
發展歷史
Core微架構是由Intel位於以色列海法的研發團隊負責設計的。該以色列團隊早在2003年就因為設計出兼具高性能與低功耗的 Banias 處理器而聞名天下,Core 微架構也是他們在 Yonah 微架構之後的最新傑作。Core 微架構很早就出現在 Intel 的計畫之中了,早在2003年夏天 Intel 就曾經隱約提到過,原定是 Centrino 平台的第三代 Napa 平台後期和第四代 Santa Rosa 平台所採用的處理器。沒想到由於 NetBurst 微架構的失敗,Core 微架構被 Intel 改弦易轍,推上前台,被賦予了取代 NetBurst 微架構、一統桌面、移動與伺服器平台的歷史使命。 Intel 的新核心已經擁有多個名字。以色列團隊在設計之初,採用 Merom 作為開發代號。Merom的原意是約旦河附近的一個湖,這也是 Intel 的一個有趣的習慣——採用研發團隊居住地附近的地名作為產品的開發代號。然後,Intel 在2005年開始大規模宣傳該微架構的時候,把它描述為“下一代微架構”(Next Generation Micro-Architecture,簡稱NGMA)。而在2006年的IDF大會上,Intel 把它正式宣布為“Core 微架構”(Core Micro-Architecture)。
架構異同
由於在Core之前Intel最新的X86微架構同樣是出自這個設計團隊之手的 Yonah微架構,因此這很容易讓我們將二者關聯在一起。Core微架構與Yonah之間究竟有沒有聯繫?它們之間又會有什麼樣的關係?我們不妨先來 看看兩種構架的結構圖。
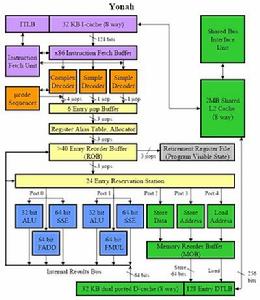 Core微架構與Yonah微架構對比圖2
Core微架構與Yonah微架構對比圖2因此可以說Core微架構是Intel在Yonah微架構基礎之上改進而來的下一代微架構,採取共享式二級快取設計,2個核心共享4MB或2MB的 二級快取,其核心採用高效的14級有效流水線設計,每個核心都內建32KB一級指令快取與32KB一級數據快取,而且2個核心的一級數據快取之間 可以直接傳輸數據。每個核心內建4組指令解碼單元,支持微指令融合與宏指令融合技術,每個時鐘周期最多可以解碼5條X86指令,並擁有改進 的分支預測功能。每個核心內建5個執行單元,執行資源龐大。採用新的記憶體相關性預測技術。加入對EM64T與SSE4指令集的支持,支持增強的 電源管理功能,支持硬體虛擬化技術和硬體防病毒功能,內建數字溫度感測器,還可提供功率報告和溫度報告等,配合系統實現動態的功耗控 制和散熱控制。
耦合度的鬆緊決定四核協作的效率高低,而微架構則決定每個核心的運算效率、實際性能、功耗高低等關鍵的特性。英特爾Kentsfield/Yorkfield兩代Core 2 Quad處理器都基於Core微架構,它所具有的卓越性能有目共睹。Core架構的優勢體現在以下幾個方面:
一、擁有超寬的執行單元,在每個周期,Core架構的指令解碼器可以同時發射4條指令,而AMD K8架構只能發射3條指令,換句話說,Core架構擁有更加出色的指令並行度;
二、Core架構具有“微操作融合(Micro-Op Fusion)”和“宏操作融合(Macro-Op Fusion)”兩項技術,可以對執行指令進行最佳化,通過減少指令的數量獲得更高的效率,英特爾表示這兩項技術最多可帶來67%的效率提升,這也是Core架構產品在低功耗狀態下依然擁有強勁效能的主要秘密;
三、Core微架構的SSE執行單元首度提供完整的128位支持,每個單元都可以在一個時鐘周期內執行一個128位SSE指令,而在多個執行單元的共同作用下,Core架構核心可以在一個時鐘周期內同時執行128位乘法、128位加法、128位數據載入以及128位數據回存,或者是可以同時執行4個32位單精度浮點乘法和4個32位單精度浮點加法,進而顯著提升多媒體性能;四、Core微架構採用共享快取設計,快取資源利用率也高於獨占式設計,且多個核心可以高效協作,當然,雙晶片的Kentsfield Core 2 Quad無法從這個優點中受益。
命名方式
“扣肉”是基於Core微架構的桌面平台級產品“Conroe”的音譯。不過由於“Core”和“ Conroe”兩個單詞在結構上頗為類似,因此有不少消費者往往便認為“Core”和“Conroe”指得是同樣一種產品。實際上,我們通常把“Core ”直接音譯為“酷睿”,它是Intel下一代處理器產品將統一採用的微架構,而Conroe(扣肉)只是對基於Core(酷睿)微架構的Intel下一代桌面 平台級產品的親切稱呼。除Conroe(扣肉)處理器之外,Core(酷睿)微架構還包括代號為“Merom”的移動平台處理器和代號為“Woodcrest”的 伺服器平台處理器。
採用Core的處理器將採用統一的命名。由於上一代採用Yonah微架構的處理器產品被命名為Intel Core Duo,因此為了便於與前代Intel 雙核處理器區分,Intel下一代桌面處理器Conroe以及下一代筆記本處理器Merom都將採用相同的命名方式——Core 2 Duo。另外,Intel最高性 能的桌面伺服器晶片Woodcrest將命名為Core 2 Extreme,以區分於普通桌面/筆記本處理器產品。
Conroe處理器沿用了L1 Cache設計,L1數據Cache和L1指令Cache分別為32KB,兩個核心共享4MB或2MB的L2 Cache,它結合了Pentium M 高效率和NetBurst動態執行性能優越兩方面的優點。Conroe處理器的數據流水線長度從Prescott的31級大幅度縮短至目前的14級。其算術邏輯 運算單元ALU數量由上代NetBurst微構架的2組提升至3組,同時在Cache構架上也經過了大幅度的改良,整體運算性能大大增加。
