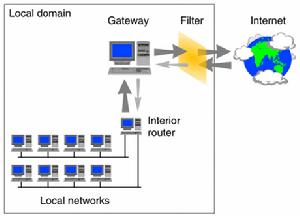
 PF防火牆
PF防火牆是 UNIX LIKE 系統上進行 TCP/IP流量過濾和網路地址轉換的軟體系統。PF 同樣也能提供 TCP/IP 流量的整形和控制,並且提供頻寬控制和數據包優先集控制。
PF 最早是由 Daniel Hartmeier開發的,現在的開發和維護由 Daniel 和 openBSD小組的其他成員負責。
基本配置
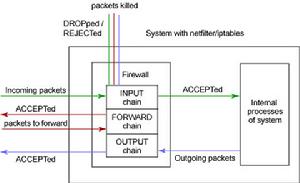 PF防火牆
PF防火牆要激活 pf 並且使它在啟動時調用配置檔案,編輯 /etc/rc.conf 檔案,修改配置pf的一行:
pf=YES
重啟作業系統讓配置生效。
也可以通過pfctl程式啟動和停止pf
# pfctl -e
# pfctl -d
注意這僅僅是啟動和關閉PF,實際它不會載入規則集,規則集要么在系統啟動時載入,要在PF啟動後通過命令單獨載入。
配置
系統引導到在rc腳本檔案運行PF時PF從/etc/pf.conf檔案載入配置規則。注意當/etc/pf.conf檔案是默認配置檔案,在系統調用rc腳本檔案時,它僅僅是作為文本檔案由pfctl裝入並解釋和插入pf的。對於一些套用來說,其他的規則集可以在系統引導後由其他檔案載入。對於一些設計的非常好的unix程式,PF提供了足夠的靈活性。
pf.conf 檔案有7個部分:
* 宏: 用戶定義的變數,包括IP地址,接口名稱等等
* 表: 一種用來保存IP位址列表的結構
* 選項:控制PF如何工作的變數
* 整形: 重新處理數據包,進行正常化和碎片整理
* 排隊: 提供頻寬控制和數據包優先權控制.
* 轉換: 控制網路地址轉換和數據包重定向.
* 過濾規則: 在數據包通過接口時允許進行選擇性的過濾和阻止
除去宏和表,其他的段在配置檔案中也應該按照這個順序出現,儘管對於一些特定的套用並不是所有的段都是必須的。
空行會被忽略,以#開頭的行被認為是注釋.
 # pfctl -sa
# pfctl -sa引導之後,PF可以通過pfctl程式進行操作,以下是一些例子:
# pfctl -f /etc/pf.conf 載入 pf.conf 檔案
# pfctl -nf /etc/pf.conf 解析檔案,但不載入
# pfctl -Nf /etc/pf.conf 只載入檔案中的NAT規則
# pfctl -Rf /etc/pf.conf 只載入檔案中的過濾規則
# pfctl -sn 顯示當前的NAT規則
# pfctl -sr 顯示當前的過濾規則
# pfctl -ss 顯示當前的狀態表
# pfctl -si 顯示過濾狀態和計數
# pfctl -sa 顯示任何可顯示的
完整的命令列表,請參閱pfctl的man手冊頁。
列表和宏
列表
一個列表允許一個規則集中指定多個相似的標準。例如,多個協定,連線埠號,網路地址等等。因此,不需要為每一個需要阻止的IP位址編寫一個過濾規則,一條規則可以在列表中指定多個IP位址。列表的定義是將要指定的條目放在{ }大括弧中。
當pfctl在載入規則集碰到列表時,它產生多個規則,每條規則對於列表中的一個條目。例如:
block out on fxp0 from { 192.168.0.1, 10.5.32.6 } to any
展開後:
block out on fxp0 from 192.168.0.1 to any
block out on fxp0 from 10.5.32.6 to any
多種列表可以在規則中使用,並不僅僅限於過濾規則:
rdr on fxp0 proto tcp from any to any port { 22 80 } -> \
192.168.0.6
block out on fxp0 proto { tcp udp } from { 192.168.0.1, \
10.5.32.6 } to any port { ssh telnet }
注意逗號在列表條目之間是可有可無的。
宏
宏是用戶定義變數用來指定IP位址,連線埠號,接口名稱等等。宏可以降低PF規則集的複雜度並且使得維護規則集變得容易。
宏名稱必須以字母開頭,可以包括字母,數字和下劃線。宏名稱不能包括保留關鍵字如:
pass, out, 以及 queue.
ext_if = "fxp0"
block in on $ext_if from any to any
這生成了一個宏名稱為ext_if. 當一個宏在它產生以後被引用時,它的名稱前面以$字元開頭。
宏也可以展開成列表,如:
friends = "{ 192.168.1.1, 10.0.2.5, 192.168.43.53 }"
宏能夠被重複定義,由於宏不能在引號內被擴展,因此必須使用下面得語法:
host1 = "192.168.1.1"
host2 = "192.168.1.2"
all_hosts = "{" $host1 $host2 "}"
宏 $all_hosts 現在會展開成 192.168.1.1, 192.168.1.2.
表
 PF防火牆
PF防火牆表是用來保存一組IPv4或者IPv6地址。在表中進行查詢是非常快的,並且比列表消耗更少的記憶體和cpu時間。由於這個原因,表是保存大量地址的最好方法,在50,000個地址中查詢僅比在50個地址中查詢稍微多一點時間。表可以用於下列用途:
* 過濾,整形,NAT和重定向中的源或者目的地址.
* NAT規則中的轉換地址.
* 重定向規則中的重定向地址.
* 過濾規則選項中 route-to, reply-to, 和 dup-to的目的地址.
表可以通過在pf.conf里配置和使用pfctl生成。
配置
在pf.conf檔案中, 表是使用table關鍵字創建出來的。下面的關鍵字必須在創建表時指定。
* constant - 這類表的內容一旦創建出來就不能被改變。如果這個屬性沒有指定,可以使用pfctl添加和刪除表里的地址,即使系統是運行在2或者更高得安全級別上。
* persist - 即使沒有規則引用這類表,核心也會把它保留在記憶體中。如果這個屬性沒有指定,當最後引用它的規則被取消後核心自動把它移出記憶體。
實例:
table { 192.0.2.0/24 }
table const { 192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }
table persist
block in on fxp0 from { , } to any
pass in on fxp0 from to any
地址也可以用“非”來進行修改,如:
table { 192.0.2.0/24, !192.0.2.5 }
goodguys表將匹配除192.0.2.5外192.0.2.0/24網段得所有地址。
注意表名總是在符號得裡面。
表也可以由包含IP位址和網路地址的文本檔案中輸入:
table persist file "/etc/spammers"
block in on fxp0 from to any
檔案 /etc/spammers 應該包含被阻塞的IP位址或者CIDR網路地址,每個條目一行。以#開頭的行被認為是注釋會被忽略。
用 pfctl 進行操作
表可以使用pfctl進行靈活的操作。例如,在上面產生的表中增加條目可以這樣寫:
# pfctl -t spammers -T add 218.70.0.0/16
如果這個表不存在,這樣會創建出這個表來。列出表中的內容可以這樣:
# pfctl -t spammers -T show
-v 參數也可以使用-Tshow 來顯示每個表的條目內容統計。要從表中刪除條目,可以這樣:
# pfctl -t spammers -T delete 218.70.0.0/16
指定地址
除了使用IP位址來指定主機外,也可以使用主機名。當主機名被解析成IP位址時,IPv4和IPv6地址都被插進規則中。IP位址也可以通過合法的接口名稱或者self關鍵字輸入表中,這樣的表會分別包含接口或者機器上(包括loopback地址)上配置的所有IP位址。
一個限制時指定地址0.0.0.0/0 以及 0/0在表中不能工作。替代方法是明確輸入該地址或者使用宏。
地址匹配
表中的地址查詢會匹配最接近的規則,比如:
table { 172.16.0.0/16, !172.16.1.0/24, 172.16.1.100 }
block in on dc0 all
pass in on dc0 from to any
任何自dc0上數據包都會把它的源地址和goodguys表中的地址進行匹配:
* 172.16.50.5 - 精確匹配172.16.0.0/16; 數據包符合可以通過
* 172.16.1.25 - 精確匹配!172.16.1.0/24; 數據包匹配表中的一條規則,但規則是“非”(使用“!”進行了修改);數據包不匹配表會被阻塞。
* 172.16.1.100 - 準確匹配172.16.1.100; 數據包匹配表,運行通過
* 10.1.4.55 - 不匹配表,阻塞。
包過濾
 PF防火牆
PF防火牆包過濾是在數據包通過網路接口時進行選擇性的運行通過或者阻塞。pf檢查包時使用的標準是基於的3層(IPV4或者IPV6)和4層(TCP, UDP, ICMP, ICMPv6)包頭。最常用的標準是源和目的地址,源和目的連線埠,以及協定。
過濾規則集指定了數據包必須匹配的標準和規則集作用後的結果,在規則集匹配時通過或者阻塞。規則集由開始到結束順序執行。除非數據包匹配的規則包含quick關鍵字,否則數據包在最終執行動作前會通過所有的規則檢驗。最後匹配的規則具有決定性,決定了數據包最終的執行結果。存在一條潛在的規則是如果數據包和規則集中的所有規則都不匹配,則它會被通過。
規則語法
一般而言,最簡單的過濾規則語法是這樣的:
action direction [log] [quick] on interface [af] [proto protocol] \
from src_addr [port src_port] to dst_addr [port dst_port] \
[tcp_flags] [state]
action
數據包匹配規則時執行的動作,放行或者阻塞。放行動作把數據包傳遞給核心進行進一步出來,阻塞動作根據block-policy 選項指定的方法進行處理。默認的動作可以修改為阻塞丟棄或者阻塞返回。
direction
數據包傳遞的方向,進或者出
log
指定數據包被pflogd( 進行日誌記錄。如果規則指定了keep state, modulate state, or synproxy state 選項,則只有建立了連線的狀態被日誌。要記錄所有的日誌,使用log-all
quick
如果數據包匹配的規則指定了quick關鍵字,則這條規則被認為時最終的匹配規則,指定的動作會立即執行。
interface
數據包通過的網路接口的名稱或組。組是接口的名稱但沒有最後的整數。比如ppp或fxp,會使得規則分別匹配任何ppp或者fxp接口上的任意數據包。
af
數據包的地址類型,inet代表Ipv4,inet6代表Ipv6。通常PF能夠根據源或者目標地址自動確定這個參數。
protocol
數據包的4層協定:
tcp
udp
icmp
icmp6
/etc/protocols中的協定名稱
0~255之間的協定號
使用列表的一系列協定.
src_addr, dst_addr
IP頭中的源/目標地址。地址可以指定為:
單個的Ipv4或者Ipv6地址.
CIDR 網路地址.
能夠在規則集載入時通過DNS解析到的合法的域名,IP位址會替代規則中的域名。
網路接口名稱。網路接口上配置的所有ip地址會替代進規則中。
帶有/掩碼(例如/24)的網路接口的名稱。每個根據掩碼確定的CIDR網路地址都會被替代進規則中。.
帶有()的網路接口名稱。這告訴PF如果網路接口的IP位址改變了,就更新規則集。這個對於使用DHCP或者撥號來獲得IP位址的接口特別有用,IP位址改變時不需要重新載入規則集。
帶有如下的修飾詞的網路接口名稱:
o :network - 替代CIDR網路地址段 (例如:192.168.0.0/24)
o :broadcast - 替代網路廣播地址(例如:192.168.0.255)
o :peer - 替代點到點鏈路上的ip地址。
另外,:0修飾詞可以附加到接口名稱或者上面的修飾詞後面指示PF在替代時不包括網路接口的其餘附加(alias)地址。這些修飾詞也可以在接口名稱在括弧()內時使用。例如:fxp0:network:0
表.
上面的所有項但使用!(非)修飾詞
使用列表的一系列地址.
