
什麼是Fermi
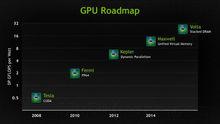 英偉達顯示卡架構路線圖
英偉達顯示卡架構路線圖GT200的14億個電晶體曾經讓我們驚嘆,Cypress的21.5億個相比RV770的9.56億個增加了一倍多,而Fermi達到了史無前例的30億個,同樣比自己的上一代翻了一番還多,比對手也多了40%。
從最高層面上說,Fermi很簡單,無非是512個流處理器,384-bit GDDR5顯存,而深層次的架構我們會在稍後逐一揭曉,不過Fermi至今還停留在紙面上,還不是一款真正的產品,所以型號劃分、時鐘頻率、售價等等都還沒有確定。事實上, 直到兩個月前NVIDIA才第一次讓人看到了樣品,最近不久剛剛獲得可以正常工作的晶片,正式發布至少要到2009年底,而全面上市就是2010年第一季度的事兒了。
Fermi為什麼這么晚?NVIDIA產品行銷副總裁Ujesh Desai說了一句: 因為設計這么大的GPU實在是太難了。
AMD用RV770核心給NVIDIA好好上了一課,龐大而沉重的GT200失去了反擊之力,CUDA、PhysX這種對手所沒有的功能特性於是成了宣傳重點。
作為GeForce業務負責人,Ujesh Desai願意承擔責任,並承認在GT200時代嚴重失策。根據RV670 Radeon HD 3800的表現,NVIDIA推測其繼任者的性能也不過爾爾,但RV770的表現大大出乎意料,而GT200定價過高,最終導致了一夜之間暴降千元的悲劇。
NVIDIAGPU工程副總裁Jonah Alben沒有把責任都推到Ujesh身上,承認自己在工程上也有失誤。GT300從一開始就應該採用新的55nm工藝,但NVIDIA在130nm NV30 GeForce FX被150nm Radeon 9700 Pro大敗之後趨於保守,最後一次使用了65nm工藝,最終成就了一個面積龐大、功耗超高的巨無霸。
雖然40nm工藝進程依然稍微落後於對手,但NVIDIA不會在同一條河裡摔倒兩次,沒有在Fermi上沿用55nm,否則又是一顆無法接受的大晶片。
不過NVIDIA暫時還沒有透露Fermi的具體大小,只能估計一下。 Fermi和Cypress都是40nm工藝,假設核心面積和電晶體數量呈等比例,那么在後者334平方毫米的基礎上,Fermi將是466平方毫米,比576平方毫米的GT200小足足兩成。
儘管AMD的Sweet Point策略讓NVIDIA吃盡了苦頭,不過 NVIDIA依然認為最重要的並非首先開發價格較低的小晶片,而是提高大晶片的效率,然後衍生出不同的尺寸和配置規格。期待Fermi的主流版本能在2010年儘快出爐。
NVIDIA相信Fermi在3D遊戲裡會比Radeon HD 5870更快,當然不快也不行,但是如果你只是把Fermi單純地看作是一顆遊戲GPU就錯了,因為 它的真正目標是Tesla,是高性能通用計算,是個人和數據中心超級計算機——這就是GT300裡邊那個字母T的含義,它要做一顆通用目的微處理器。
這有點兒像Intel Nehalem架構,確切目標也不是桌面,而是高性能計算伺服器領域,所以新的Xeon處理器才在伺服器工作站上橫掃一片,但遊戲性能並不比Core 2 Quad好多少。
NVIDIA聲稱,要達到同樣的性能,使用CPU就得2000台x86伺服器,總成本約800萬美元,功耗1200kW,而換成GPU只需32台Tesla S1070s系統(如下圖),成本不過40萬美元,功耗更是僅僅45kW。雖然這裡沒有算上驅動Tesla所需要的伺服器(畢竟GPU不可能完全擺脫CPU),但這部分占得也不會太多。
Fermi架構解析
1、SP、SM
從高層次上看,Fermi和GT200結構形似,並無太大不同,但往深處看就會發現絕大部分都已經進化。
 Fermi
Fermi最核心的流處理器(Streaming Processor/SP)數量大增,還有了個新名字CUDA核心(CUDA Core),由此即可看出NVIDIA的轉型之意,不過我們暫時還是繼續沿用流處理器的說法。
所有流處理器都符合 IEEE 754-2008浮點算法(Cypress也是如此)和 完整的32位整數算法,而後者在過去只是模擬的,事實上僅能計算24-bit整數乘法;同時引入的還有 積和熔加運算(Fused Multiply-Add/FMA),每循環運算元單精度512個、雙精度256個。所有一切都符合業界標準,計算結果不會產生意外偏差。
雙精度浮點(FP64)性能大大提升,峰值執行率可以達到單精度浮點(FP32)的1/2,而過去只有1/8,AMD也不過1/5,比如Radeon HD 5870分別為單精度2.72TFlops、雙精度544GFlops。由於最終核心頻率未定,所以暫時還不清楚Fermi的具體浮點運算能力(雙精度預計可達624GFlops)。