Conroe處理器將分為E8000、E6000和E4000三個系列,通過頻率、二級快取、前端匯流排的不同和是否支持VT等附加技術來進行定位。最 高端的E8000系列即Conroe Extreme Editon,將完整擁有VT等所有附加技術,並擁有最高的頻率,最高的前端匯流排,當然同時也擁有最強的性 能和最高的價格。中高端的E6000系列主要通過頻率和快取來區別,將是DIY市場的主流。無論是頻率還是價格,高端型號與低端型號的差別都 很大,覆蓋面很廣。低端的E4000系列把前端匯流排降到了800MHz,並去掉了VT等附加技術,定位於平價市場,類似於之前的Pentium D 805雙核 處理器的定位,不過更低的前端匯流排反而更加有利於超頻。
架構特點
流水線明顯縮短
Intel在新處理器微架構上做出的調整要大刀闊斧得多,流水線架構的調整也最為明顯。基於Core核心的Conroe處理器的流水線從 Prescott核心的31級縮短為14級,與目前的Pentium M相當。眾所周知,流水線越長,頻率提升潛力越大,但是一旦分支預測失敗或者快取不中 的話,所耽誤的延遲時間越長。如果一旦發生分支預測失敗或者快取不中的情況,Prescott核心就會有31個周期的延遲。這要比其他的架構延 遲時間多得多。而對於Conroe來說,14級流水線的效率要比Prescott核心的31級要高很多,延時卻要低得多。
在縮短流水線級數 的同時,Core 微架構前端的改進還包括分支預測單元。分支預測行為發生在取指單元部分。首先,它使用了很多人們已經熟知的預測單元,包 括傳統的 NetBurst 微架構上的分支目標緩衝區(Branch Target Buffer, BTB)、分支地址計算器(Branch Address Calculator, BAC)和返回 地址棧(Return Address Stack,RAS)。
然後,它還引入了2個新的預測單元—循環迴路探測器(Loop Detector, LD)和間接分支 預測器(Indirect Branch Predictor,簡稱IBP),其中循環迴路探測器可以正確預測循環的結束,而間接分支預測器可以基於全局的歷史信息 做出預測。Core 微架構在分支預測方面不僅可以利用所有這些預測單元,還增加了新的特性:在之前的設計中,分支轉移總是會浪費流水線的 一個周期;Core 微架構在分支目標預測器和取指單元之間增加了一個佇列,在大部分的情況下可以避免這一個周期的浪費。
高效 的流水線架構和更優秀的分支預測能力,使Conroe處理器的性能遠勝於前代Prescott核心的Pentium D,與AMD的AM2相比也要高出不少。當然這 不全是流水線架構改進的功勞,還有一點也相當重要,那就是Conroe的解碼單元。
縮短後的14級流水線
基於Core核心的Conroe處理器的流水線從Prescott核心的31級縮短為14級,與目前的Pentium M相當。大幅度縮短後的流水線,雖然頻率提升潛力會有所下降,但這使得延遲時間大大減低,效率也高得多。
另外,Core採用改進後的分支預測設計,這使它擁有更優秀的分支預測能力,避免了流水線周期的浪費。這些都使得Conroe處理器的性能比基於前代核心的產品性能提高不少。
超強的四組指令編譯器
Core微架構的最大變化之一,就是採用了四組指令編譯器,也就是四組解碼單元。這四組解碼單元由三組簡單解碼單元(Simple Decoder)與一組複雜解碼單元(Complex Decoder)組成。
另外,Core採用微指令融合技術,可以減少微指令的數目,這相當於在同樣的時間內,它能實際處理更多的指令,顯著提高了處理效能。而且,減少微指令的數目還能降低處理器的功耗。
更強大的記憶體I/O能力
Core微架構採用大容量的共享式二級快取。這種設計不僅減少了快取訪問延遲,提高了快取的利用率,而且還可以使單個核心享用完全的4MB快取。一級快取和二級快取的匯流排位寬都是256-bit,從而可以給核心提供最大的存儲頻寬。這些都有效地提高了系統的記憶體I/O能力。
此外,Core微架構提供記憶體數據依存性預測功能,可在處理器將數據回存記憶體的同時,預測後繼的載入指令是否採用相同的記憶體地址,並將未採用相同記憶體地址的後繼指令載入到指定位置。而增強的“預先載入機制”可根據應用程式數據的行為,進行指令與數據的預先抓取動作,讓所需要的記憶體地址數據,儘量存放在快取中,減少讀取記憶體的次數。這些大大改善了記憶體讀取效率,縮短了記憶體存取的延遲。
改善的智慧型電源管理能力
Core微架構具有智慧型電源管理能力(Intelligent Power Capability),在處理器內各功能單元並非隨時保持啟動狀態,而是根據預測機制,僅啟動需要的功能單元。在Core微架構上,新採用的分離式匯流排(Split Buses)、數字熱感應器(Digital Thermal Sensor)以及平台環境控制接口(Platform Environment Control Interface)等技術將帶來明顯的省電效果,這將大大降低功耗。
Core微架在降低耗電量的前提下,能夠達到較高的效能,不能不說它是一款成功的設計,同時,Core微架構的出現,也標誌著處理器的發展已經從一味追求高性能向追求高效的性能功耗比方向發展了。
技術規格
★65nm應變矽和Low-K(低k電介質)製造工藝;
★14級流水線設計;
★對應667MHz/800MHz/1066MHz/1333MHz前端匯流排;