關鍵字 any 代表所有地址
關鍵字 all 是 from any to any的縮寫。
src_port, dst_port
4層數據包頭中的源/目標連線埠。連線埠可以指定為:
1 到 65535之間的整數
/etc/services中的合法服務名稱
使用列表的一系列連線埠
一個範圍:
o != (不等於)
o (大於)
o = (大於等於)
o > (反轉範圍)
最後2個是二元操作符(他們需要2個參數),在範圍內不包括參數。
o : (inclusive range)
inclusive range 也是二元操作符但範圍內包括參數。
tcp_flags
指定使用TCP協定時TCP頭中必須設定的標記。 標記指定的格式是: flags check/mask. 例如: flags S/SA -這指引PF只檢查S和A(SYN and ACK)標記,如果SYN標記是“on”則匹配。
state
指定狀態信息在規則匹配時是否保持。
keep state - 對 TCP, UDP, ICMP起作用
modulate state - 只對 TCP起作用. PF會為匹配規則的數據包產生強壯的初始化序列號。
synproxy state - 代理外來的TCP連線以保護伺服器不受TCP SYN FLOODs欺騙。這個選項包含了keep state 和 modulate state 的功能。
默認拒絕
按照慣例建立防火牆時推薦執行的是默認拒絕的方法。也就是說先拒絕所有的東西,然後有選擇的允許某些特定的流量通過防火牆。這個方法之所以是推薦的是因為它寧可失之過於謹慎(也不放過任何風險),而且使得編寫規則集變得簡單。
產生一個默認拒絕的過濾規則,開始2行過濾規則必須是:
block in all
block out all
這會阻塞任何通信方在任何方向上進入任意接口的所有流量。
通過流量
流量必須被明確的允許通過防火牆或者被默認拒絕的策略丟棄。這是數據包標準如源/目的連線埠,源/目的地址和協定開始活動的地方。無論何時數據包在被允許通過防火牆時規則都要設計的儘可能嚴厲。這是為了保證設計中的流量,也只有設計中的流量可以被允許通過。
實例:
# 允許本地網路192.168.0.0/24流量通過dc0接口進入訪問openbsd機器的IP位址
#192.168.0.1,同時也允許返回的數據包從dc0接口出去。
pass in on dc0 from 192.168.0.0/24 to 192.168.0.1
pass out on dc0 from 192.168.0.1 to 192.168.0.0/24
# Pass TCP traffic in on fxp0 to the web server running on the
# OpenBSD machine. The interface name, fxp0, is used as the
# Destination Address so that packets will only match this rule if
# they‘re destined for the OpenBSD machine.
pass in on fxp0 proto tcp from any to fxp0 port www
quick 關鍵字
每個數據包都要按自上至下的順序按規則進行過濾。默認情況下,數據包被標記為通過,這個可以被任一規則改變,在到達最後一條規則前可以被來回改變多次,最後的匹配規則是“獲勝者”。存在一個例外是:過濾規則中的quick關鍵字具有取消進一步往下處理的作用,使得規則指定的動作馬上執行。看一下下面的例子:
錯誤:
block in on fxp0 proto tcp from any to any port ssh
pass in all
在這樣的條件下,block行會被檢測,但永遠也不會有效果,因為它後面的一行允許所有的流量通過。
正確:
block in quick on fxp0 proto tcp from any to any port ssh
pass in all
這些規則執行的結果稍有不同,如果block行被匹配,由於quick選項的原因,數據包會被阻塞,而且剩下的規則也會被忽略。
狀態保持
PF一個非常重要的功能是“狀態保持”或者“狀態檢測”。狀態檢測指PF跟蹤或者處理網路連線狀態的能力。通過存貯每個連線的信息到一個狀態表中,PF能夠快速確定一個通過防火牆的數據包是否屬於已經建立的連線。如果是,它會直接通過防火牆而不用再進行規則檢驗。
狀態保持有許多的優點,包括簡單的規則集和優良的數據包處理性能。
PF is able to match packets moving in either direction to state table entries meaning that filter rules which pass returning trafficdon‘t need to be written.
並且,由於數據包匹配狀態連線時不再進行規則集的匹配檢測,PF用於處理這些數據包的時間大為減少。
當一條規則使用了keep state選項,第一個匹配這條規則的數據包在收發雙方之間建立了一個狀態。現在,不僅傳送者到接收者之間的數據包匹配這個狀態繞過規則檢驗,而且接收者回復傳送者的數據包也是同樣的。例如:
pass out on fxp0 proto tcp from any to any keep state
這允許fxp0接口上的任何TCP流量通過,並且允許返回的流量通過防火牆。狀態保持是一個非常有用的特性,由於狀態查詢比使用規則進行數據包檢驗快的多,因此它可以大幅度提高防火牆的性能。
狀態調整選項和狀態保持的功能在除了僅適用於TCP數據包以為完全相同。在使用狀態調整時,輸入連線的初始化序列號(ISN)是隨機的,這對於保護某些選擇ISN存在問題的作業系統的連線初始化非常有用。從openbsd 3.5開始,狀態調整選項可以套用於包含非TCP的協定規則。
對輸出的TCP, UDP, icmp數據包保持狀態,並且調整TCP ISN。
pass out on fxp0 proto { tcp, udp, icmp } from any to any modulate state
狀態保持的另一個優點是ICMP通信流量可以直接通過防火牆。例如,如果一個TCP連線使用了狀態保持,當和這個TCP連線相關的ICMP數據包到來時,它會自動找到合適的狀態記錄,直接通過防火牆。
狀態記錄的範圍被state-policy runtime選項總體控制,也能基於單條規則由if-bound, group-bound, 和 floating state選項關鍵字設定。這些針對單條規則的關鍵字在使用時具有和state-policy選項同樣的意義。例如:
pass out on fxp0 proto { tcp, udp, icmp } from any to any modulate state (if-bound)
狀態規則指示為了使數據包匹配狀態條目,它們必須通過fxp0網路接口傳遞。
需要注意的是,nat,binat,rdr規則隱含在連線通過過濾規則集審核的過程中產生匹配連線的狀態。
UDP狀態保持
“不能為UDP產生狀態,因為UDP是無狀態的協定”。確實,UDP通信會話沒有狀態的概念(明確的開始和結束通信),這絲毫不影響PF為 UDP會話產生狀態的能力。對於沒有開始和結束數據包的協定,PF僅簡單追蹤匹配的數據部通過的時間。如果到達逾時限制,狀態被清除,逾時的時間值可以在pf.conf配置檔案中設定。
TCP 標記
基於標記的TCP包匹配經常被用於過濾試圖打開新連線的TCP數據包。TCP標記和他們的意義如下所列:
* F : FIN - 結束; 結束會話
* S : SYN - 同步; 表示開始會話請求
* R :RST - 復位;中斷一個連線
* P : PUSH - 推送; 數據包立即傳送
* A : ACK - 應答
* U : URG - 緊急
* E : ECE - 顯式擁塞提醒回應
* W : CWR - 擁塞視窗減少
要使PF在規則檢查過程中檢查TCP標記,flag關鍵需按如下語法設定。
flags check/mask
mask部分告訴PF僅檢查指定的標記,check部分說明在數據包頭中哪個標記設定為“on”才算匹配。
pass in on fxp0 proto tcp from any to any port ssh flags S/SA
上面的規則通過的帶SYN標記的TCP流量僅查看SYN和ACK標記。帶有SYN和ECE標記的數據包會匹配上面的規則,而帶有SYN和ACK的數據包或者僅帶有ACK的數據包不會匹配。
注意:在前面的openbsd版本中,下面的語法是支持的:
. . . flags S
現在,這個不再支持,mask必須被說明。
標記常常和狀態保持規則聯合使用來控制創建狀態條目:
pass out on fxp0 proto tcp all flags S/SA keep state
這條規則允許為所有輸出中帶SYN和ACK標記的數據包中的僅帶有SYN標記的TCP數據包創建狀態。
使用標記時必須小心,理解在做什麼和為什麼這樣做。小心聽取建議,因為相當多的建議時不好的。一些人建議創建狀態“只有當SYN標記設定而沒有其他標記”時,這樣的規則如下:
. . . flags S/FSRPAUEW 糟糕的主意!!
這個理論是,僅為TCP開始會話時創建狀態,會話會以SYN標記開始,而沒有其他標記。問題在於一些站點使用ECN標記開始會話,而任何使用ECN連線你的會話都會被那樣的規則拒絕。比較好的規則是:
. . . flags S/SAFR
這個經過實踐是安全的,如果流量進行了整形也沒有必要檢查FIN和RST標記。整形過程會讓PF丟棄帶有非法TCP標記的進入數據包(例如SYN和FIN以及SYN和RST)。強烈推薦總是進行流量整形:
scrub in on fxp0
.
.
.
pass in on fxp0 proto tcp from any to any port ssh flags S/SA \
keep state
TCP SYN 代理
通過,當客戶端向伺服器初始化一個TCP連線時,PF會在二者直接傳遞握手數據包。然而,PF具有這樣的能力,就是代理握手。使用握手代理,PF自己會和客戶端完成握手,初始化和伺服器的握手,然後在二者之間傳遞數據。這樣做的優點是在客戶端完成握手之前,沒有數據包到達伺服器。這樣就消沉了TCP SYN FLOOD欺騙影響伺服器的問題,因為進行欺騙的客戶端不會完成握手。
TCP SYN 代理在規則中使用synproxy state關鍵字打開。例如:
pass in on $ext_if proto tcp from any to $web_server port www \
flags S/SA synproxy state
這樣, web伺服器的連線由PF進行TCP代理。
由於synproxy state工作的方式,它具有keep state 和 modulate state一樣的功能。
如果PF工作在橋模式下,SYN代理不會起作用。
阻塞欺騙數據包
地址欺騙是惡意用戶為了隱藏他們的真實地址或者假冒網路上的其他節點而在他們傳遞的數據包中使用虛假的地址。一旦實施了地址欺騙,他們可以隱蔽真實地址實施網路攻擊或者獲得僅限於某些地址的網路訪問服務。
PF通過antispoof關鍵字提供一些防止地址欺騙的保護。
antispoof [log] [quick] for interface [af]
log
指定匹配的數據包應該被pflogd進行日誌記錄
quick
如果數據包匹配這條規則,則這是最終的規則,不再進行其他規則集的檢查。
interface
激活要進行欺騙保護的網路接口。也可以是接口的列表。
af
激活進行欺騙保護的地址族,inet代表Ipv4,inet6代表Ipv6。
實例:
antispoof for fxp0 inet
當規則集載入時,任何出現了antispoof關鍵字的規則都會擴展成2條規則。假定接口fxp0具有ip地址10.0.0.1和子網掩碼255.255.255.0(或者/24),上面的規則會擴展成:
block in on ! fxp0 inet from 10.0.0.0/24 to any
block in inet from 10.0.0.1 to any
這些規則實現下面的2個目的:
* 阻塞任何不是由fxp0接口進入的10.0.0.0/24網路的流量。由於10.0.0.0/24的網路是在fxp0接口,具有這樣的源網路地址的數據包絕不應該從其他接口上出現。
* 阻塞任何由10.0.0.1即fxp0接口的IP位址的進入流量。主機絕對不會通過外面的接口給自己傳送數據包,因此任何進入的流量源中帶有主機自己的IP位址都可以認為是惡意的!
注意:antispoof規則擴展出來的過濾規則會阻塞loopback接口上傳送到本地地址的數據包。這些數據包應該明確的配置為允許通過。例如:
pass quick on lo0 all
antispoof for fxp0 inet
使用antispoof應該僅限於已經分配了IP位址的網路接口,如果在沒有分配IP位址的網路接口上使用,過濾規則會擴展成:
block drop in on ! fxp0 inet all
block drop in inet all
這樣的規則會存在阻塞所有接口上進入的所有流量的危險。
被動作業系統識別
被動作業系統識別是通過基於遠端主機TCP SYN數據包中某些特徵進行作業系統被動檢測的技術。這些信息可以作為標準在過濾規則中使用。
PF檢測遠端作業系統是通過比較TCP SYN數據包中的特徵和已知的特徵檔案對照來確定的,特徵檔案默認是/etc/pf.os。如果PF起作用,可是使用下面的命令查看當前的特徵列表。
# pfctl -s osfp
在規則集中,特徵可以指定為OS類型,版本,或者子類型/補丁級別。這些條目在上面的pfctl命令中有列表。要在過濾規則中指定特徵,需使用os關鍵字:
pass in on $ext_if any os OpenBSD keep state
block in on $ext_if any os "Windows 2000"
block in on $ext_if any os "Linux 2.4 ts"
block in on $ext_if any os unknown
指定的作業系統類型unknow允許匹配作業系統未知的數據包。
注意以下的內容::
*作業系統識別偶爾會出錯,因為存在欺騙或者修改過的使得看起來象某個作業系統得數據包。
* 某些修改或者打過補丁得作業系統會改變棧得行為,導致它或者和特徵檔案不符,或者符合了另外得作業系統特徵。
* OSFP 僅對TCP SYN數據包起作用,它不會對其他協定或者已經建立得連線起作用。
IP 選項
默認情況下,PF阻塞帶有IP選項得數據包。這可以使得類似nmap得作業系統識別軟體工作困難。如果應用程式需要通過這樣的數據包,例如多播或者IGMP,可以使用allow-opts關鍵字
pass in quick on fxp0 all allow-opts
過濾規則實例
下面是過濾規則得實例。運行PF的機器充當防火牆,在一個小得內部網路和網際網路之間。只列出了過濾規則,queueing, nat, rdr,等等沒有在實例中列出。
ext_if = "fxp0"
int_if = "dc0"
lan_net = "192.168.0.0/24"
