
產生
在計算機中,所有的數據在存儲和運算時都要使用二進制數表示(因為計算機用高電平和低電平分別表示1和0),例如,像a、b、c、d這樣的52個字母(包括大寫)、以及0、1等數字還有一些常用的符號(例如*、#、@等)在計算機中存儲時也要使用二進制數來表示,而具體用哪些二進制數字表示哪個符號,當然每個人都可以約定自己的一套(這就叫編碼),而大家如果要想互相通信而不造成混亂,那么大家就必須使用相同的編碼規則,於是美國有關的標準化組織就出台了ASCII編碼,統一規定了上述常用符號用哪些二進制數來表示。
美國標準信息交換代碼是由美國國家標準學會(American National Standard Institute,ANSI )制定的,標準的單位元組字元編碼方案,用於基於文本的數據。起始於50年代後期,在1967年定案。它最初是美國國家標準,供不同計算機在相互通信時用作共同遵守的西文字元編碼標準,它已被國際標準化組織(International Organization for Standardization,ISO)定為國際標準,稱為ISO 646標準。適用於所有拉丁文字字母。
表述方式
ASCII碼使用指定的7位或8位二進制數組合來表示128或256種可能的字元。標準ASCII碼也叫基礎ASCII碼,使用7位二進制數來表示所有的大寫和小寫字母,數字0到9、標點符號,以及在美式英語中使用的特殊控制字元。其中:0~31及127(共33個)是控制字元或通信專用字元(其餘為可顯示字元),如控制符:LF(換行)、CR(回車)、FF(換頁)、DEL(刪除)、BS(退格)、BEL(響鈴)等;通信專用字元:SOH(文頭)、EOT(文尾)、ACK(確認)等;ASCII值為8、9、10和13分別轉換為退格、制表、換行和回車字元。它們並沒有特定的圖形顯示,但會依不同的應用程式,而對文本顯示有不同的影響。
32~126(共95個)是字元(32是空格),其中48~57為0到9十個阿拉伯數字。65~90為26個大寫英文字母,97~122號為26個小寫英文字母,其餘為一些標點符號、運算符號等。
同時還要注意,在標準ASCII中,其最高位(b7)用作奇偶校驗位。所謂奇偶校驗,是指在代碼傳送過程中用來檢驗是否出現錯誤的一種方法,一般分奇校驗和偶校驗兩種。奇校驗規定:正確的代碼一個位元組中1的個數必須是奇數,若非奇數,則在最高位b7添1;偶校驗規定:正確的代碼一個位元組中1的個數必須是偶數,若非偶數,則在最高位b7添1。
後128個稱為擴展ASCII碼。許多基於x86的系統都支持使用擴展(或“高”)ASCII。擴展ASCII碼允許將每個字元的第8位用於確定附加的128個特殊符號字元、外來語字母和圖形符號。
標準I表
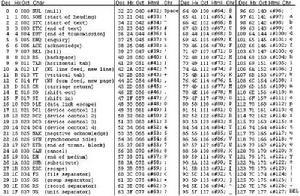
| Bin | Dec | Hex | 縮寫/字元 | 解釋 | |
| 0000 0000 | 0 | 00 | NUL(null) | 空字元 | |
| 0000 0001 | 1 | 01 | SOH(start of headline) | 標題開始 | |
| 0000 0010 | 2 | 02 | STX (start of text) | 正文開始 | |
| 0000 0011 | 3 | 03 | ETX (end of text) | 正文結束 | |
| 0000 0100 | 4 | 04 | EOT (end of transmission) | 傳輸結束 | |
| 0000 0101 | 5 | 05 | ENQ (enquiry) | 請求 | |
| 0000 0110 | 6 | 06 | ACK (acknowledge) | 收到通知 | |
| 0000 0111 | 7 | 07 | BEL (bell) | 響鈴 | |
| 0000 1000 | 8 | 08 | BS (backspace) | 退格 | |
| 0000 1001 | 9 | 09 | HT (horizontal tab) | 水平制表符 | |
| 0000 1010 | 10 | 0A | LF (NL line feed, new line) | 換行鍵 | |
| 0000 1011 | 11 | 0B | VT (vertical tab) | 垂直制表符 | |
| 0000 1100 | 12 | 0C | FF (NP form feed, new page) | 換頁鍵 | |
| 0000 1101 | 13 | 0D | CR (carriage return) | 回車鍵 | |
| 0000 1110 | 14 | 0E | SO (shift out) | 不用切換 | |
| 0000 1111 | 15 | 0F | SI (shift in) | 啟用切換 | |
| 0001 0000 | 16 | 10 | DLE (data link escape) | 數據鏈路轉義 | |
| 0001 0001 | 17 | 11 | DC1 (device control 1) | 設備控制1 | |
| 0001 0010 | 18 | 12 | DC2 (device control 2) | 設備控制2 | |
| 0001 0011 | 19 | 13 | DC3 (device control 3) | 設備控制3 | |
| 0001 0100 | 20 | 14 | DC4 (device control 4) | 設備控制4 | |
| 0001 0101 | 21 | 15 | NAK (negative acknowledge) | 拒絕接收 | |
| 0001 0110 | 22 | 16 | SYN (synchronous idle) | 同步空閒 | |
| 0001 0111 | 23 | 17 | ETB (end of trans. block) | 傳輸塊結束 | |
| 0001 1000 | 24 | 18 | CAN (cancel) | 取消 | |
| 0001 1001 | 25 | 19 | EM (end of medium) | 介質中斷 | |
| 0001 1010 | 26 | 1A | SUB (substitute) | 替補 | |
| 0001 1011 | 27 | 1B | ESC (escape) | 換碼(溢出) | |
| 0001 1100 | 28 | 1C | FS (file separator) | 檔案分割符 | |
| 0001 1101 | 29 | 1D | GS (group separator) | 分組符 | |
| 0001 1110 | 30 | 1E | RS (record separator) | 記錄分離符 | |
| 0001 1111 | 31 | 1F | US (unit separator) | 單元分隔設定 | |
| 0010 0000 | 32 | 20 | (space) | 空格 | |