★支持EM64T擴展技術、SSE3指令集以及Vanderpool虛擬化技術;
★雙核心架構,每個核心內建32KB一級指令快取與32KB一級數據快取,兩個核心共享2MB或4MB二級快取;
★每個核心內建四組指令解碼器和五個執行單元,可同時處理96個指令;
★支持微指令融合(Micro-Op fusion)與宏指令融合(Macro-Op fusion)機制;
★強化指令和數據預取機制,引入記憶體數據相依預測技術;
★智慧型電源管理技術,保證晶片的低能耗運作。
支持主機板
任何一款處理器產品都離不開相應主機板晶片組的支持,能夠正式支持Conroe處理器的主機板晶片組產品均出自Intel自家之手。由於採用 Core微架構的Conroe系列雙核處理器仍然沿用了LGA775接口,因此可以說目前所有採用Intel晶片組的LGA775接口主機板都具備了支持Conroe處理 器的條件。
1、865主機板也可支持Conroe處理器。
865晶片組相信大家都很清楚,這款產品曾經過改造後提供對64位處理器的支持。當 然老邁的865主機板經過改造之後也可以完美的支持Conroe處理器,而且還是相對較為高端的Conroe E6700。
2、975晶片組。
i975X晶片組是目前Intel最為高端的桌面級晶片組產品,不過從Intel官方所給出的i975X晶片組的構架 圖中我們並沒有獲取到任何對Conroe處理器支持的訊息,究其原因,是因為早先的i975X主機板的VRM模組不符合Conroe處理器的要求,而採用全 新VRM 11模組的i975X主機板便可以完美的支持Conroe處理器。所謂VRM,就是Voltage Regulator Module(電壓調節模組)的縮寫,它是Intel專門 針對其處理器產品所提出的主機板供電電路設計標準。因此可以說,主機板是否支持VRM 11模組,才是支持Conroe處理器與否的決定性因素。
3、全新的946/965晶片組。
採用全新Core構架的Conroe處理器擁有更強大的功耗管理功能,因此也需要主機板相應的VRM模組 在低電壓支持以及更精細的電壓調節方面也要隨之增強。Intel專為Conroe處理器所推出的全新946/965系列晶片組自誕生之日起就能夠支持 Conroe處理器,就在於基於946/965系列晶片組的主機板從一開始就採用了VRM 11模組,再結合i975X主機板改造前後的例子,依據這個邏輯,未來 做出相應改動後的945和955系列主機板應該也能夠提供這方面的支持。
系列規劃
Yonah英特爾酷睿雙/單核處理器的開發名稱,它採用65nm製程,Socket479接口針腳,前端匯流排提升至533MHz/667MHz,引入了雙核技術,通過SmartCache共享2M L2快取,並且開始加入了SEE3多媒體指令集。它與i945M/i945MDH配合使用,因為前總提升到667MHz,所以使用DDR2 667記憶體,它雖然是Socket479接口針腳,但與Pentium M完全不兼容。
目前採用Yonah核心CPU的有雙核心的Core Duo和單核心的Core Solo,另外Celeron M也採用了此核心,Yonah是Intel於2006年初推出的。這是一種單/雙核心處理器的核心類型,其在套用方面的特點是具有很大的靈活性,既可用於桌面平台,也可用於移動平台;既可用於雙核心,也可用於單核心。Yonah核心來源於移動平台上大名鼎鼎的處理器Pentium M的優秀架構,具有流水線級數少、執行效率高、性能強大以及功耗低等等優點。Yonah核心採用65nm製造工藝,核心電壓依版本不同在1.1V-1.3V左右,封裝方式採用PPGA,接口類型是改良了的新版Socket 478接口(與以前台式機的Socket 478並不兼容)。在前端匯流排頻率方面,目前Core Duo和Core Solo都是667MHz,而Yonah核心Celeron M是533MHz。在二級快取方面,目前Core Duo和Core Solo都是2MB,而即Yonah核心Celeron M是1MB。Yonah核心都支持硬體防病毒技術EDB以及節能省電技術EIST,並且多數型號支持虛擬化技術Intel VT。但其最大的遺憾是不支持64位技術,僅僅只是32位的處理器。值得注意的是,對於雙核心的Core Duo而言,其具有的2MB二級快取在架構上不同於目前所有X86處理器,其它的所有X86處理器都是每個核心獨立具有二級快取,而Core Duo的Yonah核心則是採用了與IBM的多核心處理器類似的快取方案--兩個核心共享2MB的二級快取,共享式的二級快取配合Intel的“Smart cache”共享快取技術,實現了真正意義上的快取數據同步,大幅度降低了數據延遲,減少了對前端匯流排的占用。這才是嚴格意義上的真正的雙核心處理器。Yonah核心是共享快取的緊密型耦合方案,其優點是性能理想,缺點是技術比較複雜。不過,按照Intel的規劃,以後Intel各個平台的處理器都將會全部轉移到Core架構,Yonah核心其實也只是一個過渡的核心類型,從2006年第三季度開始,其在桌面平台上將會被Conroe核心取代,而在移動平台上則會被Merom核心所取代。