 Fermi
FermiG80/GT200都是8個流處理器構成一組SM(Streaming Multiprocessor),Fermi增加到了 32個,最多 16組,少於GT200的30組,但流處理器總量從240個增至512個,是G80的整整四倍。
除了流處理器,每組SM還有 4個特殊功能單元(Special Function UnitSFU),用於執行抽象數學和插值計算,G80/GT200均為2個。同時 MUL已被刪掉,所以不會再有單/雙指令執行計算率了。
至於SM之上的紋理處理器群(Texture Processor Cluster/TPC),NVIDIA暫時沒有披露具體組成方式,而且ROP單元、紋理/像素填充率等其它圖形指標也未公布。
2、快取
GT200的每組SM都有16KB共享記憶體,由其中8個SP使用。注意它們不是快取(cache),而是軟體管理的記憶體(memory),可以寫入、讀取數據。為了滿足應用程式和通用計算的需要, Fermi引入了真正的快取,每組SM擁有64KB可配置記憶體(合計1MB),可分成16KB共享記憶體加48KB一級快取,或者48KB共享記憶體加16KB一級快取,可靈活滿足不同類型程式的需要。
GT200的每組TPC還有一個一級紋理快取,不過當GPU出於計算模式的時候就沒什麼用了,故而Fermi並未在這方面進行增強。
整個晶片擁有 一個容量768KB的共享二級快取,執行原子記憶體操作(AMO)的時候比GT200快5-20倍。
3、效率
CPU和GPU執行的都是被稱作執行緒的指令流。高端CPU現在每次最多只能執行8個執行緒(Intel Core i7),而GPU的並行計算能力就強大多了:G80 12288個、GT200 30720個、Fermi 24576個。
為什麼Fermi還不如GT200多?因為NVIDIA發現計算的瓶頸在於共享記憶體大小,而不是執行緒數,所以前者從16KB翻兩番達到64KB,後者則減少了20%,不過依然是G80的兩倍,而且 每32個執行緒構成一組“Warp”。
在G80和GT200上,每個時鐘周期只有一半Warp被送至SM,換言之SM需要兩個循環才能完整執行32個執行緒;同時SM分配邏輯和執行硬體緊密聯繫在一起,向SFU傳送執行緒的時候整個SM都必須等待這些執行緒執行完畢,嚴重影響整體效率。
Fermi解決了這個問題, 在每個SM前端都有兩個Warp調度器和兩個獨立分配單元,並且和SM其它部分完全獨立,均可在一個時鐘循環里選擇傳送一半Warp,而且這些執行緒可以來自不同的Warp。分配單元和執行硬體之間有一個完整的交叉開關(Crossbar),每個單元都可以像SM內的任何單元分配執行緒(不過存在一些限制)。
這種執行緒架構也不是沒有缺點,就是 要求Warp的每個執行緒都必須同時執行同樣的指令,否則會有部分單元空閒。每組SM每個循環內可以執行的不同運算元:FP32 32個、FP64 16個、INT 32個、SFU 4個、LD/ST 16個。
4、並行核心(Parallel Kernel)
在GPU編程術語中,核心是運行在GPU硬體上的一個功能或小程式。G80/GT200整個晶片每次只能執行一個核心,容易造成SM單元閒置。這在圖形運算中不是問題,通用計算上就不行了。
Fermi的全局分配邏輯則可以向整個系統傳送多個並行核心,不然SP數量翻一番還多,更容易浪費。
應用程式在GPU和CUDA模式之間的切換時間也快得多了,NVIDIA宣稱是GT200的10倍。外部連線亦有改進,Fermi支持和CPU之間的並行傳輸,而之前都是串列的。
5、ECC支持
AMD Cypress可以檢測記憶體匯流排上的錯誤,卻不能修正,而 NVIDIA Fermi的暫存器檔案、一級快取、二級快取、DRAM全部完整支持ECC錯誤校驗,這同樣是為Tesla準備的,之前我們也提到過。
很多客戶此前就是因為Tesla沒有ECC才拒絕採納,因為他們的安裝量非常龐大,必須有ECC。
6、統一64-bit記憶體定址
以前的架構里多種不同載入指令,取決於記憶體類型:本地(每執行緒)、共享(每組執行緒)、全局(每核心)。這就和指針造成了麻煩,程式設計師不得不費勁清理。
Fermi統一了定址空間,簡化為一種指令,記憶體地址取決於存儲位置:最低位是本地,然後是共享,剩下的是全局。這種統一定址空間是 支持C++的必需前提。
GT80/GT200的定址空間都是32-bit的,最多搭配4GB GDDR3顯存,而 Fermi一舉支持64-bit定址,即使實際定址只有40-bit,支持顯存容量最多也可達驚人的1TB,目前實際配置最多6GB GDDR5——仍是Tesla。
7、新的指令集架構(ISA)
下邊對開發人員來說是非常酷的:NVIDIA宣布了一個名為“ Nexus”的外掛程式, 可以在Visual Studio里執行CUDA代碼的硬體調試,相當於把GPU當成CPU看待,難度大大降低。
