概覽
 基於GF100的GeForce GTX 480
基於GF100的GeForce GTX 480詳細規格參數
| 構架代號 | Fermi |
| 核心代號 | GF100 |
| 電晶體數量 | 32億 |
| 對應桌面顯示卡型號 | GeForce GTX480(核心編號GF100-375) GeForce GTX470(核心編號GF100-275) GeForce GTX465(核心編號GF100-030) |
| GPC數量/GPU | 4 |
| SM數量/GPU | 15(GeForce GTX480) 14(GeForce GTX470) 11(GeForce GTX465) |
| CUDA核心數量/SM | 32 |
| CUDA核心數量/GPU | 480(GeForce GTX480) 448(GeForce GTX470) 352(GeForce GTX465) |
| Flops | 2.02 TFLOPS(GeForce GTX480) 1.63 TFlops(GeForce GTX470) 1.28 TFlops(GeForce GTX465) |
| TMU(TA / TF)/SM | 4 |
| TMU(TA / TF)/GPU | 60(GeForce GTX480) 56(GeForce GTX470) 44(GeForce GTX465) |
| tessellation引擎 | 15(GeForce GTX480) 14(GeForce GTX470) 11(GeForce GTX465) |
| L1 Cache/SM | 64KB |
| L1 Cache/GPU | 960KB(GeForce GTX480) 896KB(GeForce GTX470) 704KB(GeForce GTX465) |
| L2 Cache/GPU | 768KB |
| ROP陣列數量 | 6(GeForce GTX480) 5(GeForce GTX470) 4(GeForce GTX465) |
| ROP數量/ROP陣列 | 8 |
| ROP數量/GPU | 48(GeForce GTX480) 40(GeForce GTX470) 32(GeForce GTX465) |
| MC數量 | 6(GeForce GTX480) 5(GeForce GTX470) 4(GeForce GTX465) |
| 位寬/MC | 64Bit |
| 位寬/GPU | 384Bit(GeForce GTX480) 320Bit(GeForce GTX470) 256Bit(GeForce GTX465) |
| 核心頻率 | 701MHz(GeForce GTX480) 607MHz(GeForce GTX470) 607MHz(GeForce GTX465) |
| CUDA核心頻率 | 1401MHz(GeForce GTX480) 1215MHz(GeForce GTX470) 1215MHz(GeForce GTX465) |
| 搭配的顯存頻率 | 3696MHz(GeForce GTX480) 3348MHz(GeForce GTX470) 3206MHz(GeForce GTX465) |
| 顯存頻寬 | 177.4 GB/s(GeForce GTX480) 133.9 GB/s(GeForce GTX470) 102.6 GB/s(GeForce GTX465) |
| 顯存容量 | 1.5 GB(GeForce GTX480) 1.2 GB/s(GeForce GTX470) 1 GB/s(GeForce GTX465) |
| 紋理填充率 | 42.0 Billion/s(GeForce GTX480) 34.0 Billion/s(GeForce GTX470) 26.7 Billion/s(GeForce GTX465) |
| OpenGL支持 | 4.2 (需要280.28版本驅動支持) |
| 接口 | PCI-E 16X 2.0 |