這是更新的Intel桌面平台雙核心處理器的核心類型,其名稱來源於美國德克薩斯州的小城市“Conroe”。Conroe核心於2006年7月27日正式發布,是全新的Core(酷睿)微架構(Core Micro-Architecture)套用在桌面平台上的第一種CPU核心。目前採用此核心的有Core2 Duo E6x00系列和Core 2 Extreme X6x00系列。與上代採用NetBurst微架構的Pentium D和Pentium EE相比,Conroe核心具有流水線級數少、執行效率高、性能強大以及功耗低等等優點。Conroe核心採用65nm製造工藝,核心電壓為1.3V左右,封裝方式採用PLGA,接口類型仍然是傳統的Socket 775。在前端匯流排頻率方面,目前Core 2 Duo和Core 2 Extreme都是1066MHz,而頂級的Core 2 Extreme將會升級到1333MHz;在一級快取方面,每個核心都具有32KB的數據快取和32KB的指令快取,並且兩個核心的一級數據快取之間可以直接交換數據;在二級快取方面,Conroe核心都是兩個核心共享4MB。Conroe核心都支持硬體防病毒技術EDB、節能省電技術EIST和64位技術EM64T以及虛擬化技術Intel VT。與Yonah核心的快取機制類似,Conroe核心的二級快取仍然是兩個核心共享,並通過改良了的Intel Advanced Smart Cache(英特爾高級智慧型高速快取)共享快取技術來實現快取數據的同步。Conroe核心是目前最先進的桌面平台處理器核心,在高性能和低功耗上找到了一個很好的平衡點,全面壓倒了目前的所有桌面平台雙核心處理器,加之又擁有非常不錯的超頻能力,確實是目前最強勁的台式機CPU核心。
Allendale這是與Conroe同時發布的Intel桌面平台雙核心處理器的核心類型,其名稱來源於美國加利福尼亞州南部的小城市“Allendale”。Allendale核心於2006年7月27日正式發布,仍然基於全新的Core(酷睿)微架構,目前採用此核心的有1066MHz FSB的Core 2 Duo E6x00系列,即將發布的還有800MHz FSB的Core 2 Duo E4x00系列。Allendale核心的二級快取機制與Conroe核心相同,但共享式二級快取被削減至2MB。Allendale核心仍然採用65nm製造工藝,核心電壓為1.3V左右,封裝方式採用PLGA,接口類型仍然是傳統的Socket 775,並且仍然支持硬體防病毒技術EDB、節能省電技術EIST和64位技術EM64T以及虛擬化技術Intel VT。除了共享式二級快取被削減到2MB以及二級快取是8路64Byte而非Conroe核心的16路64Byte之外,Allendale核心與Conroe核心幾乎完全一樣,可以說就是Conroe核心的簡化版。當然由於二級快取上的差異,在頻率相同的情況下Allendale核心性能會稍遜於Conroe核心。
Merom這是與Conroe同時發布的Intel移動平台雙核心處理器的核心類型,其名稱來源於以色列境內約旦河旁邊的一個湖泊“Merom”。Merom核心於2006年7月27日正式發布,仍然基於全新的Core(酷睿)微架構,這也是Intel全平台(台式機、筆記本和伺服器)處理器首次採用相同的微架構設計,目前採用此核心的有667MHz FSB的Core 2 Duo T7x00系列和Core 2 Duo T5x00系列。與桌面版的Conroe核心類似,Merom核心仍然採用65nm製造工藝,核心電壓為1.3V左右,封裝方式採用PPGA,接口類型仍然是與Yonah核心Core Duo和Core Solo兼容的改良了的新版Socket 478接口(與以前台式機的Socket 478並不兼容)或Socket 479接口,仍然採用Socket 479插槽。Merom核心同樣支持硬體防病毒技術EDB、節能省電技術EIST和64位技術EM64T以及虛擬化技術Intel VT。Merom核心的二級快取機制也與Conroe核心相同,Core 2 Duo T7x00系列的共享式二級快取為4MB,而Core 2 Duo T5x00系列的共享式二級快取為2MB。Merom核心的主要技術特性與Conroe核心幾乎完全相同,只是在Conroe核心的基礎上利用多種手段加強了功耗控制,使其TDP功耗幾乎只有Conroe核心的一半左右,以滿足移動平台的節電需求。
woodcrest英特爾年度重頭戲-雙核心Intel Xeon處理器5100系列,其產品代號為Woodcrest,與桌上型Conroe及筆記型Merom基於相同的Core微架構,Woodcrest搭配全新的Intel 5000系列晶片組,包括Blackford 5000P/5000V及Greencreek 5000X,英特爾的多款雙處理器伺服器平台,如Bensley、Bensley-VS及Glidewell都以Woodcrest為核心。
Woodcrest採用英特爾先進的65納米製程技術,加上最最佳化的Core微架構設計,與前代產品相比,不僅耗電量降低40%,性能則大幅提升 135% (*實際幅度視具體套用而定);首批推出的Woodcrest包括5160 (3 GHz)、5150 (2.66 GHz)、5140 (2.33 GHz)、5130 (2 GHz)、5120 (1.86 GHz)及5110 (1.6 GHz)共六款,千顆單價從851美元至209美元。
所有Woodcrest皆內含4 MB共享型高速二級快取,散熱設計功率(thermal design power,TDP) 方面除5160型號為80瓦以外,其餘全部為65瓦;在系統匯流排 (FSB)上,四款2 GHz及以上頻率版本為1333 MHz,其餘兩款低頻版本為1066 MHz。
另外,英特爾將在2007年推出由兩顆Woodcrest合併而成的四核心Clovertown,插槽腳位與Bensley平台兼容,支持對稱式多重處理器(Symmetric Multi-Processor,SMP)技術,舉例來說,若在一台安裝兩顆Clovertown的兩路伺服器,實際擁有的處理器核心將多達八顆。
