
概念介紹
用官方的話來說,所謂K近鄰算法,即是給定一個訓練數據集,對新的輸入實例,在訓練數據集中找到與該實例最鄰近的K個實例(也就是上面所說的K個鄰居), 這K個實例的多數屬於某個類,就把該輸入實例分類到這個類中。
案例介紹
如右圖所示,有兩類不同的樣本數據,分別用藍色的小正方形和紅色的小三角形表示,而圖正中間的那個綠色的圓所標示的數據則是待分類的數據。也就是說,現在, 我們不知道中間那個綠色的數據是從屬於哪一類(藍色小正方形or紅色小三角形),下面,我們就要解決這個問題:給這個綠色的圓分類。
我們常說,物以類聚,人以群分,判別一個人是一個什麼樣品質特徵的人,常常可以從他/她身邊的朋友入手,所謂觀其友,而識其人。我們不是要判別上圖中那個綠色的圓是屬於哪一類數據么,好說,從它的鄰居下手。但一次性看多少個鄰居呢?從上圖中,你還能看到:
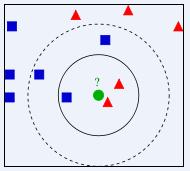 k近鄰算法
k近鄰算法•如果K=3,綠色圓點的最近的3個鄰居是2個紅色小三角形和1個藍色小正方形,少數從屬於多數,基於統計的方法,判定綠色的這個待分類點屬於紅色的三角形一類。
•如果K=5,綠色圓點的最近的5個鄰居是2個紅色三角形和3個藍色的正方形,還是少數從屬於多數,基於統計的方法,判定綠色的這個待分類點屬於藍色的正方形一類。
於此我們看到,當無法判定當前待分類點是從屬於已知分類中的哪一類時,我們可以依據統計學的理論看它所處的位置特徵,衡量它周圍鄰居的權重,而把它歸為(或分配)到權重更大的那一類。這就是K近鄰算法的核心思想。
KNN算法中,所選擇的鄰居都是已經正確分類的對象。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
KNN 算法本身簡單有效,它是一種 lazy-learning 算法,分類器不需要使用訓練集進行訓練,訓練時間複雜度為0。KNN 分類的計算複雜度和訓練集中的文檔數目成正比,也就是說,如果訓練集中文檔總數為 n,那么 KNN 的分類時間複雜度為O(n)。
KNN方法雖然從原理上也依賴於極限定理,但在類別決策時,只與極少量的相鄰樣本有關。由於KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對於類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。
K 近鄰算法使用的模型實際上對應於對特徵空間的劃分。K 值的選擇,距離度量和分類決策規則是該算法的三個基本要素:
K 值的選擇會對算法的結果產生重大影響。K值較小意味著只有與輸入實例較近的訓練實例才會對預測結果起作用,但容易發生過擬合;如果 K 值較大,優點是可以減少學習的估計誤差,但缺點是學習的近似誤差增大,這時與輸入實例較遠的訓練實例也會對預測起作用,使預測發生錯誤。在實際套用中,K 值一般選擇一個較小的數值,通常採用交叉驗證的方法來選擇最優的 K 值。隨著訓練實例數目趨向於無窮和 K=1 時,誤差率不會超過貝葉斯誤差率的2倍,如果K也趨向於無窮,則誤差率趨向於貝葉斯誤差率。
該算法中的分類決策規則往往是多數表決,即由輸入實例的 K 個最臨近的訓練實例中的多數類決定輸入實例的類別
距離度量一般採用 Lp 距離,當p=2時,即為歐氏距離,在度量之前,應該將每個屬性的值規範化,這樣有助於防止具有較大初始值域的屬性比具有較小初始值域的屬性的權重過大。
1.K 值的選擇會對算法的結果產生重大影響。K值較小意味著只有與輸入實例較近的訓練實例才會對預測結果起作用,但容易發生過擬合;如果 K 值較大,優點是可以減少學習的估計誤差,但缺點是學習的近似誤差增大,這時與輸入實例較遠的訓練實例也會對預測起作用,使預測發生錯誤。在實際套用中,K 值一般選擇一個較小的數值,通常採用交叉驗證的方法來選擇最優的 K 值。隨著訓練實例數目趨向於無窮和 K=1 時,誤差率不會超過貝葉斯誤差率的2倍,如果K也趨向於無窮,則誤差率趨向於貝葉斯誤差率。
2.該算法中的分類決策規則往往是多數表決,即由輸入實例的 K 個最臨近的訓練實例中的多數類決定輸入實例的類別
3.距離度量一般採用 Lp 距離,當p=2時,即為歐氏距離,在度量之前,應該將每個屬性的值規範化,這樣有助於防止具有較大初始值域的屬性比具有較小初始值域的屬性的權重過大。
KNN算法不僅可以用於分類,還可以用於回歸。通過找出一個樣本的k個最近鄰居,將這些鄰居的屬性的平均值賦給該樣本,就可以得到該樣本的屬性。更有用的方法是將不同距離的鄰居對該樣本產生的影響給予不同的權值(weight),如權值與距離成反比。 該算法在分類時有個主要的不足是,當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導致當輸入一個新樣本時,該樣本的K個鄰居中大容量類的樣本占多數。 該算法只計算“最近的”鄰居樣本,某一類的樣本數量很大,那么或者這類樣本並不接近目標樣本,或者這類樣本很靠近目標樣本。無論怎樣,數量並不能影響運行結果。可以採用權值的方法(和該樣本距離小的鄰居權值大)來改進。
該方法的另一個不足之處是計算量較大,因為對每一個待分類的文本都要計算它到全體已知樣本的距離,才能求得它的K個最近鄰點。目前常用的解決方法是事先對已知樣本點進行剪輯,事先去除對分類作用不大的樣本。該算法比較適用於樣本容量比較大的類域的自動分類,而那些樣本容量較小的類域採用這種算法比較容易產生誤分。
實現 K 近鄰算法時,主要考慮的問題是如何對訓練數據進行快速 K 近鄰搜尋,這在特徵空間維數大及訓練數據容量大時非常必要。