| 0010 0001 | 33 | 21 | ! | ||
| 0010 0010 | 34 | 22 | " | ||
| 0010 0011 | 35 | 23 | # | ||
| 0010 0100 | 36 | 24 | $ | ||
| 0010 0101 | 37 | 25 | % | ||
| 0010 0110 | 38 | 26 | & | ||
| 0010 0111 | 39 | 27 | ' | ||
| 0010 1000 | 40 | 28 | ( | ||
| 0010 1001 | 41 | 29 | ) | ||
| 0010 1010 | 42 | 2A | * | ||
| 0010 1011 | 43 | 2B | + | ||
| 0010 1100 | 44 | 2C | , | ||
| 0010 1101 | 45 | 2D | - | ||
| 0010 1110 | 46 | 2E | . | ||
| 00101111 | 47 | 2F | / | ||
| 00110000 | 48 | 30 | 0 | ||
| 00110001 | 49 | 31 | 1 | ||
| 00110010 | 50 | 32 | 2 | ||
| 00110011 | 51 | 33 | 3 | ||
| 00110100 | 52 | 34 | 4 | ||
| 00110101 | 53 | 35 | 5 | ||
| 00110110 | 54 | 36 | 6 | ||
| 00110111 | 55 | 37 | 7 | ||
| 00111000 | 56 | 38 | 8 | ||
| 00111001 | 57 | 39 | 9 | ||
| 00111010 | 58 | 3A | : | ||
| 00111011 | 59 | 3B | ; | ||
| 00111100 | 60 | 3C | < | ||
| 00111101 | 61 | 3D | = | ||
| 00111110 | 62 | 3E | > | ||
| 00111111 | 63 | 3F | ? | ||
| 01000000 | 64 | 40 | @ | ||
| 01000001 | 65 | 41 | A | ||
| 01000010 | 66 | 42 | B | ||
| 01000011 | 67 | 43 | C | ||
| 01000100 | 68 | 44 | D | ||
| 01000101 | 69 | 45 | E | ||
| 01000110 | 70 | 46 | F | ||
| 01000111 | 71 | 47 | G | ||
| 01001000 | 72 | 48 | H | ||
| 01001001 | 73 | 49 | I | ||
| 01001010 | 74 | 4A | J | ||
| 01001011 | 75 | 4B | K | ||
| 01001100 | 76 | 4C | L | ||
| 01001101 | 77 | 4D | M | ||
| 01001110 | 78 | 4E | N | ||
| 01001111 | 79 | 4F | O | ||
| 01010000 | 80 | 50 | P | ||
| 01010001 | 81 | 51 | Q | ||
| 01010010 | 82 | 52 | R | ||
| 01010011 | 83 | 53 | S | ||
| 01010100 | 84 | 54 | T | ||
| 01010101 | 85 | 55 | U | ||
| 01010110 | 86 | 56 | V | ||
| 01010111 | 87 | 57 | W | ||
| 01011000 | 88 | 58 | X | ||
| 01011001 | 89 | 59 | Y | ||
| 01011010 | 90 | 5A | Z | ||
| 01011011 | 91 | 5B | [ | ||
| 01011100 | 92 | 5C | \ | ||
| 01011101 | 93 | 5D | ] | ||
| 01011110 | 94 | 5E | ^ | ||
| 01011111 | 95 | 5F | _ | ||
| 01100000 | 96 | 60 | ` | ||
| 01100001 | 97 | 61 | a | ||
| 01100010 | 98 | 62 | b | ||
| 01100011 | 99 | 63 | c | ||
| 01100100 | 100 | 64 | d | ||
| 01100101 | 101 | 65 | e | ||
| 01100110 | 102 | 66 | f | ||
| 01100111 | 103 | 67 | g | ||
| 01101000 | 104 | 68 | h | ||
| 01101001 | 105 | 69 | i | ||
| 01101010 | 106 | 6A | j | ||
| 01101011 | 107 | 6B | k | ||
| 01101100 | 108 | 6C | l | ||
| 01101101 | 109 | 6D | m | ||
| 01101110 | 110 | 6E | n | ||
| 01101111 | 111 | 6F | o | ||
| 01110000 | 112 | 70 | p | ||
| 01110001 | 113 | 71 | q | ||
| 01110010 | 114 | 72 | r | ||
| 01110011 | 115 | 73 | s | ||
| 01110100 | 116 | 74 | t | ||
| 01110101 | 117 | 75 | u | ||
| 01110110 | 118 | 76 | v | ||
| 01110111 | 119 | 77 | w | ||
| 01111000 | 120 | 78 | x | ||
| 01111001 | 121 | 79 | y | ||
| 01111010 | 122 | 7A | z | ||
| 01111011 | 123 | 7B | { | ||
| 01111100 | 124 | 7C | | | ||
| 01111101 | 125 | 7D | } | ||
| 01111110 | 126 | 7E | ~ | ||
| 01111111 | 127 | 7F | DEL (delete) | 刪除 | |
| 八進制 | 十六進制 | 十進制 | 字元 | 八進制 | 十六進制 | 十進制 | 字元 |
| 0 | 0 | 0 | nul | 100 | 40 | 64 | @ |
| 1 | 1 | 1 | soh | 101 | 41 | 65 | A |