Intel將於2006年11月14日發布代號為Clovertown的四核心伺服器處理器:Xeon 5300系列,其中包含4種不同的具體型號,它們是“2.66GHz的Xeon X5355、2.33GHz的Xeon E5345、1.86GHz的Xeon E5320、1.60GHz的Xeon E5310”。
四核處理器是將四個獨立的處理器集成在一個晶片上,允許晶片同步處理四項不同的任務,這樣可以大大提高處理器的計算能力。一台雙路四核心伺服器性能就相當於以前的8路伺服器。
Intel對外公布的Xeon 5300處理器的一些參數:“架構依然是Woodcrest,1枚Xeon 5300處理器內含4個處理核心,單塊主機板上最多可放置2枚Xeon 5300處理器,處理器反應速度在1.66GHz到2.66GHz之間,二級Cache都是8兆,每個Xeon 5300處理器耗電量是80瓦”。
英特爾即將發布的四核處理器“Clovertown”也就是Xeon 5300系列產品,是由兩顆“Woodcrest”Xeon 5100系列處理器的核心(DIE),封裝到一個處理器基板(Socket)上,所以在除了兩倍(8M)於後者的2級快取之外的其他技術指標上,四核的Xeon5300 與雙核的Xeon5100系列處理器幾乎一樣,同樣的1333MHz的前端匯流排,同樣的65nm工藝,同樣的處理器還支持英特爾寬位動態執行技術、英特爾高級智慧型高速快取、英特爾智慧型記憶體訪問、英特爾智慧型功率管理等一系列的新技術。
Intel基於45納米技術處理器的開發代號。採用了45納米高-k製造技術(採用鉻合金高-K與金屬柵極電晶體設計),並對酷睿微體系結構進行了增強。將於2007年年底在兩個45納米製造工廠投入生產,計畫於2008年下半年在四個工廠批量生產,屆時這些處理器的產量可達數千萬台。其中,即將於下半年推出的Penryn家族有6款產品,包括台式機處理器(雙核和四核)、移動處理器(雙核),以及伺服器處理器(雙核和四核)。面向更高端伺服器多處理系統的處理器目前正在研發之中。
跟當前的65納米工藝相比,下一代45納米高k製程技術可以將電晶體數量提高近2倍,如下一代英特爾酷睿2 四核處理器將採用8.2億個電晶體。藉助新發明的高-k金屬柵極電晶體技術,這8.2億個電晶體能夠以光速更高效地進行開關,電晶體切換速度提升了20% 以上,實現了更高的核心速度,並增加了每個時鐘周期的指令數。雙核處理器中的矽核尺寸為107平方毫米,比英特爾目前的65納米產品小了25%,大約僅為普通郵票的四分之一大小,為添加新的特性、實現更高性能提供了更多自由空間。同時,由於減少了漏電流,因而可以降低功耗,同英特爾現有的雙核處理器相比,新一代處理器能夠以相同甚至更低的功耗運行,如Penryn處理器的散熱設計功耗是,雙核為40瓦/65瓦/80瓦,四核是50瓦/80瓦/120瓦。
全新的特性:快速Raidix-16除法器、增強型虛擬化技術、更大的高速快取、分離負載高速快取增強、更高的匯流排速度、英特爾SSE4指令、超級Shuffle引擎、深層關機技術、增強型動態加速技術、插槽兼容等。這些新特性使得Penryn能在性能、功耗、數字媒體套用、虛擬化套用等方面得到提升,如跟當前的產品相比,採用1600MHz前端匯流排、3GHz的Penryn處理器可以提升性能約45%。
技術創新
Intel Core微架構完全承襲了P6微架構的優良傳統,並加入了多項創新的技術,針對提升每周指令執行指令數目而努力,從以提升效能功耗比。如果拿Core微架構與AMD K8微架構作比較,就會發現Core微架構有更"寬"的設計,Core微架構的4-Wide執行核心為x86系統提供了強大IPC運算能力,尤其是SSE指令集方面,Core微架構採用3組ALU,相比上代Yonha多出一組並已追上了AMD K8微架構的單簡x86指令執行能力,同時Core微架構卻大幅提升SIMD指令能力,擁有3組128Bit SSE運算組,亦因如此Intel Core微架構將擁有比AMD K8微架構約三倍以上的整數SSE指令頻寬,而浮點SSE指令頻寬亦比AMD K8微架構高出2倍。
為了提供升實際軟體的IPC運算潛能,Intel並不只單純地加入更多的運算組,還在處理器設計上作出重大改良,為了讓IPC能力保持於高水平,Intel加入了兩個Fusion機制包括Marco Fusion及Micro Fusion,同時採用了Memory Disambiguation提供了Out-of-order的效率,所有設計都讓Intel Core微架構變能體現Performance per Watt的能力。
雖然AMD K8微架構已是三年前的產品,但其設計卻一點也不顯得落後,但面對有備而來的Intel Core微架構還是顯得有心無力,現時AMD K8微架構僅存的優勢就是內建記憶體控制器,但由於Intel Core微架構在Cache設計(加入更多的Prefetchers)、增強Branch Prediction命中率及記憶體存取上的技術改良(Memory Disambiguation),AMD於這記憶體效能的領先已被大幅收窄。據Intel表示,它們要把記憶體控制器放進處理器並不困難,是不為也非不能也,主要是考慮到加入記憶體控制器將會令產品被限制其記憶體支援彈性及升級能力,加上Intel估計記憶體的發展速度將會不斷增加,AMD需要不斷改良核心內的記憶體控制器設計才能追上記憶體發展的步伐,值得注意的是,未來IGP晶片組占市場比例將日益增加,內建記憶體控制器將成為IGP系統設計的弱點,效能上比不上北橋內建記憶體器方案。
