為止,第一個動作Deliver的完成代表著目標的完成,而第二個動作Collect的完成代表著導致機器人有可能完成動作Deliver的子目標的完成。‘ungrasp’活動的完成代表著Deliver的完成(因為holding變為false)。而‘Go_depot’的完成使機器人可以‘ungrasp’ 。
軟體和工具
N. Nilsson, An animated Java applet of a block-stacking robot using the triple-tower architecture and T-R programs.
Weiglhofer M (2007) Extended Teleo-Reactive Compiler.
1.N. Nilsson, An animated Java applet of a block-stacking robot using the triple-tower architecture and T-R programs.
2.Weiglhofer M (2007) Extended Teleo-Reactive Compiler.
相關出版物
Books
K. L. Clark and P. J. Robinson, Programming Robotic Agents: A Teleo-Reactive Multi-Tasking Approach, to appear, 2016, Springer.
Book Chapters
Benson, S., and Nilsson, N., “ Reacting, Planning and Learning in an Autonomous Agent”, in Machine Intelligence 14, K. Furukawa, D.Michie, and S.Muggleton, (eds.),Oxford: the Clarendon Press, 1995. [An early paper describing learning and architectural ideas]
Kochenderfer, M., “ Evolving Hierarchical and Recursive Teleo-reactive Programs through Genetic Programming” ,Springer Lecture Notes on Computer Science, 2003.
Asghar, M.R., Russello, G. “ Automating consent management lifecycle for electronic healthcare systems Medical Data Privacy Handbook“, pp. 361-387. 2005.
PhD, Msc & undergraduate Theses
Benson, S., Learning Action Models for Reactive Autonomous Agents, PhD Thesis, Department of Computer Science,StanfordUniversity, 1996. [Explores how T-R programs can be generated by an automatic planning system using action effect descriptions learned through experience by an extension of inductive logic programming methods]
Moreno F. Task Specification for Drones using the Teleo-Reactive Approach. Undergraduate thesis, Technical University of Cartagena, Supervisor: Pedro Sánchez Palma, Spain, September 2015.
Vargas B., Aprendizaje de Programas Teleo-Reactivos para Robótica Móvil, PhD Thesis, Instituto Nacional de Astrofísica, Óptica y Electrónica, 2009.
Webb R. Implementing a teleo-reactive programming system, PhD Thesis,(Submitted on 14 Sep 2015).
Other
Champandard A.J., “ Teleo-Reactive Programs for Agent Control“, Web review published inDecember 20, 2007.
Dongol B, Hayes IJ, Robinson PJ., “ Reasoning About Real-Time Teleo-Reactive Programs“, Technical Report SSE-2010-01, Division of Systems and Software Engineering Research, The University of Queensland, 2010
Gamble C, Riddle S.,” Dependability Explicit Metadata: Extended Report on Properties, Policies and Exemplary Application to Case Studies”, Technical Report CS-TR-1248, The Newcastle University, 2011.
Gordon, E., and Logan, B.,“ GRUE: A Goal Processing Architecture for Game Agents”, Computer Science Technical Report No. NOTTCS-WP-2003-1, School of Computer Science and Information Technology, University of Nottingham, 2003.
Kowalski R, Sadri F., “ Teleo-Reactive Abductive Logic Program”,Technical Report. The Imperial College London, 2011
Mousavi SR, Broda K., “ Simplification of Teleo-Reactive Sequences”, Technical Report, Imperial College London, 2003.
Nilsson, N., “ Toward Agent Programs with Circuit Semantics“, Technical Report STAN-CS-92-1412, Stanford University Computer Science Department, 1992. [A Stanford Technical Note introducing T-R programs]
Nilsson, N. J., “ Learning Strategies for Mid-Level Robot Control: Some Preliminary Considerations and Results”, May, 2000. [Discusses prospects for learning T-R programs, describes some initial experiments, and makes some proposals.]
Saigol Z, Py F, Rajan K, McGann C, Wyatt J, Dearden R., “ Randomized Testing for Robotic Plan Execution for Autonomous Systems”, In: Proceedings of IEEE/OES-10, 2010.
Salomaki B, Choi D, Nejati N, Langley P., “ Learning Teleoreactive Logic Programs by Observation”, In: Proceedings of AAAI-05, 2005.
Srinivasan, P., “ Development of Block-Stacking Teleo-Reactive Programs Using Genetic Programming”, (Student paper), 2002.