| 2 | 2 | 2 | stx | 102 | 42 | 66 | B |
| 3 | 3 | 3 | etx | 103 | 43 | 67 | C |
| 4 | 4 | 4 | eot | 104 | 44 | 68 | D |
| 5 | 5 | 5 | enq | 105 | 45 | 69 | E |
| 6 | 6 | 6 | ack | 106 | 46 | 70 | F |
| 7 | 7 | 7 | bel | 107 | 47 | 71 | G |
| 10 | 8 | 8 | bs | 110 | 48 | 72 | H |
| 11 | 9 | 9 | ht | 111 | 49 | 73 | I |
| 12 | 0a | 10 | nl | 112 | 4a | 74 | J |
| 13 | 0b | 11 | vt | 113 | 4b | 75 | K |
| 14 | 0c | 12 | ff | 114 | 4c | 76 | L |
| 15 | 0d | 13 | cr | 115 | 4d | 77 | M |
| 16 | 0e | 14 | so | 116 | 4e | 78 | N |
| 17 | 0f | 15 | si | 117 | 4f | 79 | O |
| 20 | 10 | 16 | dle | 120 | 50 | 80 | P |
| 21 | 11 | 17 | dc1 | 121 | 51 | 81 | Q |
| 22 | 12 | 18 | dc2 | 122 | 52 | 82 | R |
| 23 | 13 | 19 | dc3 | 123 | 53 | 83 | S |
| 24 | 14 | 20 | dc4 | 124 | 54 | 84 | T |
| 25 | 15 | 21 | nak | 125 | 55 | 85 | U |
| 26 | 16 | 22 | syn | 126 | 56 | 86 | V |
| 27 | 17 | 23 | etb | 127 | 57 | 87 | W |
| 30 | 18 | 24 | can | 130 | 58 | 88 | X |
| 31 | 19 | 25 | em | 131 | 59 | 89 | Y |
| 32 | 1a | 26 | sub | 132 | 5a | 90 | Z |
| 33 | 1b | 27 | esc | 133 | 5b | 91 | [ |
| 34 | 1c | 28 | fs | 134 | 5c | 92 | \ |
| 35 | 1d | 29 | gs | 135 | 5d | 93 | ] |
| 36 | 1e | 30 | re | 136 | 5e | 94 | ^ |
| 37 | 1f | 31 | us | 137 | 5f | 95 | _ |
| 40 | 20 | 32 | sp | 140 | 60 | 96 | ' |
| 41 | 21 | 33 | ! | 141 | 61 | 97 | a |
| 42 | 22 | 34 | " | 142 | 62 | 98 | b |
| 43 | 23 | 35 | # | 143 | 63 | 99 | c |
| 44 | 24 | 36 | $ | 144 | 64 | 100 | d |
| 45 | 25 | 37 | % | 145 | 65 | 101 | e |
| 46 | 26 | 38 | & | 146 | 66 | 102 | f |
| 47 | 27 | 39 | ` | 147 | 67 | 103 | g |
| 50 | 28 | 40 | ( | 150 | 68 | 104 | h |
| 51 | 29 | 41 | ) | 151 | 69 | 105 | i |
| 52 | 2a | 42 | * | 152 | 6a | 106 | j |
| 53 | 2b | 43 | + | 153 | 6b | 107 | k |
| 54 | 2c | 44 | , | 154 | 6c | 108 | l |
| 55 | 2d | 45 | - | 155 | 6d | 109 | m |
| 56 | 2e | 46 | . | 156 | 6e | 110 | n |
| 57 | 2f | 47 | / | 157 | 6f | 111 | o |
| 60 | 30 | 48 | 0 | 160 | 70 | 112 | p |
| 61 | 31 | 49 | 1 | 161 | 71 | 113 | q |
| 62 | 32 | 50 | 2 | 162 | 72 | 114 | r |
| 63 | 33 | 51 | 3 | 163 | 73 | 115 | s |
| 64 | 34 | 52 | 4 | 164 | 74 | 116 | t |
| 65 | 35 | 53 | 5 | 165 | 75 | 117 | u |
| 66 | 36 | 54 | 6 | 166 | 76 | 118 | v |
| 67 | 37 | 55 | 7 | 167 | 77 | 119 | w |
| 70 | 38 | 56 | 8 | 170 | 78 | 120 | x |
| 71 | 39 | 57 | 9 | 171 | 79 | 121 | y |
| 72 | 3a | 58 | : | 172 | 7a | 122 | z |
| 73 | 3b | 59 | ; | 173 | 7b | 123 | { |
| 74 | 3c | 60 | < | 174 | 7c | 124 | | |
| 75 | 3d | 61 | = | 175 | 7d | 125 | } |
| 76 | 3e | 62 | > | 176 | 7e | 126 | ~ |
| 77 | 3f | 63 | ? | 177 | 7f | 127 | del |
 ASCII碼錶
ASCII碼錶大小規則
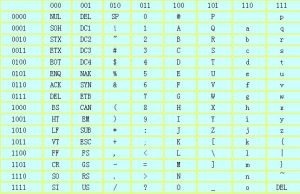 ASCII表
ASCII表1)數字0~9比字母要小。如"7"<"F";
2)數字0比數字9要小,並按0到9順序遞增。如"3"<"8"
3)字母A比字母Z要小,並按A到Z順序遞增。如"A"<"Z"
4)同個字母的大寫字母比小寫字母要小。如"A"<"a"。
記住幾個常見字母的ASCII碼大小:
“換行LF”為0x0A;“回車CR”為0x0D;空格為0x20;"0"為0x30;"A"為0x41;"a"為0x61。
另外還有128-255的ASCII字元。
查詢ASCII技巧,方便查詢ASCII碼對應的字元:新建一個文本文檔,按住ALT+要查詢的碼值(注意,這裡是十進制),鬆開即可顯示出對應字元。例如:按住ALT+97,則會顯示出a。
國際問題
ASCII是美國標準,所以它不能良好滿足其它講英語國家的需要。例如英國的英鎊符號(£)在哪裡?