無疑Intel Core微架構是一顆十分優秀的處理器,解決了一直以來Intel雙核心處理器的設計弱點,其高效率低功耗設計更讓微架構可跨越Desktop、Mobile及Server平台,效能絕對能凌駕現時所有x86微架構之上,相信AMD在下一代K8L微架構出台前會受到極嚴峻的壓力,筆者認為Core微架構唯一的弱點還是在於其SMP的支援能力,在Server的領域裡,企業可能會使用超過四顆以上的伺服器系統,由於AMD處理器擁有Hyper-Transport Tunnel,讓各顆處理器能行擁有管道通交換資料,但Intel Core微架構在多處理器方案中,還是保留FSB及北橋作傳輸設計上落後於AMD,故此Intel Core微架構在Desktop、Mobile及SOHO Server (1-2 CPU)較AMD K8擁有更佳優勢是不會被質疑,但與AMD Opteron處理器對決於多路處理器領域,則因FSB先天架構不足還是較為落後。
Core 微架構 vs. K8 微架構——解碼單元
Core 微架構的3組簡單解碼單元與1組複雜解碼單元 vs. K8 處理器的3組複雜解碼單元。
K7 處理器有2種解碼方法,向量路徑(Vector Path)和直接路徑(Direct Path)。向量路徑解碼會生成多於2條的類似RISC的指令(AMD稱為Macro-Op,即宏指令)。直接路徑解碼會生成1條或者2條宏指令。K7 處理器的每組解碼單元都可以進行向量路徑解碼和直接路徑解碼,但是從性能的角度講,直接路徑解碼無疑是更好的選擇,因為它會生成數量較少的宏指令。因為就像 Core 微架構是基於 P6 微架構一樣,K8 處理器很大程度上也是基於 K7 處理器的。
K7 處理器的3組複雜解碼單元是強大的,可以解碼絕大多數X86指令,只有很少一部分指令需要使用向量路徑解碼。它們僅有的缺點是一些浮點指令和SSE指令需要使用向量路徑解碼。而 K8 處理器擁有更強大的複雜解碼單元——幾乎所有的浮點指令和SSE指令都可以使用直接路徑解碼了。這是因為K8 處理器的取指與解碼單元的流水線比 K7 處理器的更長。當涉及到SIMD指令時,K8 處理器尤其強於 K7 處理器。
顯然,Intel 的宏指令融合技術在AMD 的 K8 處理器上並不存在。但是,AMD擁有與微指令融合技術類似的技術。首先需要注意的是,Intel 與 AMD 使用的名詞“宏指令”與“微指令”具有不同的含義,很容易使人混淆。這裡我們給出下面的表格,對它們進行分辨。
在 Athlon 處理器中,也存在有微指令融合技術。例如,一條 ADD [mem], EAX 指令在真正執行前中始終保持為一條指令。因此,它在緩衝區中也只會占據1個單元的空間。不過,在 Core 微架構中 load 操作和 SSE 操作等也可以被融合,而 K8 處理器則不行,它會把SSE操作解碼成2條宏指令。
那么,在解碼單元方面,Intel 的 Core 微架構與 AMD 的 K8 處理器比較的結果是什麼呢?就目前的資料來看,還很難確切的說到底哪個更加有實力。不過,我們有一個初步的看法:Core 微架構要更具有優勢。因為在一般情況下,它每個時鐘周期可以解碼4條X86指令,加上宏指令融合技術的話則最多可以解碼5條X86指令。而 AMD 的 K8 處理器每個時鐘周期只能解碼3條。
總而言之,AMD 的3組複雜解碼單元勝過 Core 微架構的3組簡單解碼單元加上1組複雜解碼單元的情況不大可能發生。僅當多條複雜指令同時需要複雜解碼單元進行解碼的時候,K8 處理器的解碼單元會勝過 Core 微架構的解碼單元。但是考慮到實際程式中的絕大多數X86指令對應簡單解碼單元的事實,這種情況不大可能發生。
Core 微架構 vs. K8 微架構——亂序執行引擎
Core 微架構擁有更大的亂序緩衝區——96 entry,再考慮到它的宏指令融合技術,其實際容量比 K8 處理器的72 entry要大的多。而最初的 P6 微架構只有40 entry,在Banias、Dothan 及 Yonah 處理器中增加到了80 entry,而現在的 Core 微架構進一步增加到了96 entry。為了看起來清晰、直觀,我們製作了下面的表格來比較這幾代處理器的重要特性。
Core 微架構採用集中式保留站(central reservation station),而 K8 處理器採用分散式調度器(distributed scheduler)。集中式保留站的優勢是擁有更高的利用率,而分散式調度器能容納更多的表項。NetBurst 微架構也採用分散式調度器。
使用集中式保留站也是把 Core 微架構稱作“P8 微架構”的理由之一,這是相對古老的 P6 微架構的第二項巨大的提升。它利用保留站並調度與分配執行單元來執行微指令。執行結束後,執行結果被存儲到亂序緩衝區內。這樣的設計方式無疑是繼承自Yonah、Dothan 甚至 P6 微架構。
最大的區別並不能立即從圖表上看出來。Intel 先前的處理器需要2個時鐘周期才能完成一次分支預測操作,而 Core 微架構只需要1個時鐘周期。而 AMD 的 K8 處理器也只需要1個時鐘周期就可以完成一次分支預測操作。
另外一處令人驚訝的地方是 Core 微架構的 SSE 多媒體指令執行性能。Core 微架構擁有3組非常強大的128-bit的 SSE 執行單元,其中2組是對稱的。擁有如此強大的SSE執行資源,Core 微架構在執行128-bit SSE2/SSE3指令時將遠遠超過 K8 處理器。
在 K8 處理器上,1條128-bit的 SSE 指令會被解碼成2條64-bit的指令,因為 K8 處理器的 SSE 執行單元只能執行64-bit的指令。所以說,從這個角度看,Core 微架構的SSE處理能力至少是 K8 處理器的2倍。如果是對64-bit的浮點進行操作,Core 微架構每個時鐘周期可以處理4個雙精度浮點數的計算,而 K8 處理器可以處理3個。