Fermi的指令集架構大大擴充,支持DX11和OpenCL義不容辭,C++前邊也已經說過,現在又多了Visual Studio,當然還有C、Fortran、OpenGL 3.1/3.2。
Fermi 1.0
GF100
 Fermi
Fermi2010年3月27日,nVIDIA發布了兩款基於Fermi架構的DircetX 11桌面級顯示卡:GTX 480、GTX 470。GTX480在單卡單芯領域可以壓制大多ATI/AMD產品。不過,差距不大。它在一些優勢項目中性能直逼HD5970,向世人首次展示了Fermi架構的強大。不過,這位初代旗艦卡問題不是一般的多,同時,也是GF100核心的通病。
1、發熱問題:公版的GTX 480是配發的是一個巨型的渦輪風扇散熱器(雖然這類散熱器性能卓越,同時也帶來了巨大的噪音問題)。然而,即使是巨型的渦輪風扇散熱器依然無法壓制GTX 480炙熱的心,Fumark拷機測試中輕鬆超過90℃的發熱量讓人咋舌。
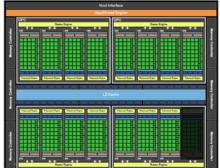 GTX 480使用的GF100核心
GTX 480使用的GF100核心2、核心問題:GTX 480除了是一個發熱大戶,同時也是業界第一個被閹割的旗艦產品。因為,台積電不成熟的40nm工藝,造成了桌面顯示卡史上第一個被閹割的旗艦。本來的512個CUDA核心被閹割成了480個。同時,從G80時代的MIMD設計雖然效率很高,卻需要大量電晶體。因為以上原因GTX480變成了擁有32億個電晶體的巨型GPU。由於工藝問題,核心的良品率和漏電問題一直困擾著nVIDIA的工程師們。
3、供電問題:公版的GTX 480在Fumark拷機測試中跑出466瓦的“強勁”數字。為了取保核心供電問題,公版設計上採用了6+2項供電模組和8pin+6pin外接供電口。
隨後發布的GTX 465依然存在這些問題。這也是人們不禁開始懷疑這nVIDIA的Fermi的真實性能,會不會是一個高技術的幌子。
GF100的設計方式就是將滿規格Fermi的4個GPC中得一個閹割掉一個SM就成了GTX 480
GF104
 nVIDIA公版GTX 460
nVIDIA公版GTX 460雖然旗艦們擁有強勁的性能。但是,功耗和發熱問題一直困擾著GF100軍團,面對早已展開防線的HD 5000系列,GF100還是有些力不從心。就在N卡用戶陸續轉投A卡陣營,獨立顯示卡出貨量歷史性的出現N:49%,A:51%超於。
就在這個危機時刻,2011年7月12日,nVIDIA發布里一款確切說是兩款基於GF104的GTX 460。由於,第一批GF100的Fermi架構GPU表現不盡人意,這個閹割版的GF100是個普遍不被看好這個閹割馬甲版的產品。
但是,結果卻在2年來沒什麼大動靜的圖形界引起了一場不小的地震。就測試結果來看,高端1GB 256bit版的GTX460不但能完全壓制HD 5830,在超頻後擁有挑戰HD 5850實力。而,縮水版的768MB 192bit版
 GF104
GF104又以接近HD5770價位完全壓制後者並能超頻後於HD 5830一戰。一夜之間,網路上頻繁出現“GTX460秒殺A卡全家的言論”。Q3的獨立顯示卡出貨量也是達到了驚人的N:V=7:3
GF104之所以能夠在ATI/AMD產品早已完成陣線,旗艦產品不給力的情況下完成這個大逆轉。是因為,GF104精簡掉了對3D遊戲能力幫助不大的L2快取和取消部分並行計算單元,在GF100的基礎上進一步最佳化核心漏電問題。一舉解決了,Fermi=烤爐的定律。一線廠商獲得的高質量核心能夠輕鬆超頻900MHz甚至更高。
為了解決這個塊硬骨頭AMD方面加緊了Barts核心的研發進度,還將HD 5830的價格降至GTX 460的水平。足見GF 104的強勁實力。
完整的GF104的設計方式是將GF100的單個GPC的128個CUDA核心擴張成192個,再將兩個擴張版的GPC的其中一個閹割掉1個SM。隨水版本略有不同。
GF106
2010年9月13日,nVIDIA發布了基於GF106的GTS 450。這意味著,已經同A卡苦戰長達近3年的G92終於能夠榮歸故里了。
基於的GF106架構產品共有2款一款是GTS 450海外 低頻版,一款是GTS 450大陸特供的高頻版。讓大陸玩家首次體會到被照顧了。
GF106的設計方式就是將GF104的兩GPC閹割成一個,其他不變。
GF108
 GF108
GF108第4梯隊的GF108核心共有款產品:GT 440和GT 430。但是,GT 440並沒有重現GT 240的輝煌。這主要和這兩款產品定位有關係。GF108主要重點是給用戶提供通用計算和音視頻解碼,而不是單純的遊戲性能。
GF108的設計方式是將GF106的規格減半。