# scrub incoming packets
scrub in all
# setup a default deny policy
block in all
block out all
# pass traffic on the loopback interface in either direction
pass quick on lo0 all
# activate spoofing protection for the internal interface.
antispoof quick for $int_if inet
# only allow ssh connections from the local network if it‘s from the
# trusted computer, 192.168.0.15. use "block return" so that a TCP RST is
# sent to close blocked connections right away. use "quick" so that this
# rule is not overridden by the "pass" rules below.
block return in quick on $int_if proto tcp from ! 192.168.0.15 \
to $int_if port ssh flags S/SA
# pass all traffic to and from the local network
pass in on $int_if from $lan_net to any
pass out on $int_if from any to $lan_net
# pass tcp, udp, and icmp out on the external (Internet) interface.
# keep state on udp and icmp and modulate state on tcp.
pass out on $ext_if proto tcp all modulate state flags S/SA
pass out on $ext_if proto { udp, icmp } all keep state
# allow ssh connections in on the external interface as long as they‘re
# NOT destined for the firewall (i.e., they‘re destined for a machine on
# the local network). log the initial packet so that we can later tell
# who is trying to connect. use the tcp syn proxy to proxy the connection.
pass in log on $ext_if proto tcp from any to { !$ext_if, !$int_if } \
port ssh flags S/SA synproxy state
網路地址轉換(NAT)
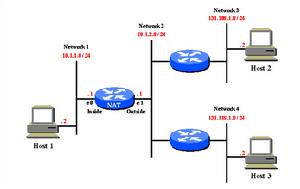 PF防火牆
PF防火牆網路地址轉換是映射整個網路(或者多個網路)到單個IP位址的方法。當ISP分配的IP位址數目少於要連上網際網路的計算機數目時,NAT是必需的。NAT在RFC1631中描述。
NAT允許使用RFC1918中定義的保留地址族。典型情況下,內部網路可以下面的地址族:
10.0.0.0/8 (10.0.0.0 - 10.255.255.255)
172.16.0.0/12 (172.16.0.0 - 172.31.255.255)
192.168.0.0/16 (192.168.0.0 - 192.168.255.255)
擔任NAT任務的作業系統必須至少要2塊網卡,一塊連線到網際網路,另一塊連線內部網路。NAT會轉換內部網路的所有請求,使它們看起來象是來自進行NAT工作的主機系統。
NAT如何工作
當內部網路的一個客戶端連線網際網路上的主機時,它傳送目的是那台主機的IP數據包。這些數據包包含了達到連線目的的所有信息。NAT的作用和這些信息相關。
* 源 IP 地址 (例如, 192.168.1.35)
* 源 TCP 或者 UDP 連線埠 (例如, 2132)
當數據包通過NAT網關時,它們會被修改,使得數據包看起來象是從NAT網關自己發出的。NAT網關會在它的狀態表中記錄這個改變,以便:
a)將返回的數據包反向轉換
b)確保返回的數據包能通過防火牆而不會被阻塞。
例如,會發生下面的改變:
* 源 IP: 被網關的外部地址所替換(例如, 24.5.0.5)
* 源連線埠:被隨機選擇的網關沒有在用的連線埠替換 (例如, 53136)
內部主機和網際網路上的主機都不會意識到發生了這個轉變步驟。對於內部主機,NAT系統僅僅是個網際網路網關,對於網際網路上的主機,數據包看起來直接來自NAT系統,它完全不會意識到內部工作站的存在。
當網際網路網上的主機回應內部主機的數據包時,它會使用NAT網關機器的外部地址和轉換後的連線埠。然後NAT網關會查詢狀態表來確定返回的數據包是否匹配某個已經建立的連線。基於IP位址和連線埠的聯合找到唯一匹配的記錄告訴PF這個返回的數據包屬於內部主機192.168.1.35。然後PF會進行和出去的數據包相反的轉換過程,將返回的數據包傳遞給內部主機。
ICMP數據包的轉換也是類似的,只是不進行源連線埠的修改。
 PF防火牆
PF防火牆注意:轉換後的數據包仍然會通過過濾引擎,根據定義的過濾規則進行阻塞或者通過。唯一的例外是如果nat規則中使用了pass關鍵字,會使得經過nat的數據包直接通過過濾引擎。
還要注意由於轉換是在過濾之前進行,過濾引擎所看到的是上面“nat如何工作”中所說的經過轉換後的ip地址和連線埠的數據包。
IP 轉發
由於NAT經常在路由器和網關上使用,因此IP轉發是需要的,使得數據包可以在UNIX機器的不同網路接口間傳遞。IP轉發可以通過sysctl命令打開:
# sysctl -w net.inet.ip.forwarding=1
# sysctl -w net.inet6.ip6.forwarding=1 (if using IPv6)
要使這個變化永久生效,可以增加如下行到/etc/sysctl.conf檔案中:
net.inet.ip.forwarding=1
net.inet6.ip6.forwarding=1
這些行是本來就存在的,但默認安裝中被#前綴注釋掉了。刪除#,保存檔案,IP轉發在機器重啟後就會發生作用。
配置NAT
一般的NAT規則格式在pf.conf檔案中是這個樣子:
nat [pass] on interface [af] from src_addr [port src_port] to \
dst_addr [port dst_port] -> ext_addr [pool_type] [static-port]
nat
開始NAT規則的關鍵字。
pass
使得轉換後的數據包完全繞過過濾規則。
interface
進行數據包轉換的網路接口。
af
地址類型,inet代表Ipv4,inet6代表Ipv6。PF通常能根據源/目標地址自動確定這個參數。
src_addr
被進行轉換的IP頭中的源(內部)地址。源地址可以指定為:
單個的Ipv4或者Ipv6地址.
CIDR 網路地址.
能夠在規則集載入時通過DNS解析到的合法的域名,IP位址會替代規則中的域名。
網路接口名稱。網路接口上配置的所有ip地址會替代進規則中。
帶有/掩碼(例如/24)的網路接口的名稱。每個根據掩碼確定的CIDR網路地址都會被替代進規則中。.
帶有()的網路接口名稱。這告訴PF如果網路接口的IP位址改變了,就更新規則集。這個對於使用DHCP或者撥號來獲得IP位址的接口特別有用,IP位址改變時不需要重新載入規則集。
帶有如下的修飾詞的網路接口名稱:
o :network - 替代CIDR網路地址段 (例如, 192.168.0.0/24)
o :broadcast - 替代網路廣播地址(例如, 192.168.0.255)
o :peer - 替代點到點鏈路上的ip地址。
另外,:0修飾詞可以附加到接口名稱或者上面的修飾詞後面指示PF在替代時不包括網路接口的其餘附加(alias)地址。這些修飾詞也可以在接口名稱在括弧()內時使用。例如:fxp0:network:0
表.
上面的所有項但使用!(非)修飾詞
使用列表的一系列地址.
關鍵字 any 代表所有地址
關鍵字 all 是 from any to any的縮寫。
src_port
4層數據包頭中的源連線埠。連線埠可以指定為:
1 到 65535之間的整數
/etc/services中的合法服務名稱
使用列表的一系列連線埠
一個範圍:
o != (不等於)
o (大於)
o = (大於等於)
o > (反轉範圍)
最後2個是二元操作符(他們需要2個參數),在範圍內不包括參數。
o : (inclusive range)
inclusive range 也是二元操作符但範圍內包括參數。
Port選項在NAT規則中通常不使用,因為目標通常會NAT所有的流量而不過連線埠是否在使用。
dst_addr
被轉換數據包中的目的地址。目的地址類型和源地址相似。
dst_port
4層數據包頭中的目的目的連線埠,目的連線埠類型和源連線埠類型相似。
ext_addr
NAT網關上數據包被轉換後的外部地址。外部地址可以是:
單個的Ipv4或者Ipv6地址.
CIDR 網路地址.
能夠在規則集載入時通過DNS解析到的合法的域名,IP位址會替代規則中的域名。
網路接口名稱。網路接口上配置的所有ip地址會替代進規則中。
帶有/掩碼(例如/24)的網路接口的名稱。每個根據掩碼確定的CIDR網路地址都會被替代進規則中。.
帶有()的網路接口名稱。這告訴PF如果網路接口的IP位址改變了,就更新規則集。這個對於使用DHCP或者撥號來獲得IP位址的接口特別有用,IP位址改變時不需要重新載入規則集。
帶有如下的修飾詞的網路接口名稱:
o :network - 替代CIDR網路地址段 (例如, 192.168.0.0/24)
o :broadcast - 替代網路廣播地址(例如, 192.168.0.255)
o :peer - 替代點到點鏈路上的ip地址。
另外,:0修飾詞可以附加到接口名稱或者上面的修飾詞後面指示PF在替代時不包括網路接口的其餘附加(alias)地址。這些修飾詞也可以在接口名稱在括弧()內時使用。例如:fxp0:network:0
使用列表的一系列地址.
pool_type
指定轉換後的地址池的類型
static-port
告訴PF不要轉換TCP和UDP數據包中的源連線埠
這條規則最簡單的形式如下:
nat on tl0 from 192.168.1.0/24 to any -> 24.5.0.5
這條規則是說對從tl0網路接口上到來的所有192.168.1.0/24網路的數據包進行NAT,將源地址轉換為24.5.0.5。
儘管上面的規則是正確的,但卻不是推薦的形式。因為維護起來有困難,當內部或者外部網路有變化時都要修改這一行。比較一下下面這條比較容易維護的規則:(tl0時外部,dc0是內部):
nat on tl0 from dc0:network to any -> tl0
優點是相當明顯的,可以任意改變2個接口的IP位址而不用改變這條規則。
象上面這樣在地址轉換中使用接口名稱時,IP位址在pf.conf檔案載入時確定,並不是憑空的。如果使用DHCP還配置外部地址,這會存在問題。如果分配的IP位址改變了,NAT仍然會使用舊的IP位址轉換出去的數據包。這會導致對外的連線停止工作。為解決這個問題,應該給接口名稱加上括弧,告訴PF自動更新轉換地址。
nat on tl0 from dc0:network to any -> (tl0)
這個方法對IPv4 和 IPv6地址都用效。
 PF防火牆
PF防火牆雙向映射可以通過使用binat規則建立。Binat規則建立一個內部地址和外部地址一對一的映射。這會很有用,比如,使用獨立的外部IP位址用內部網路里的機器提供web服務。從網際網路到來連線外部地址的請求被轉換到內部地址,同時由(內部)web伺服器發起的連線(例如DNS查詢)被轉換為外部地址。和NAT規則不過,binat規則中的tcp和udp連線埠不會被修改。
例如:
web_serv_int = "192.168.1.100"
web_serv_ext = "24.5.0.6"
binat on tl0 from $web_serv_int to any -> $web_serv_ext
轉換規則例外設定
使用no關鍵字可以在轉換規則中設定例外。例如,如果上面的轉換規則修改成這樣:
no nat on tl0 from 192.168.1.10 to any
nat on tl0 from 192.168.1.0/24 to any -> 24.2.74.79
則除了192.168.1.10以外,整個192.168.1.0/24網路地址的數據包都會轉換為外部地址24.2.74.79。
注意第一條匹配的規則起了決定作用,如果是匹配有no的規則,數據包不會被轉換。No關鍵字也可以在binat和rdr規則中使用。
檢查 NAT 狀態
要檢查活動的NAT轉換可以使用pfctl帶-s state 選項。這個選項列出所有當前的NAT會話。
# pfctl -s state
fxp0 TCP 192.168.1.35:2132 -> 24.5.0.5:53136 -> 65.42.33.245:22 TIME_WAIT:TIME_WAIT
fxp0 UDP 192.168.1.35:2491 -> 24.5.0.5:60527 -> 24.2.68.33:53 MULTIPLE:SINGLE
解釋 (對第一行):
fxp0
顯示狀態綁定的接口。如果狀態是浮動的,會出現self字樣。
TCP
連線使用的協定。
192.168.1.35:2132
內部網路中機器的IP位址 (192.168.1.35),源連線埠(2132)在地址後顯示,這個也是被替換的IP頭中的地址。 of the machine on the internal network. The
source port (2132) is shown after the address. This is also the address
that is replaced in the IP header.