就整數執行單元來說,Core 微架構比 Pentium 4 處理器和 Dothan 處理器也有很大的提高,而與 K8 處理器處於同樣的水準——如果只考慮執行單元的數量的話,Core 微架構與 K8 處理器都擁有3組ALU。如果也考慮 AGU 的話,K8 處理器擁有3組,甚至比 Core 微架構的2組要更有優勢。這可能會使 K8 處理器在一些不太常見的整數計算中有優勢,比如解密運算。不過,Core 微架構擁有的更深、更靈活的亂序緩衝區和更大、更快速的二級快取可以在絕大多數整數運算中消除 K8 處理器這個小小的優勢。
改進解析
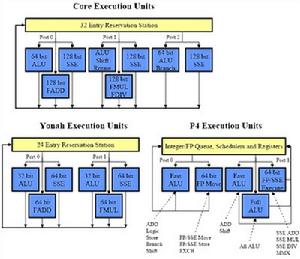 Intel 三代微架構執行單元對比
Intel 三代微架構執行單元對比很明顯,我們首先注意到 Core 微架構擁有3個調度連線埠——比 NetBurst 微架構和 Yonah 微架構的2個連線埠增加了1個。所以,Core 微架構的執行單元子系統每個周期最多可以執行3條操作,而 Yonah 微架構最多只能執行2條。需要注意的是,對於 NetBurst 微架構來說,並不是2條。NetBurst 微架構的調度機制使得每個周期最多可以執行4條操作,但是這種情況會相當罕見——必須是4個簡單的整數單元操作。並且,NetBurst 微架構在執行64bit指令時會有額外的延遲。更重要的是,Core 微架構的功能單元的統籌安排相對平衡,對於整數操作,可以在多個周期內保持單周期執行3個操作的吞吐量。而 NetBurst 微架構在很多情況下只能單周期執行1個操作。
Core 微架構所擁有的3個64bit的整數執行單元並非完全相同。與解碼單元部分類似,3個整數執行單元也分為1個複雜整數執行單元和2個簡單整數執行單元。不過,Core 微架構是 Intel 的X86架構處理器第一次可以在一周期內完成一次64bit的整數運算。之前的 NetBurst 微架構雖然也可以完成64bit的整數運算,但是需要2個時鐘周期。另外,因為3個整數執行單元占據了不同的連線埠,所以採用 Core 微架構的處理器可以在一周期內最多執行3組64bit的整數運算。
Core 微構架擁有2個浮點執行單元,位於連線埠0的浮點執行單元負責加減等簡單的浮點運算,而連線埠1的浮點執行單元則負責乘除等浮點運算。這樣,在Core 微架構中,浮點加減指令與浮點乘除指令被劃分成兩部分,使其具備了在一周期中完成兩條浮點指令的能力。
Core 微架構在 SSE 運算方面的性能也比它的前任有很大的提高。它的3個128bit的 SSE 單元並不是完全相同的,在移位和乘法的資源方面有微小的差異,但是都可以在單周期內完成1個128bit的 SSE 操作。相比之下,NetBurst 微架構的 SSE 單元無論在數量上還是質量上都有所不如:只有2個64bit的 SSE 單元,需要2個周期來執行1個128bit的操作。Yonah 微架構同樣只有2個64bit的 SSE 單元。從SSE指令的執行資源來看,Core 微架構比 NetBurst 微架構和 Yonah 微架構有3倍的提升!
128bit的SSE執行單元有什麼樣的意義?讓我們從 Intel 最初支持128bit的向量執行指令開始說起。當 Intel 最初兼容128bit向量執行的時候,也就是在 P6 微架構上開始出現 SSE 指令集的時候,P6 微構架的向量執行單元單周期內只能進行64bit的運算,對於處理128bit數據的指令,P6 微構架必須把該指令解碼成2條處理64bit數據的微指令來執行。這樣的執行方案一直沿用了下來,包括採用 NetBurst 微架構的處理器和 Yonah 處理器。
Core 微架構終於擁有了完整的128bit的向量處理單元。配合多達3組的執行單元以及load、store 存儲單元,Core 微架構可在一個時鐘周期內,同時執行一個128bit乘法操作、一個128bit加法操作、一個128bit load操作與一個128bit store操作,另外還有可能再加上一條經過宏指令融合的cmp/jmp指令——相當於單周期6條指令!真是令人嘆為觀止的指令級並行處理能力。做出如此大幅改進的 SSE 處理能力,使得 Core 微架構更加有利於多媒體方面的套用。
關鍵特性
關鍵特性之一:超寬動態執行單元“超寬”的實質效果就是“效率提升”。在“超寬動態執行單元”這一概念中,超寬的解碼單元和強化的指令預取能力是最主要的組成部分。
1.超寬的解碼單元
NetBurst架構效率低下有兩大原因,流水線過長只是其中之一,另一“元兇”則是通用解碼器效率不高。在CPU內部,一個指令被送到運算單元執行以前,必須先經過解碼器進行解碼,也就是把長度不一的X86指令分解為多個固定長度的微指令。解碼效率的高低對程式的運行速度有著至關重要的影響。
CPU解碼器面對的指令要么是簡單指令,要么是複雜指令。按照“簡單-複雜”的原則,CPU解碼器可以設計成兩種類型:一種對應簡單指令,我們稱之為簡單指令解碼器;另一種對應複雜指令,我們稱之為複雜指令解碼器。長期以來,X86處理器的解碼器都使用了“簡單-複雜”的專用體系,比如P6/Pentium M、AMD K7/K8等架構。以經典的P6架構(註:Pentium Pro、Pentium Ⅱ和Pentium Ⅲ都採用了P6架構)為例,該架構的指令解碼器是由一個複雜指令解碼器和兩個簡單指令解碼器構成,每個時鐘周期可同時處理3個指令,其中複雜指令解碼器最多可以對包含4個微指令的複雜指令作解碼處理,如果“不幸”遇到更複雜的指令,解碼器就必須呼叫微碼循序器,通過它把複雜指令分解成多個微指令系列進行處理。