| 特性支持 | DirectX 11, 3D Vision, CUDA, PhysX, DirectComput |
| CUDA版本 | 2.0 |
| 最大數字解析度 | 2560x1600 |
| 最大VGA解析度 | 2048x1536 |
| 高位寬數字內容保護(HDCP) | 支持 |
| 高清多媒體介面(HDMI) | 支持 |
| GPU內建HDMI音頻輸出 | 支持 |
| 顯示器接口支持 | HDMI, VGA (可選), Mini HDMI, Dual Link DVI |
| GPU最高溫度 | 100 C |
| 供電接口 | 8Pin + 6Pin(GeForce GTX480) 6Pin + 6Pin(GeForce GTX470) 6Pin + 6Pin(GeForce GTX465) |
| 滿載最大功耗 | 250W(GeForce GTX480) 215W(GeForce GTX470) 200W(GeForce GTX465) |
| 最小系統功耗需求 | 600W(GeForce GTX480) 550W(GeForce GTX470) 550W(GeForce GTX465) |
核心組成
GPU層級 完整的GF100構架
完整的GF100構架GPC囊括了所有主要的圖形處理單元,可以被看作是一個自給自足的GPU,而一顆GF100擁有四個GPC,每個GPC中包含1個Raster引擎,4個SM。
SM層級每個SM主要包含2個Warp調度器,2個指令分派單元,32個CUDA核心,16個LD/ST單元,4個SFU,64K Shared Memory + L1 Cache(按需配置大小),4個紋理單元,1個多邊形引擎。
ROP層級每個光柵化陣列包含8個ROP。每個GF100含有6個光柵化陣列。
小結每個完整的GF100包含:512個CUDA核心(SP),64個紋理單元,16個多邊形引擎,1024KB L1 Cache,768KB L2 Cache,48個ROP,384Bit的GDDR5顯存控制器。
構架解析
改進的SP和SM GF100的SM結構
GF100的SM結構最核心的流處理器(Streaming Processor/SP)現在不但數量大增,還有了個新名字CUDA核心(CUDA Core),由此即可看出NVIDIA的轉型之意,不過我們暫時還是繼續沿用流處理器的說法。
所有流處理器現在都符合IEEE 754-2008浮點算法(Cypress也是如此)和完整的32位整數算法,而後者在過去只是模擬的,事實上僅能計算24-bit整數乘法;同時引入的還有積和熔加運算(Fused Multiply-Add/FMA),每循環運算元單精度512個、單精度256個。所有一切都符合業界標準,計算結果不會產生意外偏差。
雙精度浮點(FP64)性能大大提升,峰值執行率可以達到單精度浮點(FP32)的1/2,而過去只有1/8,AMD現在也不過1/5,比如Radeon HD 5870分別為單精度2.72TFlops、雙精度544GFlops。由於最終核心頻率未定,所以暫時還不清楚Fermi的具體浮點運算能力(雙精度預計可達624GFlops)。
G80/GT200都是8個流處理器構成一組SM(StreamingMultiprocessor),Fermi增加到了32個,最多16組,少於GT200的30組,但流處理器總量從240個增至512個,是G80的整整四倍。
除了流處理器,每組SM還有4個特殊功能單元(Special Function UnitSFU),用於執行抽象數學和插值計算,G80/GT200均為2個。同時MUL已被刪掉,所以不會再有單/雙指令執行計算率了。
至於SM之上的紋理處理器群(Texture Processor Cluster/TPC),NVIDIA暫時沒有披露具體組成方式,而且ROP單元、紋理/像素填充率等其它圖形指標也未公布。全新的Tessellation引擎
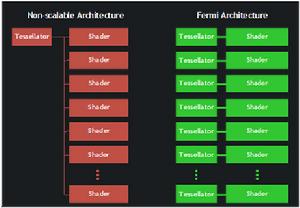 GF100的Tessellation單元的特點