拉丁語字母表重音符號。
使用斯拉夫字母表的希臘語、希伯來語、阿拉伯語和俄語。
漢字系統的中國象形漢字,日本和朝鮮。
1967年,國際標準化組織(ISO:InternationalStandardsOrganization)推薦一個ASCII的變種,
代碼0x40、0x5B、0x5C、0x5D、0x7B、0x7C和0x7D“為國家使用保留”,而代碼0x5E、0x60和0x7E標為“當國內要求的特殊字元需要8、9或10個空間位置時,可用於其它圖形符號”。這顯然不是一個最佳的國際解決方案。
因為這並不能保證一致性。但這卻顯示了人們如何想盡辦法為不同的語言來編碼的。
擴展
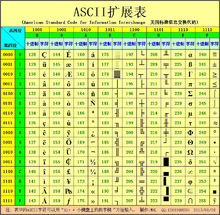 ASCII擴展表
ASCII擴展表1981年IBM PC ROM256個字元的字元集,即IBM擴展字元集。
1985年11 Windows字元集被稱作“ANSI字元集”,遵循了ANSI草案和ISO標準(ANSI/ISO8859-1-1987,簡“Latin 1”。ANSI字元集的最初版本:
1987年4月代碼頁437,字元的映像代碼,出現在MS-DOS3.3。
擴展ASCII 字元是從128 到255(0x80-0xff)的字元。
擴展ASCII不再是國際標準。
雙位元組
雙位元組字元集(DBCS:double-bytecharacterset),解決中國、日本和韓國的象形文字元和ASCII的某種兼容性。
DBCS從256代碼開始,就像ASCII一樣。與任何行為良好的代碼頁一樣,最初的128個代碼是ASCII。
然而,較高的128個代碼中的某些總是跟隨著第二個位元組。
這兩個位元組一起(稱作首位元組和跟隨位元組)定義一個字元,通常是一個複雜的象形文字。
虛擬值
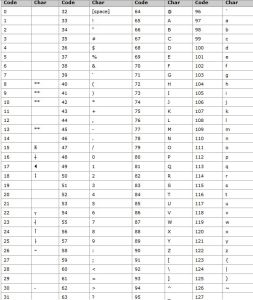 ASCII
ASCIIESC鍵VK_ESCAPE(27)
回車鍵:VK_RETURN(13)
TAB鍵:VK_TAB(9)
CapsLock鍵:VK_CAPITAL(20)
Shift鍵:VK_SHIFT(16)
Ctrl鍵:VK_CONTROL(17)
Alt鍵:VK_MENU(18)
空格鍵:VK_SPACE(32)
退格鍵:VK_BACK(8)
左徽標鍵:VK_LWIN(91)
右徽標鍵:VK_RWIN(92)
滑鼠右鍵快捷鍵:VK_APPS(93)
Insert鍵:VK_INSERT(45)
Home鍵:VK_HOME(36)
PageUp:VK_PRIOR(33)
PageDown:VK_NEXT(34)
End鍵:VK_END(35)
Delete鍵:VK_DELETE(46)
方向鍵(←):VK_LEFT(37)
方向鍵(↑):VK_UP(38)
方向鍵(→):VK_RIGHT(39)
方向鍵(↓):VK_DOWN(40)
F1鍵:VK_F1(112)
F2鍵:VK_F2(113)
F3鍵:VK_F3(114)
F4鍵:VK_F4(115)
F5鍵:VK_F5(116)
F6鍵:VK_F6(117)
F7鍵:VK_F7(118)
F8鍵:VK_F8(119)
F9鍵:VK_F9(120)
F10鍵:VK_F10(121)
F11鍵:VK_F11(122)
F12鍵:VK_F12(123)
NumLock鍵:VK_NUMLOCK(144)
小鍵盤0:VK_NUMPAD0(96)
小鍵盤1:VK_NUMPAD1(97)
小鍵盤2:VK_NUMPAD2(98)
小鍵盤3:VK_NUMPAD3(99)
小鍵盤4:VK_NUMPAD4(100)
小鍵盤5:VK_NUMPAD5(101)
小鍵盤6:VK_NUMPAD6(102)
小鍵盤7:VK_NUMPAD7(103)
小鍵盤8:VK_NUMPAD8(104)
小鍵盤9:VK_NUMPAD9(105)
小鍵盤。:VK_DECIMAL(110)
小鍵盤*:VK_MULTIPLY(106)
小鍵盤+:VK_ADD(107)
小鍵盤-:VK_SUBTRACT(109)
小鍵盤/:VK_DIVIDE(111)
PauseBreak鍵:VK_PAUSE(19)
ScrollLock鍵:VK_SCROLL(145)
編程相關
Pascal
取得ASCII碼:Ord(ch)
得到對應字元:Chr(n)
VisualBasic
取得ASCII碼:Asc(ch)
得到對應字元:Chr(n)
PCLOGO編程
取得ASCII碼:asc(某個字元,如大寫的A)(輸出答案:65)
代碼算法
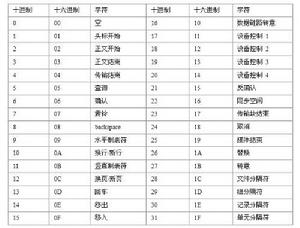 ASCII非列印控制字元表