24.5.0.5:53136
IP 地址 (24.5.0.5) 和連線埠 (53136) 是網關上數據包被轉換後的地址和連線埠。
65.42.33.245:22
IP 地址 (65.42.33.245) 和連線埠 (22) 是內部機器要連線的地址和連線埠。
TIME_WAIT:TIME_WAIT
這表明PF認為的目前這個TCP連線的狀態。
重定向 (連線埠轉發)
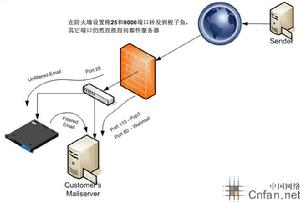 PF防火牆
PF防火牆如果在辦公地點套用了NAT,內部網所有的機器都可以訪問網際網路。但如何讓NAT網關後面的機器能夠被從外部訪問?這就是重定向的來源。重定向允許外來的流量傳送到NAT網關後面的機器。
看個例子:
rdr on tl0 proto tcp from any to any port 80 -> 192.168.1.20
這一行重定向了TCP連線埠80(web伺服器)流量到內部網路地址192.168.1.20。因此,即使192.168.1.20在網關後面的內部網路,外部仍然能夠訪問它。
上面rdr行中from any to any部分非常有用。如果明確知道哪些地址或者子網被允許訪問web伺服器的80連線埠,可以在這部分嚴格限制:
rdr on tl0 proto tcp from 27.146.49.0/24 to any port 80 -> 192.168.1.20
這樣只會重定向指定的子網。注意這表明可以重定向外部不同的訪問主機到網關後面不同的機器上。這非常有用。例如,如果知道遠端的用戶連線上來時使用的IP位址,可以讓他們使用網關的IP位址和連線埠訪問他們各自的桌面計算機。
rdr on tl0 proto tcp from 27.146.49.14 to any port 80 -> \
192.168.1.20
rdr on tl0 proto tcp from 16.114.4.89 to any port 80 -> \
192.168.1.22
rdr on tl0 proto tcp from 24.2.74.178 to any port 80 -> \
192.168.1.23
重定向和包過濾
注意:轉換後的數據包仍然會通過過濾引擎,根據定義的過濾規則進行阻塞或者通過。唯一的例外是如果rdr規則中使用了pass關鍵字,會使得重定向的數據包直接通過過濾引擎。
還要注意由於轉換是在過濾之前進行,過濾引擎所看到的是在匹配rdr規則經過轉換後的目標ip地址和連線埠的數據包。
* 192.0.2.1 - 網際網路上的主機
* 24.65.1.13 - openbsd路由器的外部地址
* 192.168.1.5 - web伺服器的內部IP位址
 PF防火牆
PF防火牆rdr on tl0 proto tcp from 192.0.2.1 to 24.65.1.13 port 80 \
-> 192.168.1.5 port 8000
數據包在經過rdr規則前的模樣:
* 源地址: 192.0.2.1
* 源連線埠: 4028 (由作業系統任意選擇)
* 目的地址: 24.65.1.13
* 目的連線埠: 80
數據包經過rdr規則後的模樣:
* 源地址: 192.0.2.1
* 源連線埠: 4028
* 目的地址: 192.168.1.5
* 目的: 8000
過濾引擎看見的IP數據包時轉換髮生之後的情況。
安全隱患
重定向確實存在安全隱患。在防火牆上開了一個允許流量進入內部網路的洞,被保護的網路安全潛在的受到了威脅!例如,如果流量被轉發到了內部的web伺服器,而web伺服器上允許的守護程式或者CGI腳本程式存在漏洞,則這台伺服器存在會被網際網路網上的入侵者攻擊危險。如果入侵者控制了這台機器,就有了進入內部網路的通道,僅僅是因為這種流量是允許通過防火牆的。
這種風險可以通過將允許外部網路訪問的系統限制在一個單獨的網段中來減小。這個網段通常也被稱為非軍事化區域(DMZ)或者私有服務網路(PSN)。通過這個方法,如果web伺服器被控制,通過嚴格的過濾進出DMZ/PSN的流量,受影響的系統僅限於DMZ/PSN網段。
重定向和反射
通常,重定向規則是用來將網際網路上到來的連線轉發到一個內部網路或者區域網路的私有地址。例如:
server = 192.168.1.40
rdr on $ext_if proto tcp from any to $ext_if port 80 -> $server \
port 80
但是,當一個重定向規則被從區域網路上的客戶端進行測試時,它不會正常工作。這是因為重定向規則僅適用於通過指定連線埠($ext_if,外部接口,在上面的例子中)的數據包。從區域網路上的主機連線防火牆的外部地址,並不意味著數據包會實際的通過外部接口。防火牆上的TCP/IP棧會把到來的數據包的目的地址在通過內部接口時與它自己的IP位址或者別名進行對比檢測。那樣的數據包不會真的通過外部接口,棧在任何情況下也不會建立那樣的通道。因而,PF永遠也不會在外部接口上看到那些數據包,過濾規則由於指定了外部接口也不會起作用。
指定第二條針對內部接口的也達不到預想的效果。當本地的客戶端連線防火牆的外部地址時,初始化的TCP握手數據包是通過內部接口到達防火牆的。重定向規則確實起作用了,目標地址被替換成了內部伺服器,數據包通過內部接口轉發到了內部的伺服器。但源地址沒有進行轉換,仍然包含的是本地客戶端的IP位址,因此伺服器把它的回應直接傳送給了客戶端。防火牆永遠收不到應答不可能返回客戶端信息,客戶端收到的應答不是來自它期望的源(防火牆)會被丟棄,TCP握手失敗,不能建立連線。
當然,區域網路里的客戶端仍然會希望象外部客戶一樣透明的訪問這台內部伺服器。有如下的方法解決這個問題:
水平分割 DNS
存在這樣的可能性,即配置DNS伺服器使得它回答內部主機的查詢和回答外部主機的查詢不一樣,因此內部客戶端在進行名稱解析時會收到內部伺服器的地址。它們直接連線到內部伺服器,防火牆根本不牽扯。這會降低本地流量,因為數據包不會被送到防火牆。
將伺服器移到獨立的本地網路
增加單獨的網路接口卡到防火牆,把本地的伺服器從和客戶端同一個網段移動到專用的網段(DMZ)可以讓本地客戶端按照外部重定向連線的方法一樣重定向。使用單獨的網段有幾個優點,包括和保留的內部主機隔離增加了安全性;伺服器(我們的案例中可以從網際網路訪問)一旦被控制,它不能直接存取本地網路因為所有的連線都必須通過防火牆。
TCP 代理
一般而言,TCP代理可以在防火牆上設定,監聽要轉發的連線埠或者將內部接口上到來的連線重定向到它監聽的連線埠。當本地客戶端連線防火牆時,代理接受連線,建立到內部伺服器的第二條連線,在通信雙方間進行數據轉發。
簡單的代理可以使用inetd和nc建立。下面的/etc/inetd.conf中的條目建立一個監聽套接字綁定到lookback地址(127.0.0.1)和連線埠5000。連線被轉發到伺服器192.168.1.10的80連線埠。
127.0.0.1:5000 stream tcp nowait nobody /usr/bin/nc nc -w \
20 192.168.1.10 80
下面的重定向規則轉發內部接口的80連線埠到代理:
rdr on $int_if proto tcp from $int_net to $ext_if port 80 -> \
127.0.0.1 port 5000
RDR 和 NAT 結合
通過對內部接口增加NAT規則,上面說的轉換後源地址不變的問題可以解決。
rdr on $int_if proto tcp from $int_net to $ext_if port 80 -> \
$server
no nat on $int_if proto tcp from $int_if to $int_net
nat on $int_if proto tcp from $int_net to $server port 80 -> \
$int_if
這會導致由客戶端發起的初始化連線在收到內部接口的返回數據包時轉換回來,客戶端的源ip地址被防火牆的內部接口地址代替。內部伺服器會回應防火牆的內部接口地址,在轉發給本地客戶端時可以反轉NAT和RDR。這個結構是非常複雜的,因為它為每個反射連線產生了2個單獨的狀態。必須小心配置防止NAT規則套用到了其他流量,例如連線由外部發起(通過其他的重定向)或者防火牆自己。注意上面的rdr規則會導致TCP/IP棧看到來自內部接口帶有目的地址是內部網路的數據包。
規則生成捷徑
簡介
PF提供了許多方法來進行規則集的簡化。一些好的例子是使用宏和列表。另外,規則集的語言或者語法也提供了一些使規則集簡化的捷徑。首要的規則是,規則集越簡單,就越容易理解和維護。
使用宏
宏是非常有用的,因為它提供了硬編碼地址,連線埠號,接口名稱等的可選替代。在一個規則集中,伺服器的IP位址改變了?沒問題,僅僅更新一下宏,不需要弄亂花費了大量時間和精力建立的規則集。
通常的慣例是在PF規則集中定義每個網路接口的宏。如果網卡需要被使用不同驅動的卡取代,例如,用intel代替3com,可以更新宏,過濾規則集會和以前功能一樣。另一個優點是,如果在多台機器上安裝同樣的規則集,某些機器會有不同的網卡,使用宏定義網卡可以使的安裝的規則集進行最少的修改。使用宏來定義規則集中經常改變的信息,例如連線埠號,IP位址,接口名稱等等,建議多多實踐!
# define macros for each network interface
IntIF = "dc0"
ExtIF = "fxp0"
DmzIF = "fxp1"
另一個慣例是使用宏來定義IP位址和網路,這可以大大減輕在IP位址改變時對規則集的維護。
# define our networks
IntNet = "192.168.0.0/24"
ExtAdd = "24.65.13.4"
DmzNet = "10.0.0.0/24"
如果內部地址擴展了或者改到了一個不同的IP段,可以更新宏為:
IntNet = "{ 192.168.0.0/24, 192.168.1.0/24 }"
當這個規則集重新載入時,任何東西都跟以前一樣。
使用列表
來看一下一個規則集中比較好的例子使得RFC1918定義的內部地址不會傳送到網際網路上,如果發生傳送的事情,可能導致問題。
block in quick on tl0 inet from 127.0.0.0/8 to any
block in quick on tl0 inet from 192.168.0.0/16 to any
block in quick on tl0 inet from 172.16.0.0/12 to any
block in quick on tl0 inet from 10.0.0.0/8 to any
block out quick on tl0 inet from any to 127.0.0.0/8
block out quick on tl0 inet from any to 192.168.0.0/16
block out quick on tl0 inet from any to 172.16.0.0/12
block out quick on tl0 inet from any to 10.0.0.0/8
看看下面更簡單的例子:
block in quick on tl0 inet from { 127.0.0.0/8, 192.168.0.0/16, \
172.16.0.0/12, 10.0.0.0/8 } to any
block out quick on tl0 inet from any to { 127.0.0.0/8, \
192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }
這個規則集從8行減少到2行。如果聯合使用宏,還會變得更好:
NoRouteIPs = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
10.0.0.0/8 }"
ExtIF = "tl0"
block in quick on $ExtIF from $NoRouteIPs to any
block out quick on $ExtIF from any to $NoRouteIPs
注意雖然宏和列表簡化了pf.conf檔案,但是實際是這些行會被pfctl(8)擴展成多行,因此,上面的例子實際擴展成下面的規則:
block in quick on tl0 inet from 127.0.0.0/8 to any
block in quick on tl0 inet from 192.168.0.0/16 to any
block in quick on tl0 inet from 172.16.0.0/12 to any
block in quick on tl0 inet from 10.0.0.0/8 to any
block out quick on tl0 inet from any to 10.0.0.0/8
block out quick on tl0 inet from any to 172.16.0.0/12
block out quick on tl0 inet from any to 192.168.0.0/16
block out quick on tl0 inet from any to 127.0.0.0/8
可以看到,PF擴展僅僅是簡化了編寫和維護pf.conf檔案,實際並不簡化pf(4)對於規則的處理過程。
宏不僅僅用來定義地址和連線埠,它們在PF的規則檔案中到處都可以用:
pre = "pass in quick on ep0 inet proto tcp from "
post = "to any port { 80, 6667 } keep state"
# David‘s classroom
$pre 21.14.24.80 $post
# Nick‘s home
$pre 24.2.74.79 $post
$pre 24.2.74.178 $post
擴展後:
pass in quick on ep0 inet proto tcp from 21.14.24.80 to any \
port = 80 keep state
pass in quick on ep0 inet proto tcp from 21.14.24.80 to any \
port = 6667 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.79 to any \
port = 80 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.79 to any \
port = 6667 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.178 to any \
port = 80 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.178 to any \
port = 6667 keep state
PF 語法
PF的語法相當靈活,因此,允許編寫非常靈活的規則集。PF能夠自動插入某些關鍵字因此它們不必在規則中明確寫出,關鍵字的順序也是隨意的,因此不需要記憶嚴格的語法限制。
減少關鍵字
要定義全部拒絕的策略,使用下面2條規則:
block in all
block out all
這可以簡化為:
block all
如果沒有指定方向,PF會認為規則適用於數據包傳遞的進、出2個方向。
同樣的, "from any to any" 和 "all" 子句可以在規則中省略,例如
block in on rl0 all
pass in quick log on rl0 proto tcp from any to any port 22 keep state
可以簡化為:
block in on rl0
pass in quick log on rl0 proto tcp to port 22 keep state
第一條規則阻塞rl0上從任意到任意的進入數據包,第二條規則允許rl0上連線埠22的TCP流量通過。
Return 簡化
用於阻塞數據包,回應TCP RST或者ICMP不可到達的規則集可以這么寫:
block in all
block return-rst in proto tcp all
block return-icmp in proto udp all
block out all
block return-rst out proto tcp all
block return-icmp out proto udp all
可以簡化為::
block return
當PF看到return關鍵字,PF可以智慧型回複合適應答,或者完全不回復,取決於要阻塞的數據包使用的協定。W
關鍵字順序
在大多數情況下,關鍵字的順序是非常靈活的。例如,規則可以這么寫:
pass in log quick on rl0 proto tcp to port 22 \
flags S/SA keep state queue ssh label ssh
也可以這么寫:
pass in quick log on rl0 proto tcp to port 22 \
queue ssh keep state label ssh flags S/SA
其他類似的順序也能夠正常工作。
高級配置
運行選項
運行選項是控制pf操作的選擇。這些選項在pf.conf中使用set指定。
set block-policy
設定過濾規則中指定的block動作的默認行為。
drop - 數據包悄然丟棄.
return - TCP RST 數據包返回給遭阻塞的TCP數據包,ICMP不可到達數據包返回給其他。
注意單獨的過濾規則可以重寫默認的回響。
set debug
設定pf的調試級別。
none - 不顯示任何調試信息。
urgent - 為嚴重錯誤產生調試信息,這是默認選擇。
misc - 為多種錯誤產生調試信息。(例如,收到標準化/整形的數據包的狀態,和產生失敗的狀態)。.
loud - 為普通條件產生調試信息(例如,收到被動作業系統檢測信息狀態)。
set fingerprints file
設定應該裝入的進行作業系統識別的作業系統特徵檔案來,默認是 /etc/pf.os.