GF100的Tessellation單元的特點Tessellation(曲面細分)的使用從根本上改變了GPU圖形負荷的平衡。憑藉Tessellation(曲面細分),特定幀中的三角形密度能夠增加數十倍,但這給設定於光柵化單元等串列工作的資源帶來了巨大壓力。為了保持較高的Tessellation(曲面細分)性能,有必要重新平衡圖形計算流水線。全新的Raster引擎
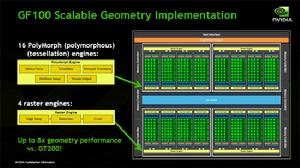
在Polymorph引擎處理完基元之後,它們就被被傳送至光柵(Raster)引擎。為了實現較高的三角形吞吐量,GF100採用四個Raster引擎並行工作的方式。
Raster引擎由三個流水線階段組成。在邊緣設定階段中,可提取頂點位置、計算三角形邊緣方程。沒有朝向螢幕方向的三角形都通過背面剔除而刪掉了。每一個邊緣設定單元在一個時鐘周期中最多都能夠處理一個點、線或三角形。
光柵器(Rasterizer)為每一個基元而運行邊緣方程並計算像素的覆蓋。如果開啟了抗鋸齒功能,那么就會為每一個多採樣以及覆蓋採樣執行覆蓋操作。每一個光柵器在每個時鐘周期內均可輸出8個像素,整個晶片每個時鐘周期內總共可輸出32個光柵化的像素。
光柵器所生成的像素將被傳送至Z坐標壓縮(Z-cull)單元。Z坐標壓縮單元獲取像素圖塊(Pixel Tile)並將圖塊中像素的深度與顯存中的現有像素進行比較。完全處於顯存像素後面的像素圖塊將從流水線中剔除,從而就不再需要進一步的像素著色工作了。
 Tessellation和Raster引擎
Tessellation和Raster引擎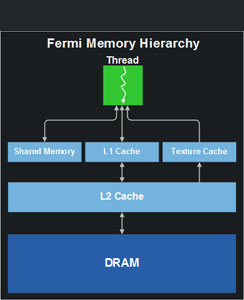 GF100的Cache
GF100的CacheGT200的每組TPC還有一個一級紋理快取,不過當GPU出於計算模式的時候就沒什麼用了,故而Fermi並未在這方面進行增強。
整個晶片擁有一個容量768KB的共享二級快取,執行原子記憶體操作(AMO)的時候比GT200快5-20倍。改進的渲染輸出單元
Fermi的渲染輸出 (ROP) 子系統能夠實現更大吞吐量以及更高效率。 一個Fermi ROP分區包含8個ROP單元,是GT200架構的2倍,並改進了單個ROP的性能。 8倍抗鋸齒這一操作在上一代GPU上運行起來非常吃力,而Fermi構架的性能損失則小得多。
此外,Fermi還支持32倍覆蓋採樣抗鋸齒 (CSAA),這種抗鋸齒模式的計算負荷高於任何其它GPU上的採樣抗鋸齒模式,能呈現出更加平滑的幾何圖形邊緣。
CPU和GPU執行的都是被稱作執行緒的指令流。高端CPU現在每次最多只能執行8個執行緒(Intel Core i7),而GPU的並行計算能力就強大多了:G80 12288個、GT200 30720個、Fermi 24576個。
為什麼Fermi還不如GT200多?因為NVIDIA發現計算的瓶頸在於共享記憶體大小,而不是執行緒數,所以前者從16KB翻兩番達到64KB,後者則減少了20%,不過依然是G80的兩倍,而且每32個執行緒構成一組“Warp”。
在G80和GT200上,每個時鐘周期只有一半Warp被送至SM,換言之SM需要兩個循環才能完整執行32個執行緒;同時SM分配邏輯和執行硬體緊密聯繫在一起,向SFU傳送執行緒的時候整個SM都必須等待這些執行緒執行完畢,嚴重影響整體效率。
Fermi解決了這個問題,在每個SM前端都有兩個Warp調度器和兩個獨立分配單元,並且和SM其它部分完全獨立,均可在一個時鐘循環里選擇傳送一半Warp,而且這些執行緒可以來自不同的Warp。分配單元和執行硬體之間有一個完整的交叉開關(crossbar),每個單元都可以像SM內的任何單元分配執行緒(不過存在一些限制)。
這種執行緒架構也不是沒有缺點,就是要求Warp的每個執行緒都必須同時執行同樣的指令,否則會有部分單元空閒。每組SM每個循環內可以執行的不同運算元:FP32 32個、FP64 16個、INT 32個、SFU 4個、LD/ST 16個。