ASCII非列印控制字元表在ascii中定義為01000001,也就是十進制65,有了這個標準後,當我們輸入A時,計算機就可以通過ascii碼知道輸入的字元的二進制編碼是01000001。而沒有這樣的標準,我們就必須自己想辦法告訴計算機我們輸入了一個A;沒有這樣的標準,我們在別的機器上就需要重新編碼以告訴計算機我們要輸入A。ascii碼指的不是十進制,是二進制。只是用十進制表示習慣一點罷了,比如在ascii碼中,A的二進制編碼為01000001,如果用十進制表示是65,用十六進制表示就是41H。
在ascii碼錶中,只包括了一些字元、數字、標點符號的信息表示,這主要是因為計算機是美國發明的,在英文下面,我們使用ascii表示就足夠了!但是在漢字輸入下面,用ascii碼就不能表示了,而漢字只是中國的通用表示,所以如果我們要在計算機中輸入漢字,就必須有一個像ascii碼的標準來表示每一個漢字,這就是中國的漢字國標碼,它定義了漢字在計算機中的一個表示標準。通過這個標準,但我們輸入漢字的時候,我們的輸入碼就轉換為區位碼,通過唯一的區位碼得到這個漢字的字形碼並顯示出來。當然漢字的區位碼在計算機中也是用二進制表示的。
一、二進制數轉換為十進制數
二進制數第0位的權值是2的0次方,第1位的權值是2的1次方……
所以,設有一個二進制數:0110 0100,轉換為10進制為:
下面是豎式:
0110 0100 換算成 十進制
第0位 0 * 20 = 0
第1位 0 * 21 = 0
第2位 1 * 22 = 4
第3位 0 * 23 = 0
第4位 0 * 24 = 0
第5位 1 * 25 = 32
第6位 1 * 26 = 64
第7位 0 * 27 = 0
用橫式計算為:
0 * 20 + 0 * 21 + 1 * 22 + 1 * 23 + 0 * 24 + 1 * 25 + 1 * 26 + 0 * 27 = 100
0乘以多少都是0,所以我們也可以直接跳過值為0的位:
1 * 22 + 1 * 23 + 1 * 25 + 1 * 26 = 100
二、八進制數轉換為十進制數
八進制就是逢8進1。
八進制數採用 0~7這八數來表達一個數。
八進制數第0位的權值為8的0次方,第1位權值為8的1次方,第2位權值為8的2次方……
所以,設有一個八進制數:1507,轉換為十進制為:
用豎式表示:
1507換算成十進制。
第0位 7 * 80 = 7
第1位 0 * 81 = 0
第2位 5 * 82 = 320
第3位 1 * 83 = 512
同樣,我們也可以用橫式直接計算:
7 * 80 + 0 * 81 + 5 * 82 + 1 * 83 = 839
結果是,八進制數 1507 轉換成十進制數為 839
八進制數的表達方法
C,C++語言中,如何表達一個八進制數呢?如果這個數是 876,我們可以斷定它不是八進制數,因為八進制數中不可能出7以上的阿拉伯數字。但如果這個數是123、是567,或12345670,那么它是八進制數還是10進制數,都有可能。
所以,C,C++規定,一個數如果要指明它採用八進制,必須在它前面加上一個0,如:123是十進制,但0123則表示採用八進制。這就是八進制數在C、C++中的表達方法。
由於C和C++都沒有提供二進制數的表達方法,所以,這裡所學的八進制是我們學習的,CtC++語言的數值表達的第二種進制法。
現在,對於同樣一個數,比如是100,我們在代碼中可以用平常的10進制表達,例如在變數初始化時:
int a = 100;
我們也可以這樣寫:
int a = 0144; //0144是八進制的100;一個10進制數如何轉成8進制,我們後面會學到。
千萬記住,用八進制表達時,你不能少了最前的那個0。否則計算機會通通當成10進制。不過,有一個地方使用八進制數時,卻不能使用加0,那就是我們前面學的用於表達字元的“轉義符”表達法。
八進制數在轉義符中的使用
我們學過用一個轉義符'\'加上一個特殊字母來表示某個字元的方法,如:'\n'表示換行(line),而'\t'表示Tab字元,'\''則表示單引號。今天我們又學習了一種使用轉義符的方法:轉義符'\'後面接一個八進制數,用於表示ASCII碼等於該值的字元。
比如,查一下第5章中的ASCII碼錶,我們找到問號字元(?)的ASCII值是63,那么我們可以把它轉換為八進值:77,然後用 '\77'來表示'?'。由於是八進制,所以本應寫成 '\077',但因為C,C++規定不允許使用斜槓加10進制數來表示字元,所以這裡的0可以不寫。
事實上我們很少在實際編程中非要用轉義符加八進制數來表示一個字元,所以,6。2。4小節的內容,大家僅僅了解就行。
十六進制數轉換成十進制數
2進制,用兩個阿拉伯數字:0、1;
8進制,用八個阿拉伯數字:0、1、2、3、4、5、6、7;
10進制,用十個阿拉伯數字:0到9;
16進制,用十六個阿拉伯數字……等等,阿拉伯人或說是印度人,只發明了10個數字啊?