set limit
frags - 在記憶體池中進行數據包重組的最大數目。默認是5000。
src-nodes - 在記憶體池中用於追蹤源地址(由stick-address 和 source-track選項產生)的最大數目,默認是10000。
states - 在記憶體池中用於狀態表(過濾規則中的keep state)的最大數目,默認是10000。
set loginterface int
設定PF要統計進/出流量和放行/阻塞的數據包的數目的接口卡。統計數目一次只能用於一張卡。注意 match, bad-offset, 等計數器和狀態表計數器不管 loginterface是否設定都會被記錄。
set optimization
為以下的網路環境最佳化PF:
normal - 適用於絕大多數網路,這是默認項。
high-latency - 高延時網路,例如衛星連線。
aggressive - 自狀態表中主動終止連線。這可以大大減少繁忙防火牆的記憶體需求,但要冒空閒連線被過早斷開的風險。
conservative - 特別保守的設定。這可以避免在記憶體需求過大時斷開空閒連線,會稍微增加CPU的利用率。
set state-policy
設定 PF在狀態保持時的行為。這種行為可以被單條規則所改變。見狀態保持章節。
if-bound - 狀態綁定到產生它們的接口。如果流量匹配狀態表種條目但不是由條目中記錄的接口通過,這個匹配會失敗。數據包要么匹配一條過濾規則,或者被丟棄/拒絕。
group-bound - 行為基本和if-bound相同,除了數據包允許由同一組接口通過,例如所有的ppp接口等。
floating - 狀態可以匹配任何接口上的流量。只要數據包匹配狀態表條目,不管是否匹配它通過的接口,都會放行。這是默認的規則。
set timeout
interval - 丟棄過期的狀態和數據包碎片的秒數。
frag - 不能重組的碎片過期的秒數。
例如:
set timeout interval 10
set timeout frag 30
set limit { frags 5000, states 2500 }
set optimization high-latency
set block-policy return
set loginterface dc0
set fingerprints /etc/pf.os.test
set state-policy if-bound
流量整形
簡介
流量整形是將數據包標準化避免最終的數據包出現非法的目的。流量整形指引同時也會重組數據包碎片,保護某些作業系統免受某些攻擊,丟棄某些帶有非法聯合標記的TCP數據包。流量整形指引的簡單形式是:
scrub in all
這會對所有接口上到來的數據包進行流量整形。
一個不在接口上進行流量整形的原因是要透過PF使用NFS。一些非openbsd的平台傳送(和等待)奇怪的數據包,對設定不分片位的數據包進行分片。這會被流量整形(正確的)拒絕。這個問題可以通過設定no-df選項解決。另一個原因是某些多用戶的遊戲在進行流量整形通過PF時存在連線問題。除了這些極其罕見的案例,對所有的數據包進行流量整形時強烈推薦的設定。
流量整形指引語法相對過濾語法是非常簡單的,它可以非常容易的選擇特定的數據包進行整形而不對沒指定的數據包起作用。
選項
流量整形有下面的選項:
no-df
在IP數據包頭中清除不分片位的設定。某些作業系統已知產生設定不分片位的分片數據包。尤其是對於NFS。流量整形(scrub)會丟棄這類數據包除非設定了no-df選項。某些作業系統產生帶有不分片位和用0填寫IP包頭中分類域,推薦使用no-df和random-id 聯合使用解決。
random-id
用隨機值替換某些作業系統輸出數據包中使用的可預測IP分類域的值這個選項僅適用於在選擇的數據包重組後不進行分片的輸入數據包。
min-ttl num
增加IP包頭中的最小存活時間(TTL)。
max-mss num
增加在TCP數據包頭中最大分段值(MSS)。
fragment reassemble
在傳遞數據包到過濾引擎前緩衝收到的數據包碎片,重組它們成完整的數據包。優點是過濾規則僅處理完整的數據包,忽略碎片。缺點是需要記憶體緩衝數據包碎片。這是沒有設定分片選項時的默認行為。這也是能和NAT一起工作的唯一分片選項。
fragment crop
導致重複的碎片被丟棄,重疊的被裁剪。與碎片重組不同,碎片不會被緩衝,而是一到達就直接傳遞。
fragment drop-ovl
跟 fragment crop 相似,除了所有重複和重疊的碎片和其他更多的通信碎片一樣被丟棄。
reassemble tcp
TCP連線狀態標準化。當使用了 scrub reassemble tcp時,方向(進/出)不用說明,會執行下面的標準化過程:
連線雙方都不允許減少它們的IP TTL值。這樣做是為了防止攻擊者傳送數據包到防火牆,影響防火牆保持的連線狀態,使數據包在到達目的主機前就過期。所有數據包的TTL都為了這個連線加到了最大值。
用隨機數字調整TCP數據包頭中的 RFC1323 時間戳。這可以阻止竊聽者推斷主機線上的時間和猜測NAT網關後面有多少主機。
實例:
scrub in on fxp0 all fragment reassemble min-ttl 15 max-mss 1400
scrub in on fxp0 all no-df
scrub on fxp0 all reassemble tcp
錨定和命名規則集
簡介
除了主要的規則集,PF還可以載入子規則
該網路的佇列策略:
* 為Bob保留玩線上遊戲的80Kbps下行頻寬,以減少另外兩人對他的影響,並且總頻寬富餘的情況下可以超出該限制。
* 互動的SSH和即時信息流量要有高於其他流量的優先權。
* DNS請求和反饋數據流要有第二高的優先權。
* 流出的TCP ACK 數據包的優先權要高於其他流出數據包的優先權。
下面是對應的策略(省略了其他部分策略,如rdr、nat等):
# enable queueing on the external interface to control traffic going to
# the Internet. use the priq scheduler to control only priorities. set
# the bandwidth to 610Kbps to get the best performance out of the TCP
# ACK queue.
altq on fxp0 priq bandwidth 610Kb queue { std_out, ssh_im_out, dns_out, \
tcp_ack_out }
# define the parameters for the child queues.
# std_out - the standard queue. any filter rule below that does not
# explicitly specify a queue will have its traffic added
# to this queue.
# ssh_im_out - interactive SSH and various instant message traffic.
# dns_out - DNS queries.
# tcp_ack_out - TCP ACK packets with no data payload.
queue std_out priq(default)
queue ssh_im_out priority 4 priq(red)
queue dns_out priority 5
queue tcp_ack_out priority 6
# enable queueing on the internal interface to control traffic coming in
# from the Internet. use the cbq scheduler to control bandwidth. max
# bandwidth is 2Mbps.
altq on dc0 cbq bandwidth 2Mb queue { std_in, ssh_im_in, dns_in, bob_in }
# define the parameters for the child queues.
# std_in - the standard queue. any filter rule below that does not
# explicitly specify a queue will have its traffic added
# to this queue.
# ssh_im_in - interactive SSH and various instant message traffic.
# dns_in - DNS replies.
# bob_in - bandwidth reserved for Bob‘s workstation. allow him to
# borrow.
queue std_in cbq(default)
queue ssh_im_in priority 4
queue dns_in priority 5
queue bob_in bandwidth 80Kb cbq(borrow)
# ... in the filtering section of pf.conf ...
alice = "192.168.0.2"
bob = "192.168.0.3"
charlie = "192.168.0.4"
local_net = "192.168.0.0/24"
ssh_ports = "{ 22 2022 }"
im_ports = "{ 1863 5190 5222 }"
# filter rules for fxp0 inbound
block in on fxp0 all
# filter rules for fxp0 outbound
block out on fxp0 all
pass out on fxp0 inet proto tcp from (fxp0) to any flags S/SA \
keep state queue(std_out, tcp_ack_out)
pass out on fxp0 inet proto { udp icmp } from (fxp0) to any keep state
pass out on fxp0 inet proto { tcp udp } from (fxp0) to any port domain \
keep state queue dns_out
pass out on fxp0 inet proto tcp from (fxp0) to any port $ssh_ports \
flags S/SA keep state queue(std_out, ssh_im_out)
pass out on fxp0 inet proto tcp from (fxp0) to any port $im_ports \
flags S/SA keep state queue(ssh_im_out, tcp_ack_out)
# filter rules for dc0 inbound
block in on dc0 all
pass in on dc0 from $local_net
# filter rules for dc0 outbound
block out on dc0 all
pass out on dc0 from any to $local_net
pass out on dc0 proto { tcp udp } from any port domain to $local_net \
queue dns_in
pass out on dc0 proto tcp from any port $ssh_ports to $local_net \
queue(std_in, ssh_im_in)
pass out on dc0 proto tcp from any port $im_ports to $local_net \
queue ssh_im_in
pass out on dc0 from any to $bob queue bob_in
實例 #2: 公司網路
( IT Dept ) [ Boss‘s PC ]
| | T1
-- ---- ----- ---------- dc0 [ OpenBSD ] fxp0 -------- ( Internet )
| fxp1
[ COMP1 ] [ WWW ] /
| /
-- ----------‘
這個例子中OpenBSD作為公司網路的防火牆,公司內部在DMZ區運行了WWW伺服器,用戶通過FTP上傳他們的網站。IT部門有自己的子網,老闆的電腦主要用來收發電子郵件和網頁衝浪。防火牆通過1.5Mbps雙向頻寬的T1電路連線網際網路,其他網段均使用快速乙太網(100Mbps)。
實現上述要求的策略如下:
* 限制WWW伺服器到網際網路之間的雙向流量――500Kbps。
* WWW伺服器和內部網路之間沒有流量限制。
* 賦予WWW伺服器和網際網路間的流量高於其他流量的優先權(例如FTP上傳流量)。
* 為IT部門保留500Kbps的頻寬使他們可以下載到最新的軟體,同時如果總頻寬富餘,他們可以借用。
* 為老闆訪問網際網路的流量賦予比其他訪問網際網路流量高的優先權。
下面是對應的策略(省略了其他部分策略,如rdr、nat等):
# enable queueing on the external interface to queue packets going out
# to the Internet. use the cbq scheduler so that the bandwidth use of
# each queue can be controlled. the max outgoing bandwidth is 1.5Mbps.
altq on fxp0 cbq bandwidth 1.5Mb queue { std_ext, www_ext, boss_ext }
# define the parameters for the child queues.
# std_ext - the standard queue. also the default queue for
# outgoing traffic on fxp0.
# www_ext - container queue for WWW server queues. limit to
# 500Kbps.
# www_ext_http - http traffic from the WWW server
# www_ext_misc - all non-http traffic from the WWW server
# boss_ext - traffic coming from the boss‘s computer
queue std_ext cbq(default)
queue www_ext bandwidth 500Kb { www_ext_http, www_ext_misc }
queue www_ext_http priority 3 cbq(red)
queue www_ext_misc priority 1
queue boss_ext priority 3
# enable queueing on the internal interface to control traffic coming
# from the Internet or the DMZ. use the cbq scheduler to control the
# bandwidth of each queue. bandwidth on this interface is set to the
# maximum. traffic coming from the DMZ will be able to use all of this
# bandwidth while traffic coming from the Internet will be limited to
# 1.0Mbps (because 0.5Mbps (500Kbps) is being allocated to fxp1).
altq on dc0 cbq bandwidth 100% queue { net_int, www_int }
# define the parameters for the child queues.
# net_int - container queue for traffic from the Internet. bandwidth
# is 1.0Mbps.
# std_int - the standard queue. also the default queue for outgoing
# traffic on dc0.
# it_int - traffic to the IT Dept network.
# boss_int - traffic to the boss‘s PC.
# www_int - traffic from the WWW server in the DMZ.
queue net_int bandwidth 1.0Mb { std_int, it_int, boss_int }
queue std_int cbq(default)
queue it_int bandwidth 500Kb cbq(borrow)
queue boss_int priority 3
queue www_int cbq(red)
# enable queueing on the DMZ interface to control traffic destined for
# the WWW server. cbq will be used on this interface since detailed
# control of bandwidth is necessary. bandwidth on this interface is set
# to the maximum. traffic from the internal network will be able to use
# all of this bandwidth while traffic from the Internet will be limited
# to 500Kbps.
altq on fxp1 cbq bandwidth 100% queue { internal_dmz, net_dmz }
# define the parameters for the child queues.
# internal_dmz - traffic from the internal network.
# net_dmz - container queue for traffic from the Internet.
# net_dmz_http - http traffic.
# net_dmz_misc - all non-http traffic. this is also the default queue.
queue internal_dmz # no special settings needed
queue net_dmz bandwidth 500Kb { net_dmz_http, net_dmz_misc }
queue net_dmz_http priority 3 cbq(red)
queue net_dmz_misc priority 1 cbq(default)
# ... in the filtering section of pf.conf ...
main_net = "192.168.0.0/24"
it_net = "192.168.1.0/24"
int_nets = "{ 192.168.0.0/24, 192.168.1.0/24 }"
dmz_net = "10.0.0.0/24"
boss = "192.168.0.200"
wwwserv = "10.0.0.100"
# default deny
block on { fxp0, fxp1, dc0 } all
# filter rules for fxp0 inbound
pass in on fxp0 proto tcp from any to $wwwserv port { 21, \
> 49151 } flags S/SA keep state queue www_ext_misc
pass in on fxp0 proto tcp from any to $wwwserv port 80 \
flags S/SA keep state queue www_ext_http
# filter rules for fxp0 outbound
pass out on fxp0 from $int_nets to any keep state
pass out on fxp0 from $boss to any keep state queue boss_ext
# filter rules for dc0 inbound
pass in on dc0 from $int_nets to any keep state
pass in on dc0 from $it_net to any queue it_int
pass in on dc0 from $boss to any queue boss_int
pass in on dc0 proto tcp from $int_nets to $wwwserv port { 21, 80, \
> 49151 } flags S/SA keep state queue www_int
# filter rules for dc0 outbound
pass out on dc0 from dc0 to $int_nets
# filter rules for fxp1 inbound
pass in on fxp1 proto { tcp, udp } from $wwwserv to any port 53 \
keep state
# filter rules for fxp1 outbound
pass out on fxp1 proto tcp from any to $wwwserv port { 21, \
> 49151 } flags S/SA keep state queue net_dmz_misc
pass out on fxp1 proto tcp from any to $wwwserv port 80 \
flags S/SA keep state queue net_dmz_http
pass out on fxp1 proto tcp from $int_nets to $wwwserv port { 80, \
21, > 49151 } flags S/SA keep state queue internal_dmz
地址池和負載均衡
簡介
地址池是提供2個以上的地址供一組用戶共享的。地址池可以是rdr規則中的重定向地址;可以是nat規則中的轉換地址;也可以是route-to, reply-to, 和 dup-to filter選項中的目的地址。
有4種使用地址池的方法:
* bitmask - 截取被修改地址(nat規則的源地址;rdr規則的目標地址)的最後部分和地址池地址的網路部分組合。例如:如果地址池是192.0.2.1/24,而被修改地址是10.0.0.50,則結果地址是192.0.2.50。如果地址池是192.0.2.1/25,而被修改地址是10.0.0.130,這結果地址是192.0.2.2。
* random - 從地址池中隨機選擇地址.