在NetBurst架構中,Intel取消了解碼器的簡單與複雜之分,每個解碼器都能處理簡單指令和複雜指令,此舉在處理動態指令較多的套用時,解碼器可以發揮較高的效率,但當遇到簡單指令較多的套用時,解碼器的效率反而不高。為解決這一問題,在設計Core的架構時,Intel除了將流水線長度從Prescott時代的31級縮短至14級,還讓解碼器回歸到傳統的“簡單-複雜”專用體系,不過與P6/Pentium M不同的是,Core架構的解碼器數量被提升至4個,其中複雜解碼器仍為1個,但簡單解碼器增至3個。由於X86指令系統複雜,Core架構中多達4個解碼器已經是一種突破,想再增加解碼器的數量,特別是增加複雜解碼器的數量會有不小的困難。在X86程式中,複雜指令雖然只占據了程式數量20%的比重,但它卻要花費CPU 80%的運算資源。看來解碼效率要有跨越式的提升,還需要其他手段進行輔助。為此,Core架構在繼承Pentium M的微操作融合(Micro-Op Fusion)技術(該技術把多個解碼後具有相似點的微指令融合為一個,減少了微指令的數量,從而提高CPU的工作效率)的基礎上,還創造性地引入了宏操作融合(Macro-Op Fusion)技術。宏操作融合技術的巧妙之處,就在於它能把比較(compare)和跳躍語句(jump)融合成一條指令,這樣一來,複雜指令解碼器就間接擁有同時處理兩條指令的能力。在最佳最佳化的情況下,Core架構在一個周期內最多可以對5條指令同時解碼,解碼效率有了實質性的提升。
2.強化的指令預取能力
“好馬還要配好鞍”。解碼效率的提升,必然要求預取單元供給充足數量的指令。Core架構也充分認識到這一點,它的指令預取單元每次可以從一級快取中獲得6個X86指令,由此滿足了指令解碼器的需求。指令經過解碼後,再作重命名/地址分配、重排序等最佳化,最後送到調度器中,由調度器分派給運算單元進行處理。
高級數字媒體加速器的核心內容就是增強SSE執行單元的運算性能。在Core架構上,Intel首次對SSE執行單元提供完整的128位支持。此舉究竟有什麼含義?以Yonah為例,它僅能實現64位支持,要執行一條128位SSE指令就要花費兩個時鐘周期,而Core只要一個時鐘周期就可以完成。雖然NetBurst架構也提供了128位執行單元,但它僅有一組,SSE性能增長幅度遠不如Core那么明顯。在完整的128位SSE執行單元的作用下,Core架構可以在一個時鐘周期內同時執行128位乘法、128位加法、128位數據載入及128位數據回存,或同時執行4個32位單精度浮點乘法與4個32位單精度浮點加法,這是Yonah、Pentium D的兩倍。目前SSE在遊戲及多媒體中有著廣泛的套用,看來Conroe在遊戲測試中的耀眼表現並非虛談。
關鍵特性之三:高級智慧型快速快取與Yonah一樣,Core架構使用了雙核共享二級快取的方案,它可以避免快取作頻繁的同步更新,增強了雙核的協作效率。Core架構同樣繼承了Pentium M的低功耗快取技術,避免了大容量二級快取帶來的高功耗情形。
關鍵特性之四:智慧型記憶體訪問技術為了提升CPU訪問記憶體的效率,Intel為Core帶來了嶄新的智慧型記憶體訪問技術,它包括記憶體數據相依預測和強化的數據預取機制兩項措施。
1.記憶體相依預測功能
目前CPU如果碰到寫入、讀取相連的指令序列,就要先執行寫入指令,然後再執行讀取指令。這樣設計主要是考慮當讀取和寫入針對相同的記憶體地址時,CPU就有可能讀取到寫入前的無效數據,但當寫入和讀取的記憶體地址不一樣時,CPU如此設計就等於浪費了時間在那邊空等。為了解決這一問題,Core架構引入了記憶體數據相依性預測功能,CPU會判斷後續的讀取指令是否操作相同的記憶體地址,如果不一樣,CPU就可以同時進行寫入與讀取的並行操作。此舉對提高亂序指令的執行效率有不小的作用。
2.強化的數據預取機制
為了減少CPU訪問記憶體的次數,Core架構還對數據預取機制進行了強化。Core架構為每個核心提供了兩組數據預取邏輯,連二級快取控制器也內置了兩組,比起以往,可被存儲到快取單元內的程式數據增加了,CPU訪問記憶體的次數也就相應減少了。此舉對於記憶體性能的提升有積極的作用。
Core架構產品的低功耗表現,除了得益於核心架構的改變,還與智慧型型電源管理的增強有著密不可分的關係。除了我們熟悉的增強型SpeedStep功能外(可對電壓/頻率進行動態調節,允許以單核模式運行),Core架構的智慧型電源管理還有以下幾個亮點:
1.動態激活/關閉功能單元
Core架構把電源管理範圍細化到CPU內部的各個邏輯單元。有時候,CPU內部的部分邏輯單元並沒有處於激活的狀態,如果可以在需要的時候才讓它們運轉,不需要的時候讓它們暫時休眠一下,CPU就可以進一步減少無意義的能源消耗。動態激活/關閉功能單元就可以起到這個效果。
2.分離式前端匯流排
Core架構繼承了以往64位前端匯流排設計,但在減少前端匯流排的能源消耗上,它採用了一個巧妙的“手筆”——引入分離式前端匯流排設計。當前端匯流排傳輸的數據並不多時,前端匯流排只會開啟32位,另外32位暫時處於關閉狀態,而當傳輸數據較多時,全部的傳輸線路又會被開啟,此舉有效減少了前端匯流排的無謂能源消耗。
3.更精確的運行溫度控制
為了對溫度實施更精確的控制,Core架構在CPU內的數個熱點放置了數字熱量感測器,通過專門的控制電路,CPU可以精確獲知當前的發熱量並迅速調整好運作模式。對於筆記本產品,Core架構提供了PSI-2功能,它能實時通知系統現在的耗電狀況,以方便對電壓進行動態調整。而對於伺服器產品,Core架構則提供了平台環境控制界面功能,系統可以根據該功能傳回的實際溫度調整散熱風扇的運作模式。