16進制就是逢16進1,但我們只有0~9這十個數字,所以我們用A,B,C,D,E,F這五個字母來分別表示10,11,12,13,14,15。字母不區分大小寫。
十六進制數的第0位的權值為16的0次方,第1位的權值為16的1次方,第2位的權值為16的2次方
所以,在第N(N從0開始)位上,如果是是數 X (X 大於等於0,並且X小於等於 15,即:F)表示的大小為 X * 16的N次方。
假設有一個十六進數 2AF5, 那么如何換算成10進制呢
用豎式計算:
2AF5換算成10進制:
第0位: 5 * 160 = 5
第1位: F * 161 = 240
第2位: A * 162 = 2560
第3位: 2 * 163 = 8192
 ASCII
ASCII直接計算就是:
5 * 160 + F * 161 + A * 162 + 2 * 163 = 10997
(別忘了,在上面的計算中,A表示10,而F表示15)
現在可以看出,所有進制換算成10進制,關鍵在於各自的權值不同。
假設有人問你,十進數 1234 為什麼是 一千二百三十四?你盡可以給他這么一個算式:
1234 = 1 * 103 + 2 * 102 + 3 * 101 + 4 * 100
十六進制數的表達方法
如果不使用特殊的書寫形式,16進制數也會和10進制相混。隨便一個數:9876,就看不出它是16進制或10進制。
C,C++規定,16進制數必須以 0x開頭。比如 0x1表示一個16進制數。而1則表示一個十進制。另外如:0xff,0xFF,0X102A,等等。其中的x也也不區分大小寫。(注意:0x中的0是數字0,而不是字母O)
以下是一些用法示例:
int a = 0x100F;
int b = 0x70 + a;
至此,我們學完了所有進制:10進制,8進制,16進制數的表達方式。最後一點很重要,C/C++中,10進制數有正負之分,比如12表示正12,而-12表示負12,;但8進制和16進制只能用達無符號的正整數,如果你在代碼中里:-078,或者寫:-0xF2,C,C++並不把它當成一個負數。
十六進制數在轉義符中的使用
轉義符也可以接一個16進制數來表示一個字元。如在6。2。4小節中說的 '?' 字元,可以有以下表達方式:
'?' //直接輸入字元
'\77' //用八進制,此時可以省略開頭的0
'\0x3F' //用十六進制
同樣,這一小節只用於了解。除了空字元用八進制數 '\0' 表示以外,我們很少用後兩種方法表示一個字元。
三、十進制數轉換到二、八、十六進制數
進制數轉換為2進制數
給你一個十進制,比如:6,如果將它轉換成二進制數呢?
10進制數轉換成二進制數,這是一個連續除2的過程:
把要轉換的數,除以2,得到商和餘數,
將商繼續除以2,直到商為0。最後將所有餘數倒序排列,得到數就是轉換結果。
聽起來有些糊塗?我們結合例子來說明。比如要轉換6為二進制數。
“把要轉換的數,除以2,得到商和餘數”。
那么:
要轉換的數是6, 6 ÷ 2,得到商是3,餘數是0。 (不要告訴我你不會計算6÷3!)
“將商繼續除以2,直到商為0……”
現在商是3,還不是0,所以繼續除以2。
那就: 3 ÷ 2, 得到商是1,餘數是1。
“將商繼續除以2,直到商為0……”
現在商是1,還不是0,所以繼續除以2。
那就: 1 ÷ 2, 得到商是0,餘數是1 (拿筆紙算一下,1÷2是不是商0餘1!)
“將商繼續除以2,直到商為0……最後將所有餘數倒序排列”
好極!現在商已經是0。
我們三次計算依次得到餘數分別是:0、1、1,將所有餘數倒序排列,那就是:110了!