* source-hash - 使用源地址 hash 來確定使用地址池中的哪個地址。這個方法保證給定的源地址總是被映射到同一個地址池。Hash算法的種子可以在source-hash關鍵字後通過16進制字元或者字元串來指定。默認情況下,pfctl(8)在規則集裝入時會隨機產生種子。
* round-robin - 在地址池中按順序循環,這是默認方法,也是表中定義的地址池唯一的方法。
除了round-robin方法,地址池的地址必須表達成CIDR(classless Inter-Domain Routing )的網路地址族。round-robin 方法可以接受多個使用列表和表的單獨地址。
sticky-address 選項可以在 random 和round-robin 池類型中使用,保證特定的源地址始終映射到同樣的重定向地址。
NAT 地址池
地址池在NAT規則中可以被用做轉換地址。連線的源地址會被轉換成使用指定的方法從地址池中選擇的地址。這對於PF負載一個非常大的網路的NAT會非常有用。由於經過NAT的連線對每個地址是有限的,增加附加的轉換地址允許NAT網關增大服務的用戶數量。
在這個例子中,2個地址被用來做輸出數據包的轉換地址。對於每一個輸出的連線,PF按照順序循環使用地址。
nat on $ext_if inet from any to any -> { 192.0.2.5, 192.0.2.10 }
這個方法的一個缺點是成功建立連線的同一個內部地址不會總是轉換為同一個外部地址。這會導致衝突,例如:瀏覽根據用戶的ip地址跟蹤登錄的用戶的web站點。一個可選擇的替代方法是使用source-hash 方法,以便每一個內部地址總是被轉換為同樣的外部地址。,要實現這個方法,地址池必須是CIDR網路地址。
nat on $ext_if inet from any to any -> 192.0.2.4/31 source-hash
這條NAT規則使用地址池192.0.2.4/31 (192.0.2.4 - 192.0.2.5)做為輸出數據包的轉換地址。每一個內部地址會被轉換為同樣的外部地址,由於source-hash關鍵字的緣故。
外來連線負載均衡
地址池也可以用來進行外來連線負載均衡。例如,外來的web伺服器連線可以分配到伺服器群。
web_servers = "{ 10.0.0.10, 10.0.0.11, 10.0.0.13 }"
rdr on $ext_if proto tcp from any to any port 80 -> $web_servers \
round-robin sticky-address
成功的連線將按照順序重定向到web伺服器,從同一個源到來的連線傳送到同一個伺服器。這個sticky connection會和指向這個連線的狀態一起存在。如果狀態過期,sticky
connection也過期。那個主機的更多連線被重定向到按順序的下一個web伺服器。
輸出流量負載均衡
地址池可以和route-to過濾選項聯合使用,在多路徑路由協定(例如BGP4)不可用是負載均衡2個或者多個網際網路連線。通過對round-robin地址池使用route-to,輸出連線可以平均分配到多個輸出路徑。
需要收集的附加的信息是鄰近的網際網路路由器IP位址。這要加入到route-to選項後來控制輸入數據包的目的地址。
下面的例子通過2條到網際網路的連線平衡輸出流量:
lan_net = "192.168.0.0/24"
int_if = "dc0"
ext_if1 = "fxp0"
ext_if2 = "fxp1"
ext_gw1 = "68.146.224.1"
ext_gw2 = "142.59.76.1"
pass in on $int_if route-to \
{ ($ext_if1 $ext_gw1), ($ext_if2 $ext_gw2) } round-robin \
from $lan_net to any keep state
route-to 選項用來在收到流量的內部接口上指定平衡的流量經過各自的網關到輸出的網路接口。注意route-to 選項必須在每個需要均衡的過濾規則上出現。返回的數據包會路由到它們出去時的外部接口(這是由ISP做的),然後正常路由回內部網路。
要保證帶有屬於$ext_if1源地址的數據包總是路由到$ext_gw1($ext_if2 和 $ext_gw2也是同樣的),下面2行必須包括在規則集中:
pass out on $ext_if1 route-to ($ext_if2 $ext_gw2) from $ext_if2 \
to any
pass out on $ext_if2 route-to ($ext_if1 $ext_gw1) from $ext_if1 \
to any
最後,NAT也可以使用在輸出接口中:
nat on $ext_if1 from $lan_net to any -> ($ext_if1)
nat on $ext_if2 from $lan_net to any -> ($ext_if2)
一個完整的輸出負載均衡的例子應該是這個樣子:
lan_net = "192.168.0.0/24"
int_if = "dc0"
ext_if1 = "fxp0"
ext_if2 = "fxp1"
ext_gw1 = "68.146.224.1"
ext_gw2 = "142.59.76.1"
# nat outgoing connections on each internet interface
nat on $ext_if1 from $lan_net to any -> ($ext_if1)
nat on $ext_if2 from $lan_net to any -> ($ext_if2)
# default deny
block in from any to any
block out from any to any
# pass all outgoing packets on internal interface
pass out on $int_if from any to $lan_net
# pass in quick any packets destined for the gateway itself
pass in quick on $int_if from $lan_net to $int_if
# load balance outgoing tcp traffic from internal network.
pass in on $int_if route-to \
{ ($ext_if1 $ext_gw1), ($ext_if2 $ext_gw2) } round-robin \
proto tcp from $lan_net to any flags S/SA modulate state
# load balance outgoing udp and icmp traffic from internal network
pass in on $int_if route-to \
{ ($ext_if1 $ext_gw1), ($ext_if2 $ext_gw2) } round-robin \
proto { udp, icmp } from $lan_net to any keep state
# general "pass out" rules for external interfaces
pass out on $ext_if1 proto tcp from any to any flags S/SA modulate state
pass out on $ext_if1 proto { udp, icmp } from any to any keep state
pass out on $ext_if2 proto tcp from any to any flags S/SA modulate state
pass out on $ext_if2 proto { udp, icmp } from any to any keep state
# route packets from any IPs on $ext_if1 to $ext_gw1 and the same for
# $ext_if2 and $ext_gw2
pass out on $ext_if1 route-to ($ext_if2 $ext_gw2) from $ext_if2 to any
pass out on $ext_if2 route-to ($ext_if1 $ext_gw1) from $ext_if1 to any
數據包標記
簡介
數據包標記是給數據包打內部標記的方法,以後可以在過濾和轉換規則中使用。使用標記,有可能做這樣的事情,比如在接口間產生信任關係,或者確定數據包是否已經經過了轉換規則處理。也可能從基於規則的過濾中移出,開始執行基於策略的過濾。
給數據包打標記
要給數據包打標記,使用tag 關鍵字:
pass in on $int_if all tag INTERNAL_NET keep state
標記 INTERNAL_NET 會增加到任何匹配上述規則的數據包中。
注意keep state的使用; keep state (或者 modulate state/synproxy state) 在標記數據包通過的規則中使用。
標記也可以通過宏來打,比如:
name = "INTERNAL_NET"
pass in on $int_if all tag $name keep state
有一組預先定義的宏也可以被使用。
* $if - 接口
* $srcaddr - 源 IP 地址
* $dstaddr - 目的 IP 地址
* $srcport - 源連線埠
* $dstport - 目的連線埠
* $proto - 協定
* $nr - 規則號
這些宏在規則集裝入時擴展,而不是運行時。
標記遵循以下規則:
* 標記是粘性的。一旦一個標記被匹配的規則打到一個數據包,就不能被刪除。但它可以被不同的標記替換。
* 由於標記的粘性,打了標記的數據包會一直保持,即使所有的規則都沒有使用這個標記。
* 一個數據包一次最多只能打一個標記。
* 標記是內部標識符,標記不會被送到網上。
看看下面的例子:
(1) pass in on $int_if tag INT_NET keep state
(2) pass in quick on $int_if proto tcp to port 80 tag \
INT_NET_HTTP keep state
(3) pass in quick on $int_if from 192.168.1.5 keep state
* 按照規則1,$int_if 接口上收到的數據包會打上INT_NET 標記。
* $int_if 接口上收到的目標連線埠80的數據包根據規則1首先打上INT_NET 標記,然後根據規則2,被INT_NET_HTTP 標記替代。
* $int_if 接口上收到的來自192.168.1.5的數據包根據規則3會方向,由於這是最終匹配規則,因此如果它們的目標連線埠是80,則標記是INT_NET_HTTP ,否則標記是INT_NET 。
標記除了適用於過濾規則以外, nat, rdr, binat轉換規則也可以用tag關鍵字使用標記。
檢查數據包標記
要檢查先前已經打的標記,可以使用tagged關鍵字:
pass out on $ext_if tagged INT_NET keep state
在$ext_if輸出的數據包為了匹配上述規則必須打上INT_NET標記。反轉匹配也可以使用!操作:
pass out on $ext_if tagged ! WIFI_NET keep state
策略過濾
過濾策略提供了編寫過濾規則集的不同方法。定義的策略設定規則,說明哪種流量放行,哪種流量阻塞。數據包被基於傳統的標準如源/目的IP位址,協定等等分配到不同的策略。例如,檢查下面的防火牆策略:
* 自內部LAN到DMZ的流量是允許的 (LAN_DMZ)。
* 自網際網路到DMZ的伺服器流量是允許的。 (INET_DMZ)
* 自網際網路被重定向到spamd(8)是允許的 (SPAMD)
* 其他所有流量阻塞。
注意策略是如何覆蓋所有通過防火牆的流量的。括弧裡面的項目指示這個策略項目將使用的標記。
需要過濾和轉換規則來把數據包分配到不同的策略。
rdr on $ext_if proto tcp from to port smtp \
tag SPAMD -> 127.0.0.1 port 8025
block all
pass in on $int_if from $int_net tag LAN_INET keep state
pass in on $int_if from $int_net to $dmz_net tag LAN_DMZ keep state
pass in on $ext_if proto tcp to $www_server port 80 tag INET_DMZ keep
state
現在要設定定義策略的規則。
pass in quick on $ext_if tagged SPAMD keep state
pass out quick on $ext_if tagged LAN_INET keep state
pass out quick on $dmz_if tagged LAN_DMZ keep state
pass out quick on $dmz_if tagged INET_DMZ keep state
現在要建立整個規則集,修改分類規則。例如,如果pop3/SMTP伺服器增加到了DMZ區,就需要增加針對POP3和SMTP流量的分類,如下:
mail_server = "192.168.0.10"
...
pass in on $ext_if proto tcp to $mail_server port { smtp, pop3 } \
tag INET_DMZ keep state
Email 流量會作為INET-DMZ策略的條目被放行。t
完整的規則:
# macros
int_if = "dc0"
dmz_if = "dc1"
ext_if = "ep0"
int_net = "10.0.0.0/24"
dmz_net = "192.168.0.0/24"
www_server = "192.168.0.5"
mail_server = "192.168.0.10"
table persist file "/etc/spammers"
# classification -- classify packets based on the defined firewall
# policy.
rdr on $ext_if proto tcp from to port smtp \
tag SPAMD -> 127.0.0.1 port 8025
block all
pass in on $int_if from $int_net tag LAN_INET keep state
pass in on $int_if from $int_net to $dmz_net tag LAN_DMZ keep state
pass in on $ext_if proto tcp to $www_server port 80 tag INET_DMZ keep state
pass in on $ext_if proto tcp to $mail_server port { smtp, pop3 } \
tag INET_DMZ keep state
# policy enforcement -- pass/block based on the defined firewall policy.
pass in quick on $ext_if tagged SPAMD keep state
pass out quick on $ext_if tagged LAN_INET keep state
pass out quick on $dmz_if tagged LAN_DMZ keep state
pass out quick on $dmz_if tagged INET_DMZ keep state
標記乙太網幀
打標記可以在乙太網級別進行,如果執行標記/過濾的機器同時做為網橋。通過創建使用tag關鍵字的網橋過濾規則,PF可以建立基於源/目的MAC地址的過濾規則。網橋規則可以由brconfig(8)命令產生,例如:
# brconfig bridge0 rule pass in on fxp0 src 0:de:ad:be:ef:0 \
tag USER1
然後在 pf.conf檔案中:
pass in on fxp0 tagged USER1
日誌
簡介
PF的包日誌是由pflogd完成的,它通過監聽pflog0接口然後將包以tcpdump二進制格式寫入日誌檔案(一般在/val/log/pflog)。過濾規則定義的日誌和log-all關鍵字所定義的日誌都是以這種方式記錄的。
讀取日誌檔案
由pflogd生成的二進制格式日誌檔案不能通過文本編輯器讀取,必須使用Tcpdump來查看日誌。
使用如下格式查看日誌信息:
# tcpdump -n -e -ttt -r /var/log/pflog
使用tcpdump( 查看日誌檔案並不是實時的,若要實時查詢日誌信息需加上pflog0參數:
# tcpdump -n -e -ttt -i pflog0
注意:當查看日誌時需要特別注意tcpdump的詳細協定解碼(通過在命令行增加-v參數實現)。
Tcpdump的詳細協定解碼器並不具備完美的安全歷史,至少在理論上是這樣。日誌記錄設備所記載的部分包信息可能會引發延時攻擊,因此推薦在查詢日誌檔案信息之前先將該日誌檔案從防火牆上移走。
另外需要注意的是對日誌檔案的安全訪問。默認情況下,pflogd 將在日誌檔案中記錄96位元組的包信息。訪問日誌檔案將提供訪問部分敏感包信息的途徑(就像telnet(1)或者ftp(1)的用戶名和密碼)。
導出日誌
由於pflogd以tcpdump二進制格式記錄日誌信息,因此當回顧這些日誌時可以使用tcpdump的很多特點。例如,只查看與特定連線埠匹配的包:
# tcpdump -n -e -ttt -r /var/log/pflog port 80
甚至可以限定具體的主機和連線埠:
# tcpdump -n -e -ttt -r /var/log/pflog port 80 and host 192.168.1.3
同樣的方法可以套用到直接從pflog0接口讀取的信息:
# tcpdump -n -e -ttt -i pflog0 host 192.168.4.2
注意這與包被記錄到pflogd日誌檔案不相衝突;上述語句只以包被記錄的形式顯示。
除了使用標準的tcpdump(8)過濾規則外,OpenBSD的tcpdump過濾語言為讀取pflogd而被擴展:
* ip -IPv4版本地址。
* ip6 - IPv6版本地址。
* on int - 包通過int接口。
* ifname int - 與 on int相同.