在GPU編程術語中,核心是運行在GPU硬體上的一個功能或小程式。G80/GT200整個晶片每次只能執行一個核心,容易造成SM單元閒置。這在圖形運算中不是問題,通用計算上就不行了。
Fermi的全局分配邏輯則可以向整個系統傳送多個並行核心,不然SP數量翻一番還多,更容易浪費。
應用程式在GPU和CUDA模式之間的切換時間也快得多了,NVIDIA宣稱是GT200的10倍。外部連線亦有改進,Fermi現在支持和CPU之間的並行傳輸,而之前都是串列的。
AMD Cypress可以檢測記憶體匯流排上的錯誤,卻不能修正,而NVIDIAFermi的暫存器檔案、一級快取、二級快取、DRAM全部完整支持ECC錯誤校驗,這同樣是為Tesla準備的,之前我們也提到過。
很多客戶此前就是因為Tesla沒有ECC才拒絕採納,因為他們的安裝量非常龐大,必須有ECC。
以前的架構里多種不同載入指令,取決於記憶體類型:本地(每執行緒)、共享(每組執行緒)、全局(每核心)。這就和指針造成了麻煩,程式設計師不得不費勁清理。
Fermi統一了定址空間,簡化為一種指令,記憶體地址取決於存儲位置:最低位是本地,然後是共享,剩下的是全局。這種統一定址空間是支持C++的必需前提。
GT80/GT200的定址空間都是32-bit的,最多搭配4GBGDDR3顯存,而Fermi一舉支持64-bit定址,即使實際定址只有40-bit,支持顯存容量最多也可達驚人的1TB,目前實際配置最多6GB GDDR5——仍是Tesla。
下邊對開發人員來說是非常酷的:NVIDIA宣布了一個名為“Nexus”的外掛程式,可以在Visual Studio里執行CUDA代碼的硬體調試,相當於把GPU當成CPU看待,難度大大降低。
Fermi的指令集架構大大擴充,支持DX11和OpenCL義不容辭,C++前邊也已經說過,現在又多了VisualStudio,當然還有C、Fortran、OpenGL 3.1/3.2。
性能等級
綜合性能介於GeForce GTX 570和GeForce GTX 580之間。得益於1.5G的顯存容量,在一些高負載且高解析度高AA的遊戲以及畫質設定下,較GeForce GTX 570 1.2G的顯存容量,GeForce GTX 480更不容易出現因顯存不夠導致的FPS急速下降的情況。
綜合性能強於AMD Radeon HD6950 2GB,與AMD Radeon HD 6970 2GB伯仲之間。
高清性能
支持藍光3D
通過HDMI 1.4接口,在所有兼容的3D播放系統上均無縫支持1080p藍光3D光碟,讓用戶在家中即可欣賞影院級畫質的3D電影。兼容的3D觀看系統包含主動快門式眼鏡以及被動偏光顯示器。
硬體視頻解碼加速
本技術集高清視頻解碼加速與後期處理於一身,能夠在播放電影和視頻時實現前所未有的畫面清晰度、流暢的視頻、準確的顏色以及精確的圖像縮放。
支持TrueHD和DTS-HD音頻比特流
完全支持TrueHD與DTS-HD高級無損多聲道高清音頻編解碼器。
HDMI輸出
支持HDMI 1.4輸出接口,讓顯示卡只用一根電纜即可將高清視頻與音頻信號都傳送至高畫質電視。
支持雙鏈路DVI
關於GF100首發即缺失一組SM
因TSMC的40nm工藝問題,以及GF100的龐大規模造成的低下良品率,使得nVIDIA不得不通過禁止一組SM來保證產量,造成了GF100首發規格的不完整:只有480SP,而不是設計之初的512SP。另一種說法是nVIDIA因GF100過高的發熱和功耗問題而不得不通過禁止一組SM來緩解這些問題。
而最直接的,對於採用量產版GF100核心的GeForce GTX 480來說,在禁止一組SM後,就丟失了32SP,4個紋理單元和一個Tessellation引擎。
溫度和噪音
基於公版散熱的GF100顯示卡,待機時(接單個顯示器)溫度為45-55度之間(視機箱環境和環境溫度而定),散熱風扇轉速在1600RPM附近,此時非常安靜。
滿載工作時普遍會達到90-95度(視機箱環境和環境溫度而定),此時風扇轉速達到3500-4000RPM,噪音較大,但可被遊戲聲音所覆蓋。