6轉換成二進制,結果是110。
把上面的一段改成用表格來表示,則為:
被除數 計算過程 商 餘數
6 6/2 3 0
3 3/2 1 1
1 1/2 0 1
(在計算機中,÷用 / 來表示)
如果是在考試時,我們要畫這樣表還是有點費時間,所更常見的換算過程是使用下圖的連除:
(圖:1)
請大家對照圖,表,及文字說明,並且自已拿筆計算一遍如何將6轉換為二進制數。
說了半天,我們的轉換結果對嗎?二進制數110是6嗎?你已經學會如何將二進制數轉換成10進制數了,所以請現在就計算一下110換成10進制是否就是6。
6。3。2 10進制數轉換為8、16進制數
非常開心,10進制數轉換成8進制的方法,和轉換為2進制的方法類似,惟一變化:除數由2變成8。
來看一個例子,如何將十進制數120轉換成八進制數。
用表格表示:
被除數 計算過程 商 餘數
120 120/8 15 0
15 15/8 1 7
1 1/8 0 1
120轉換為8進制,結果為:170。
非常非常開心,10進制數轉換成16進制的方法,和轉換為2進制的方法類似,惟一變化:除數由2變成16。
同樣是120,轉換成16進制則為:
被除數 計算過程 商 餘數
120 120/16 7 8
7 7/16 0 7
120轉換為16進制,結果為:78。
請拿筆紙,採用(圖:1)的形式,演算上面兩個表的過程。
四、十六進制數互相轉換
二進制和十六進制的互相轉換比較重要。不過這二者的轉換卻不用計算,每個C,C++程式設計師都能做到看見二進制數,直接就能轉換為十六進制數,反之亦然。
我們也一樣,只要學完這一小節,就能做到。
首先我們來看一個二進制數:1111,它是多少呢?
你可能還要這樣計算:1 * 20 + 1 * 21 + 1 * 22 + 1 * 23 = 1 * 1 + 1 * 2 + 1 * 4 + 1 * 8 = 15。
然而,由於1111才4位,所以我們必須直接記住它每一位的權值,並且是從高位往低位記,:8、4、2、1。即,最高位的權值為23 = 8,然後依次是 22 = 4,21=2, 20 = 1。
記住8421,對於任意一個4位的二進制數,我們都可以很快算出它對應的10進制值。
下面列出四位二進制數 xxxx 所有可能的值(中間略過部分)
僅4位的2進制數 快速計算方法 十進制值 十六進值
1111 = 8 + 4 + 2 + 1 = 15 F
1110 = 8 + 4 + 2 + 0 = 14 E
1101 = 8 + 4 + 0 + 1 = 13 D
1100 = 8 + 4 + 0 + 0 = 12 C
1011 = 8 + 4 + 0 + 1 = 11 B
1010 = 8 + 0 + 2 + 0 = 10 A
1001 = 8 + 0 + 0 + 1 = 10 9
。。。。
0001 = 0 + 0 + 0 + 1 = 1 1
0000 = 0 + 0 + 0 + 0 = 0 0
二進制數要轉換為十六進制,就是以4位一段,分別轉換為十六進制。
如(上行為二制數,下面為對應的十六進制):
1111 1101 , 1010 0101 , 1001 1011
F D , A 5 , 9 B
反過來,當我們看到 FD時,如何迅速將它轉換為二進制數呢?
先轉換F:
看到F,我們需知道它是15(可能你還不熟悉A~F這五個數),然後15如何用8421湊呢?應該是8 + 4 + 2 + 1,所以四位全為1 :1111。
接著轉換 D:
看到D,知道它是13,13如何用8421湊呢?應該是:8 + 4 + 1,即:1101。
所以,FD轉換為二進制數,為: 1111 1101
由於十六進制轉換成二進制相當直接,所以,我們需要將一個十進制數轉換成2進制數時,也可以先轉換成16進制,然後再轉換成2進制。
比如,十進制數 1234轉換成二制數,如果要一直除以2,直接得到2進制數,需要計算較多次數。所以我們可以先除以16,得到16進制數:
 ASCII
ASCII被除數 計算過程 商 餘數
1234 1234/16 77 2
77 77/16 4 13 (D)
4 4/16 0 4
結果16進制為: 0x4D2
然後我們可直接寫出0x4D2的二進制形式: 0100 1011 0010。
其中對映關係為:
0100 -- 4
1011 -- D
0010 -- 2
同樣,如果一個二進制數很長,我們需要將它轉換成10進制數時,除了前面學過的方法是,我們還可以先將這個二進制轉換成16進制,然後再轉換為10進制。
下面舉例一個int類型的二進制數:
01101101 11100101 10101111 00011011
我們按四位一組轉換為16進制: 6D E5 AF 1B
漢字編碼
0-127 是 7位ASCII 碼的範圍,是國際標準。
至於漢字,不同的字元集用的ascii 碼的範圍也不一樣,常用的漢字字元集有GB2312-80,GBK,
Big5,unicode 等。下面我重點說一說最常用的GB_2312 的字元集。
GB_2312 字元集是目前最常用的漢字編碼標準,windows 95/98/2000 中使用的 GBK字元集 就包含了GB2312,或者說和GB2312 兼容,GB_2312 字元集包含了 6763個的 簡體漢字,和682 個標準中文符號。在這個標準中,每個漢字用2個位元組來表示,每個位元組的ascii碼為 161-254 (16 進制A1 - FE),第一個位元組 對應於 區碼的1-94 區,第二個位元組 對應於位碼的1-94 位。
161-254 其實很好記憶,大家知道英文字元中,可列印的字元範圍為33-126。將 這對 數加上
128(或者說最高位置1),就得到漢字使用的字元的範圍。
//GB18030的規範是漢字第一個位元組在0x81-0xFE之間,第二個位元組位於區間0x40-0x7E以及0x80-0xFE。每個位元組轉化為整數大於128。
if ((char_temp>=0x81)&&(char_temp<=0xFE))
{
if(*len
{
*len+=1;
*p_temp++=char_temp;
_putch(char_temp);
x++;
}
}
進位制表
| 八進制 | 十六進制 | 十進制 | 字元 | 八進制 | 十六進制 | 十進制 | 字元 |