* rulenum num - 包匹配的過濾規則編號為num。
* action act - 對包的操作。可能是pass(通過)或者block(阻斷)。
* reason res - 執行對包操作的原因。可能的原因是match(匹配), bad-offset, fragment, short, normalize(規格化), memory(記憶體)。
* inbound -入棧包。
* outbound - 出棧包。
舉例:
# tcpdump -n -e -ttt -i pflog0 inbound and action block and on wi0
這將以實時方式顯示被wi0接口阻斷的入棧包的日誌信息。
通過Syslog記錄日誌
很多情況下需要將防火牆的日誌記錄以ASCII代碼格式存儲,或者(同時)把這些日誌存到遠程的日誌伺服器上。這些可以通過兩個小的腳本檔案實現,是對 openbsd配置檔案和syslogd,日誌守護進程的少許修改。Syslogd進程以ASCII格式存儲日誌,同時可以將日誌存儲到遠程日誌伺服器。
首先必須建立一個用戶,pflogger,使用 /sbin/nologin shell.最簡單的建立用戶的方法是使用adduser(8)。
完成後建立如下兩個腳本:
/etc/pflogrotate
FILE=/home/pflogger/pflog5min.$(date " %Y%m%d%H%M")
kill -ALRM $(cat /var/run/pflogd.pid)
if [ $(ls -l /var/log/pflog | cut -d " " -f -gt 24 ]; then
mv /var/log/pflog $FILE
chown pflogger $FILE
kill -HUP $(cat /var/run/pflogd.pid)
fi
/home/pflogger/pfl2sysl
for logfile in /home/pflogger/pflog5min* ; do
tcpdump -n -e -ttt -r $logfile | logger -t pf -p local0.info
rm $logfile
done
編輯root的cron 任務:
# crontab -u root -e
增加如下兩行:
# rotate pf Log File every 5 minutes
0-59/5 * * * * /bin/sh /etc/pflogrotate
為用戶pflogger建立一個cron任務:
# crontab -u pflogger -e
增加如下兩行:
# feed rotated pflog file(s) to syslog
0-59/5 * * * * /bin/sh /home/pflogger/pfl2sysl
將下行增加到 /etc/syslog.conf:
local0.info /var/log/pflog.txt
如果需要日誌記錄到遠程日誌伺服器,增加:
local0.info @syslogger
確定主機syslogger已在hosts(5)中定義。
建立檔案 /var/log/pflog.txt 使 syslog 可以向該檔案寫入日誌:
# touch /var/log/pflog.txt
重啟syslogd使變化生效:
# kill -HUP $(cat /var/run/syslog.pid)
所有符合標準的包將被寫入/var/log/pflog.txt. 如果增加了第二行,這些信息也將被存入遠程日誌伺服器syslogger。
腳本 /etc/pflogrotate 將執行,然後刪除 /var/log/pflog ,因此
rotation of pflog by newsyslog(Cool 不再必需可以被禁用。然而, /var/log/pflog.txt 替代 /var/log/pflog and rotation of it 要被啟用。 改變 /etc/newsyslog.conf 如下:
#/var/log/pflog 600 3 250 * ZB /var/run/pflogd.pid
/var/log/pflog.txt 600 7 * 24
PF 將日誌以ASCII格式記錄到/var/log/pflog.txt. 如果這樣配置 /etc/syslog.conf, 系統將把日誌存到遠程伺服器。存儲過程不會馬上發生,但是會在符合條件的包出現在檔案中前5-6分鐘實現。
性能
“PF可以處理多少頻寬?”
“我需要多少台計算機處理網際網路連線?”
這個問題沒有簡單的答案。對於一些應用程式來說,一台486/66主機,帶有2個比較好的ISA網卡在做過濾和NAT時接近5Mbps,但是對於其他應用程式,一個更快的計算機加上更有效的PCI網卡也會顯得能力不足。真正的問題不是每秒處理的位數而是每秒處理的包數和規則集的複雜程度。
體現PF性能的幾個參數:
* 每秒處理包的數量.
一個1500位元組的包和一個只有1個位元組的包所需要的處理過程的數目幾乎是一樣的。每秒處理包的數量標誌著狀態表和過濾規則集在每秒內被評估的次數 ,標誌著一個系統最有效的需求(在沒有匹配的情況下)。
* 系統匯流排性能.
ISA 匯流排最大頻寬 8MB/秒, 當處理器訪問它時, 它必須降速到80286的有效速度,不管處理器的真實處理速度如何,PCI匯流排有更有效的頻寬,與處理器的衝突更小。
* 網卡的效率.
一些網卡的工作效率要高於其他網卡。 基於Realtek 8139的網卡性能較低,而基於 Intel 21143 的網卡性能較好。為了取得更好的性能,建議使用千兆網卡,儘管所連線的網路不是千兆網,這些千兆網卡擁有高級的快取,可以大幅提高性能。
* 規則集的設計和複雜性。
規則越複雜越慢。越多的包通過keep和quick方式過濾,性能越好。對每個包的策略越多,性能越差。
* 值得一提:
CPU 和記憶體。由於PF是基於核心的進程,它不需要swap空間。所以,如果你有足夠的記憶體,它將運行很好,如果沒有,將受影響。不需要太大量的記憶體。 32MB記憶體對小型辦公室或者家庭套用足夠,300MHz的cpu如果配置好網卡和規則集,足夠滿足要求。
人們經常詢問PF的基準點。唯一的基準是在一個環境下系統的性能。不考慮環境因素將影響所設計的防火牆的系統性能。
PF 曾經在非常大流量的系統中工作,同時PF的開發者也是它的忠實用戶。
研究 FTP
 PF防火牆
PF防火牆FTP是一種協定,它可以追溯到網際網路發展初期,那時的網際網路規模小,聯網的計算機彼此友好,過濾和嚴格安全性在那時不是必須的。FTP設計之初就沒有考慮包過濾、穿透防火牆和NAT。
FTP的工作模式分為被動(passive)和主動(active)兩種。通常這兩種選擇被用來確定哪邊有防火牆問題。實際上,為了方便用戶應該全部支持這兩種模式。
在active模式下,當用戶訪問遠程FTP伺服器並請求一個檔案信息時,那台FTP伺服器將與該用戶建立一個新的連線用來傳輸請求的數據,這被稱為數據連線。具體過程為:客戶端隨機選擇一個連線埠號,在該連線埠監聽的同時將連線埠號傳給伺服器,由伺服器向客戶端的該連線埠發起連線請求,然後傳遞數據。在 NAT後的用戶訪問FTP伺服器的時候會出現問題,由於NAT的工作機制,伺服器將向NAT網關的外部地址的所選連線埠發起連線,NAT網關收到該信息後將在自己的狀態表中查找該連線埠對應的內部主機,由於狀態表中不存在這樣的記錄,因此該包被丟棄,導致無法建立連線。
在passive模式下(OpenBSD的ftp客戶端默認模式),由客戶端請求伺服器隨機選擇一個連線埠並在此連線埠監聽,伺服器通知客戶端它所選擇的連線埠號,等待客戶端連線。不幸的是,ftp伺服器前的防火牆可能會阻斷客戶端發往伺服器的請求信息。OpenBSD的ftp(1)默認使用 passive模式;要強制改為active模式,使用-A參數,或者在“ftp>”提示符下使用命令“passive off”關閉 passive模式。
工作在防火牆之後的FTP客戶端
如前所述,FTP對NAT和防火牆支持不好。
包過濾機制通過將FTP數據包重定向到一個FTP代理伺服器解決這一問題。這一過程將引導FTP數據包通過NAT網關/防火牆。OpenBSD和PF使用的FTP代理是ftp-proxy(8),可以通過在pf.conf中的NAT章節增加下列信息激活該代理:
rdr on $int_if proto tcp from any to any port 21 -> 127.0.0.1 \
port 8021
這條語句的解釋為:在內部接口上的ftp數據包被重定向到本機的8021連線埠
顯然該代理伺服器應該已在OpenBSD中啟動並運行。配置方法為在/etc/inetd.conf中增加下列信息:
127.0.0.1:8021 stream tcp nowait root /usr/libexec/ftp-proxy \
ftp-proxy
重啟系統或者通過下列命令傳送一個‘HUP’標記來生效:
kill -HUP `cat /var/run/inetd.pid`
ftp代理在8021連線埠監聽,上面的rdr語句也是將數據包轉發到這一連線埠。這一連線埠號是可選的,因為8021連線埠沒有被其他應用程式占用,因此不失為一個好的選擇。
請注意ftp-proxy(8)是用來幫助位於PF過濾器後的ftp客戶端傳遞信息;並不用於PF過濾器後的ftp伺服器。
PF“自保護”FTP伺服器
當PF運行在一個FTP伺服器上,而不是單獨的一台防火牆。這種情況下處理passive模式的FTP連線請求時FTP伺服器將隨機取一個較大的 TCP連線埠接收數據。默認情況下OpenBSD的本地FTP伺服器ftpd(8)使用49152~65535範圍內的連線埠,顯然,必須要有對應的過濾規則放行這些連線埠的數據:
pass in on $ext_if proto tcp from any to any port 21 keep state
pass in on $ext_if proto tcp from any to any port > 49151 \
keep state
如果需要可以調整上述連線埠範圍。在OpenBSD的ftpd(8)環境下,可以通過sysctl(8)進行調整 net.inet.ip.porthifirst 和net.inet.ip.porthilast。
使用NAT外部 PF防火牆保護FTP伺服器
這種情況下,防火牆必須將數據重定向到FTP伺服器。為了討論方便,我們假設該FTP伺服器使用標準的OpenBSD ftpd(8),並使用默認連線埠範圍。
這裡有個例子
ftp_server = "10.0.3.21"
rdr on $ext_if proto tcp from any to any port 21 -> $ftp_server \
port 21
rdr on $ext_if proto tcp from any to any port 49152:65535 -> \
$ftp_server port 49152:65535
# in on $ext_if
pass in quick on $ext_if proto tcp from any to $ftp_server \
port 21 keep state
pass in quick on $ext_if proto tcp from any to $ftp_server \
port > 49151 keep state
# out on $int_if
pass out quick on $int_if proto tcp from any to $ftp_server \
port 21 keep state
pass out quick on $int_if proto tcp from any to $ftp_server \
port > 49151 keep state
FTP的更多信息
過濾FTP和FTP如何工作的更多信息可以參考下面的白皮書。
驗證: 用Shell 進行網關驗證
簡介
Authpf(Cool是身份認證網關的用戶shell。身份認證網關類似於普通網關,只不過用戶必須在網關上通過身份驗證後才能使用該網關。當用戶 shell被設定為/usr/sbin/authpf時(例如,代替了ksh(1),csh(1)等),並且用戶通過SSH登錄,authpf將對pf (4)策略集做必要的修改以便該用戶的數據包可以通過過濾器或者(和)使用NAT、重定向功能。一旦用戶退出登錄或者連線被斷開,authpf將移除載入到該用戶上的所有策略,同時關閉該用戶打開的所有會話。因此,只有當用戶保持著他的SSH會話進程時他才具備透過防火牆傳送數據包的能力。
Authpf通過向附加到錨點的命名策略集增加策略來改變pf(4)的策略集。每次用戶進行身份驗證,authpf建立一個新的命名策略集,並將已經配置好的filter、nat、binat和rdr規則載入上去。被authpf所載入的策略可以被配置為針對單獨的一個用戶相關或者針對總體。
Authpf可以套用在:
* 在允許用戶訪問網際網路之前進行身份驗證。
* 賦予特殊用戶訪問受限網路的權利,例如管理員。
* 只允許特定的無線網路用戶訪問特定的網路。
* 允許公司員工在任何時候訪問公司網路,而公司之外的用戶不能訪問,並可以將這些用戶重定向到特定的基於用戶名的資源(例如他們自己的桌面)。
* 在類似圖書館這樣的地方通過PF限制guest用戶對網際網路的訪問。Authpf可以用來向已註冊用戶開放完全的網際網路連線。
Authpf通過syslogd(8)記錄每一個成功通過身份驗證用戶的用戶名、IP位址、開始結束時間。通過這些信息,管理員可以確定誰在何時登入,也使得用戶對其網路流量負責。
配置
配置authpf的基本步驟大致描述如下。詳細的信息請查看man手冊。
將authpf連入主策略集
通過使用錨點策略將authpf連入主策略集:
nat-anchor authpf
rdr-anchor authpf
binat-anchor authpf
anchor authpf
錨點策略放入策略集的位置就是PF中斷執行主策略集轉為執行authpf策略的位置。上述4個錨點策略並不需要全部存在,例如,當authpf沒有被設定載入任何nat策略時,nat-anchor策略可被省略。
配置載入的策略
Authpf通過下面兩個檔案之一載入策略:
* /etc/authpf/users/$USER/authpf.rules
* /etc/authpf/authpf.rules
第一個檔案包含只有當用戶$USER(將被替換為具體的用戶名)登錄時才被載入的策略。當特殊用戶(例如管理員)需要一系列不同於其他默認用戶的策略集時可以使用每用戶策略配置。第二個檔案包含沒定義自己的authpf.rules檔案的用戶所默認載入的策略。如果用戶定義的檔案存在,將覆蓋默認檔案。這兩個檔案至少存在其一,否則authpf將不會工作。
過濾器和傳輸策略與其他的PF策略集語法一樣,但有一點不同:authpf允許使用預先定義的宏:
* $user_ip �C 登錄用戶的IP位址
* $user_id �C 登錄用戶的用戶名
推薦使用宏$user_ip,只賦予通過身份驗證的計算機透過防火牆的許可權。
訪問控制列表
可以通過在/etc/authpf/banned/目錄下建立以用戶名命名的檔案來阻止該用戶使用authpf。檔案的內容將在authpf斷開與該用戶的連線之前顯示給他,這為通知該用戶被禁止訪問的原因並告知他解決問題聯繫人提供了一個便捷的途徑。
相反,有可能只允許特定的用戶訪問,這時可以將這些用戶的用戶名寫入/etc/authpf/authpf.allow檔案。如果該檔案不存在或者檔案中輸入了“*”,則authpf將允許任何成功通過SSH登錄的用戶進行訪問(沒有被明確禁止的用戶)。
如果authpf不能斷定一個用戶名是被允許還是禁止,它將列印一個摘要信息並斷開該用戶的連線。明確禁止將會使明確允許失效。
將authpf配置為用戶shell
authpf必須作為用戶的登錄shell才能正常工作。當用戶成功通過sshd(8)登錄後,authpf將被作為用戶的shell執行。它將檢查該用戶是否有權使用authpf,並從適當的檔案中載入策略,等等。
有兩種途徑將authpf設定為用戶shell:
1.為每個用戶手動使用chsh(1), vipw(Cool, useradd(Cool, usermod(Cool,等。
2.通過把一些用戶分配到一個登錄類,在檔案/etc/login.conf中改變這個登錄類的shell屬性
查看登入者
一旦用戶成功登錄,並且authpf調整了PF的策略,authpf將改變它的進程名以顯示登錄者的用戶名和IP位址:
# ps -ax | grep authpf
23664 p0 Is 0:00.11 -authpf: [email protected] (authpf)
在這裡用戶chalie從IP位址為192.168.1.3的主機登錄。用戶可以通過向authpf進程傳送SIGTERM信號退出登錄。Authpf也將移除載入到該用戶上的策略並關閉任何該用戶打開的會話連線。
# kill -TERM 23664
實例
OpenBSD網關通過authpf對一個大型校園無線網的用戶進行身份驗證。一旦某個用戶驗證通過,假設他不在禁用列表中,他將被允許SSH並訪問網頁(包括安全網站https),也可以訪問該校園的任一個DNS伺服器。
檔案 /etc/authpf/authpf.rules包含下列策略:
wifi_if = "wi0"
dns_servers = "{ 10.0.1.56, 10.0.2.56 }"
pass in quick on $wifi_if proto udp from $user_ip to $dns_servers \
port domain keep state
pass in quick on $wifi_if proto tcp from $user_ip to port { ssh, http, \
https } flags S/SA keep state
管理員charlie除了網頁衝浪和使用SSH外還需要訪問校園網的SMTP和POP3伺服器。下列策略被配置在/etc/authpf/users/charlie/authpf.rules 中:
wifi_if = "wi0"
smtp_server = "10.0.1.50"
pop3_server = "10.0.1.51"
dns_servers = "{ 10.0.1.56, 10.0.2.56 }"
pass in quick on $wifi_if proto udp from $user_ip to $dns_servers \
port domain keep state
pass in quick on $wifi_if proto tcp from $user_ip to $smtp_server \
port smtp flags S/SA keep state
pass in quick on $wifi_if proto tcp from $user_ip to $pop3_server \
port pop3 flags S/SA keep state
pass in quick on $wifi_if proto tcp from $user_ip to port { ssh, http, \
https } flags S/SA keep state
定義在/etc/pf.conf中的主策略集配置如下:
# macros
wifi_if = "wi0"
ext_if = "fxp0"
scrub in all
# filter
block drop all
pass out quick on $ext_if proto tcp from $wifi_if:network flags S/SA \
modulate state
pass out quick on $ext_if proto { udp, icmp } from $wifi_if:network \
keep state
pass in quick on $wifi_if proto tcp from $wifi_if:network to $wifi_if \
port ssh flags S/SA keep state
anchor authpf in on $wifi_if
該策略集非常簡單,作用如下:
* 阻斷所有(默認拒絕)。
* 放行外部網卡接口上的來自無線網路並流向外部的TCP,UDP和ICMP數據包。
* 放行來自無線網路,目的地址為網關本身的SSH數據包。該策略是用戶登錄所必須的。
* 在無線網路接口上為流入數據建立錨點“authpf”。
設計主策略集的主導思想為:阻斷任何包並允許儘可能小的數據流通過。在外部接口上流出數據包是允許的,但是默認否策略阻斷了由無線接口進入的數據包。用戶一旦通過驗證,他們的數據包被允許通過無線接口進入並穿過網關到達其他網路。
實例:家庭和小型辦公室防火牆
概況
在這個例子中,PF作為防火牆和NAT網關運行在OpenBSD機器上,為家庭或辦公室的小型網路提供服務。總的目標是向內部網提供網際網路接入,允許從網際網路到防火牆的限制訪問。下面將詳細描述:
網路
網路配置如下:
[ COMP1 ] [ COMP3 ]
| | ADSL
--- ------ ----- ------- fxp0 [ OpenBSD ] ep0 -------- ( 網際網路 )
|
[ COMP2 ]
內部網有若干機器,圖中只劃出了3台,這些機器除了COMP3之外主要進行網頁衝浪、電子郵件、聊天等;COMP3運行一個小型web伺服器。內部網使用192.168.0.0/24網段。
OpenBSD網關運行在Pentium 100計算機上,裝有兩塊網卡:一個3com 3c509B(ep0),另一個 Intel EtherExpress Pro/100(fxp0)。該網關通過ADSL連線到網際網路,同時通過NAT向區域網路共享網際網路連線。外部網卡的 IP 地址動態分配。
目標
* 向內部網路的每台計算機提供無限制的網際網路接入。
* 啟用一條“默認拒絕”策略。
* 允許下列來自網際網路的請求訪問防火牆:
SSH (TCP 連線埠 22): 用來遠程維護防火牆。
Auth/Ident (TCP 連線埠 113): SMTP和IRC服務用到的連線埠。
ICMP Echo Requests: ping 用到的ICMP包類型。
* 重定向訪問80連線埠的請求到計算機COMP3,同時,允許指向COMP3計算機的80連線埠的數據流過防火牆。
* 記錄外部網卡接口上的過濾日誌。
* 默認為阻斷的包返回一個 TCP RST 或者 ICMP Unreachable 信息。
* 儘量保持策略集簡單並易於維護。
準備
這裡假設作為網關的OpenBSD主機已經配置完成,包括IP網路配置,網際網路連線和設定net.inet.ip.forwarding 的值為1。
規則集
下面將逐步建立策略集以滿足抗訴要求。
宏
定義下列宏以增強策略集的可維護性和可讀性:
int_if = "fxp0"
ext_if = "ep0"
tcp_services = "{ 22, 113 }"
icmp_types = "echoreq"
priv_nets = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }"
comp3 = "192.168.0.3"
前兩行定義了發生過濾的網路接口。第3、4行定義了向網際網路開放的服務連線埠號(SSH和ident/auth)和允許訪問防火牆的ICMP包類型。第5行定義了回送地址段和RFC1918定義的私有地址段。最後一行定義了主機COMP3的IP位址。
注意:如果ADSL接入網際網路需要PPPoE,則過濾和NAT將發生在tun0接口上而不是ep0接口。
選項
下列兩個選項用來設定阻斷後的默認操作為反饋,並在外部接口設定開啟日誌記錄:
set block-policy return
set loginterface $ext_if
流量整修
沒有理由不起用對所有進入防火牆的所有包進行規格化,因此只需要簡單的一行:
scrub in all
NAT(網路地址轉換)
為所有內部網啟用NAT可以通過下列策略:
nat on $ext_if from $int_if:network to any -> ($ext_if)
由於外部網卡的IP位址是動態獲得的,因此在外部網卡接口處增加小括弧以使當IP位址發生變化時PF可以自適應。
重定向
第一個需要重定向策略的是ftp-proxy(8),只有這樣內部網上的FTP客戶端才可以訪問網際網路上的FTP伺服器。
rdr on $int_if proto tcp from any to any port 21 -> 127.0.0.1 port 8021
注意這條策略只捕獲到21連線埠的數據包,如果用戶通過其他連線埠訪問FTP伺服器,則在定義目的連線埠時需要使用list(列表),例如: from any to any port { 21, 2121 }。
第二個重定向策略捕獲網際網路上的用戶訪問防火牆80連線埠的數據包。用戶試圖訪問網路的web伺服器時將產生合法的訪問該連線埠的數據包,這些連線請求需要重定向到主機COMP3:
rdr on $ext_if proto tcp from any to any port 80 -> $comp3
過濾規則
過濾規則第一行是默認否規則:
block all
這時沒有任何數據包可以流過防火牆,甚至來自內部網路的數據包。下面的規則將逐個依據上面提到的目標開啟防火牆上的虛擬接口。
每個Unix系統都有一個“loopback(回送)”接口,它是用於系統中應用程式間通信的虛擬網路接口。在OpenBSD中,回送接口是lo(4)。
pass quick on lo0 all
下一步,由RFC 1918定義的私有地址將在外部網卡接口的進和出方向被阻斷。這些地址不應該出現在公網上,通過阻斷這些地址可以保證防火牆不向外部網泄漏區域網路地址,同時也阻斷了來自外部網中源地址為這些私有地址的數據包流入區域網路。
block drop in quick on $ext_if from $priv_nets to any
block drop out quick on $ext_if from any to $priv_nets
這裡block drop用來通知PF停止反饋TCP RST或者ICMP Unreachabel 數據包。因為RFC 1918規定的地址不會存在於網際網路上,發往那些地址的數據包將沒有意義。Quick 選項用來通知PF如果這條規則匹配則不再進行其他規則的匹配操作,來自或流向$ priv_nets的數據包將被立即丟棄。
現在將打開網際網路上的一些服務所用到的連線埠:
pass in on $ext_if inet proto tcp from any to ($ext_if) \
port $tcp_services flags S/SA keep state
通過在宏$tcp_services中定義服務連線埠可以更方便的進行維護。開放UDP服務也可一模仿上述語句,只不過改為proto udp。
已經有了一條rdr策略將web訪問請求轉發到主機COMP3上,我們必須建立另一條過濾規則使得這些訪問請求可以通過防火牆:
pass in on $ext_if proto tcp from any to $comp3 port 80 \
flags S/SA synproxy state
考慮到安全問題,我們使用TCP SYN Proxy保護web伺服器――synproxy state。
現在將允許ICMP包通過防火牆:
pass in inet proto icmp all icmp-type $icmp_types keep state
類似於宏$tcp_services,當需要增加允許進入防火牆的ICMP數據包類型時可以容易地編輯宏$icmp_types。注意這條策略將套用於所有網路接口。
現在數據流必須可以正常出入內部網路。我們假設區域網路的用戶清楚自己的所作所為並且確定不會導致麻煩。這並不是必然有效的假設,在某些環境下更具限制性的策略集會更適合。
pass in on $int_if from $int_if:network to any keep state
上面的策略將允許區域網路中的任何計算機傳送數據包穿過防火牆;然而,這並沒有允許防火牆主動與區域網路的計算機建立連線。這是一種好的方法嗎?評價這些需要依靠網路配置的一些細節。如果防火牆同時充當DHCP伺服器,它需要在分配一個地址之前ping一下該地址以確認該地址沒有被占用。允許防火牆訪問內部網路同時也允許了在網際網路上通過ssh控制防火牆的用戶訪問區域網路。請注意禁止防火牆直接訪問區域網路並不能帶來高安全性,因為如果一個用戶可以訪問防火牆,他也可以改變防火牆的策略。增加下列策略可以使防火牆具備訪問區域網路的能力:
pass out on $int_if from any to $int_if:network keep state
如果這些策略同時存在,則keep state選項將不是必須的;所有的數據包都可以流經區域網路接口,因為一條策略規定了雙向放行數據包。然而,如果沒有pass out這條策略時,pass in策略必須要有keep state選項。這也是keep state的有點所在:在執行策略匹配之前將先進行state表檢查,如果state表中存在匹配記錄,數據包將直接放行而不比再進行策略匹配。這將提高符合比較重的防火牆的效率。
最後,允許流出外部網卡接口的數據包通過防火牆
pass out on $ext_if proto tcp all modulate state flags S/SA
pass out on $ext_if proto { udp, icmp } all keep state
TCP, UDP, 和 ICMP數據包將被允許朝網際網路的方向出防火牆。State信息將被保存,以保證反饋回來的數據包通過防火牆。
完整規則集
# macros
int_if = "fxp0"
ext_if = "ep0"
tcp_services = "{ 22, 113 }"
icmp_types = "echoreq"
priv_nets = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }"
comp3 = "192.168.0.3"
# options
set block-policy return
set loginterface $ext_if
# scrub
scrub in all
# nat/rdr
nat on $ext_if from $int_if:network to any -> ($ext_if)
rdr on $int_if proto tcp from any to any port 21 -> 127.0.0.1 \
port 8021
rdr on $ext_if proto tcp from any to any port 80 -> $comp3
# filter rules
block all
pass quick on lo0 all
block drop in quick on $ext_if from $priv_nets to any
block drop out quick on $ext_if from any to $priv_nets
pass in on $ext_if inet proto tcp from any to ($ext_if) \
port $tcp_services flags S/SA keep state
pass in on $ext_if proto tcp from any to $comp3 port 80 \
flags S/SA synproxy state
pass in inet proto icmp all icmp-type $icmp_types keep state
pass in on $int_if from $int_if:network to any keep state
pass out on $int_if from any to $int_if:network keep state
pass out on $ext_if proto tcp all modulate state flags S/SA
pass out on $ext_if proto { udp, icmp } all keep state