| 0 | 0 | 0 | nul | 100 | 40 | 64 | @ |
| 1 | 1 | 1 | soh | 101 | 41 | 65 | A |
| 2 | 2 | 2 | stx | 102 | 42 | 66 | B |
| 3 | 3 | 3 | etx | 103 | 43 | 67 | C |
| 4 | 4 | 4 | eot | 104 | 44 | 68 | D |
| 5 | 5 | 5 | enq | 105 | 45 | 69 | E |
| 6 | 6 | 6 | ack | 106 | 46 | 70 | F |
| 7 | 7 | 7 | bel | 107 | 47 | 71 | G |
| 10 | 8 | 8 | bs | 110 | 48 | 72 | H |
| 11 | 9 | 9 | ht | 111 | 49 | 73 | I |
| 12 | 0a | 10 | nl | 112 | 4a | 74 | J |
| 13 | 0b | 11 | vt | 113 | 4b | 75 | K |
| 14 | 0c | 12 | ff | 114 | 4c | 76 | L |
| 15 | 0d | 13 | cr | 115 | 4d | 77 | M |
| 16 | 0e | 14 | so | 116 | 4e | 78 | N |
| 17 | 0f | 15 | si | 117 | 4f | 79 | O |
| 20 | 10 | 16 | dle | 120 | 50 | 80 | P |
| 21 | 11 | 17 | dc1 | 121 | 51 | 81 | Q |
| 22 | 12 | 18 | dc2 | 122 | 52 | 82 | R |
| 23 | 13 | 19 | dc3 | 123 | 53 | 83 | S |
| 24 | 14 | 20 | dc4 | 124 | 54 | 84 | T |
| 25 | 15 | 21 | nak | 125 | 55 | 85 | U |
| 26 | 16 | 22 | syn | 126 | 56 | 86 | V |
| 27 | 17 | 23 | etb | 127 | 57 | 87 | W |
| 30 | 18 | 24 | can | 130 | 58 | 88 | X |
| 31 | 19 | 25 | em | 131 | 59 | 89 | Y |
| 32 | 1a | 26 | sub | 132 | 5a | 90 | Z |
| 33 | 1b | 27 | esc | 133 | 5b | 91 | [ |
| 34 | 1c | 28 | fs | 134 | 5c | 92 | \ |
| 35 | 1d | 29 | gs | 135 | 5d | 93 | ] |
| 36 | 1e | 30 | re | 136 | 5e | 94 | ^ |
| 37 | 1f | 31 | us | 137 | 5f | 95 | _ |
| 40 | 20 | 32 | sp | 140 | 60 | 96 | ' |
| 41 | 21 | 33 | ! | 141 | 61 | 97 | a |
| 42 | 22 | 34 | " | 142 | 62 | 98 | b |
| 43 | 23 | 35 | # | 143 | 63 | 99 | c |
| 44 | 24 | 36 | $ | 144 | 64 | 100 | d |
| 45 | 25 | 37 | % | 145 | 65 | 101 | e |
| 46 | 26 | 38 | & | 146 | 66 | 102 | f |
| 47 | 27 | 39 | ` | 147 | 67 | 103 | g |
| 50 | 28 | 40 | ( | 150 | 68 | 104 | h |
| 51 | 29 | 41 | ) | 151 | 69 | 105 | i |
| 52 | 2a | 42 | * | 152 | 6a | 106 | j |
| 53 | 2b | 43 | + | 153 | 6b | 107 | k |
| 54 | 2c | 44 | , | 154 | 6c | 108 | l |
| 55 | 2d | 45 | - | 155 | 6d | 109 | m |
| 56 | 2e | 46 | . | 156 | 6e | 110 | n |
| 57 | 2f | 47 | / | 157 | 6f | 111 | o |
| 60 | 30 | 48 | 0 | 160 | 70 | 112 | p |
| 61 | 31 | 49 | 1 | 161 | 71 | 113 | q |
| 62 | 32 | 50 | 2 | 162 | 72 | 114 | r |
| 63 | 33 | 51 | 3 | 163 | 73 | 115 | s |
| 64 | 34 | 52 | 4 | 164 | 74 | 116 | t |
| 65 | 35 | 53 | 5 | 165 | 75 | 117 | u |
| 66 | 36 | 54 | 6 | 166 | 76 | 118 | v |
| 67 | 37 | 55 | 7 | 167 | 77 | 119 | w |
| 70 | 38 | 56 | 8 | 170 | 78 | 120 | x |
| 71 | 39 | 57 | 9 | 171 | 79 | 121 | y |
| 72 | 3a | 58 | : | 172 | 7a | 122 | z |
| 73 | 3b | 59 | ; | 173 | 7b | 123 | { |
| 74 | 3c | 60 | < | 174 | 7c | 124 | | |
| 75 | 3d | 61 | = | 175 | 7d | 125 | } |
| 76 | 3e | 62 | > | 176 | 7e | 126 | ~ |
| 77 | 3f | 63 | ? | 177 | 7f | 127 | del |
