
引言
(今天我們主要談談處理器架構,至於製程技術大家可以查閱“32納米”詞條)
回顧歷代處理器,我們不難發現英特爾在絕大部分時間內都保持業界的領先地位,無論是早期的P5/P6微架構,還是造就輝煌的Core微架構以及即將全面鋪向市場的Nehalem微架構處理器,都已經或者即將促使整個產業的變革。
P5架構
奔騰採用P5架構,這被證明是偉大的創舉。在英特爾的發展歷史中,第一代奔騰絕對是具有里程碑意義的產品,這一品牌甚至沿用至今,已經有十幾年的歷史了。儘管第一代奔騰60的綜合表現很一般,甚至不比486DX66強多少,但是當主頻優勢體現出來之後,此時所表現出來的威力令人震驚。奔騰75、奔騰 100以及奔騰 133,經典的產品一度稱雄業界。
P6架構
在奔騰時代,雖然英特爾在處理器微架構方面一直保持著領先,但是英特爾並未停止前進的步伐,於是在發布奔騰的下一代產品奔騰 II時,英特爾採用了專利保護的P6架構。P6架構與奔騰的P5架構最大的不同在於,以前集成在主機板上的二級快取被移植到了處理器內,從而大大地加快了數據讀取和命中率,提高了性能。
常見架構
NetBurst架構
Netburst微架構是P6微架構的後繼者,第一個使用這架構的是Willamette核心,於2000年推出。Willamette是第一代奔騰IV處理器所用的核心,而全部的奔騰 IV處理器都是使用Netburst微架構。2001年推出的Foster(至強處理器)也是使用本架構,同時基於奔騰IV的賽揚、賽揚 D,以及雙核心的奔騰 D、奔騰 Extreme Edition都是使用本架構。
立足於性能而設計的英特爾NetBurst微架構將頻率提升超過了40%,雖然IPC值較低,但由於頻率的增加彌補了不足(性能=頻率×IPC),並且為最終用戶提供了更高的整體性能。和P6微架構一樣,英特爾NetBurst微架構憑藉無序推測執行,儘管分支預測算法相當精確,但也不可能100%正確。
 英特爾架構
英特爾架構為了使由於分支誤預測而引起的損失降到最低並使IPC均值最大化,採用擴展深度流水線技術的Intel NetBurst微架構極大地減小了分支預測錯誤的數量,並提供了從這些錯誤恢復的快速方法。為了能使誤預測引起的損失最小,英特爾NetBurst微架構實現了高級動態執行引擎和一個執行跟蹤快取。
不過值得一提的是,英特爾NetBurst微架構中使用了超流水線技術,這使得流水線的深度相比P6微處理器體系結構的提高了一倍,不過在後來的實際套用中表明提高流水線長度之後會令執行效率大幅度降低,
能夠彌補這個問題的辦法只能是再次提高主頻和增加二級快取容量。
不過由於當時處理器工藝製程的限制,導致處理器的主頻的可提升空間越來越小, 與此同時巨大的快取容量也是一個負擔,這不僅提高了成本,也令發熱量驟升。這一點使得英特爾必須要及時地對處理器微架做出新的,根本性地調整。
Core微架構
由於NetBurst架構已經無法滿足未來處理器發展的需要,所以英特爾於2006年推出了具有革新意義的Core微架構。
1.流水線效率大幅度提升
主頻至上的處理器研發思路顯然已經被淘汰。Core微架構的處理器將超流水線縮短到14級,這將大幅度提升整體效率。此外Core微架構採用了四組指令編譯器,就是指能夠在單一頻率周期內編譯四個x86指令。這四組指令編譯器由三組簡單編譯器(Simple Decoder)與一組複雜編譯器(Complex Decoder)組成。四組指令編譯器中,僅有複雜編譯器可處理最多由四個微指令所組成的複雜x86指令。如果不幸碰到非常複雜的指令,複雜編譯器就必須呼叫微碼循序器(Microcode Sequencer),以便取得微指令序列。
為了配合超寬的編譯單元,Core微架構的指令讀取單元在一個頻率周期內,從第一階指令快取中,抓取六個x86指令至指令編譯緩衝區(Instruction Queue),判定是否有符合宏指令融合的配對,然後再將最多五個x86指令,交派給四組指令編譯器。四組指令編譯器在每個頻率周期中,發給保留站(Reservation Station)四個編譯後的微指令,保留站再將存放的微指令交派(dispatch)給五個執行單元。
因為x86指令集的指令長度、格式與定址模式都相當混亂,導致x86指令解碼器的設計是非常困難的。但是如今的局面已經有所改變,一方面是高主頻對於四組精簡結構有著很大的依賴性,另一方面是其它輔助性技術也能很大程度上彌補解決定址模式混亂的難題。毫無疑問,英特爾的這一創舉將是在處理器核心架構設計上具有里程碑意義的。
2.全新的整數與浮點單元
從P6到NetBurst架構,整數與浮點單元的變化還是相當明顯,不過Core微架構的變化也同樣不小,只是部分關鍵技術又改回P6架構時代的設計。Core具備了3個64bit的整數執行單元,每一個都可以單獨完成的64位整數運算操作。
能夠獨立完成64bit整數運算對英特爾 x86處理器來說還是頭一回,這也讓Core得以走在了競爭對手的前列。此外,64bit的整數單元使用彼此獨立的數據連線埠,因此Core能夠在一個周期內同時完成3組64bit的整數運算。極強的整數運算單元使得Core在包括遊戲、伺服器項目、移動等方面都能夠發揮廣泛而強大的作用。
在以往的NetBurst架構中,浮點單元的性能很一般,Core構架針對這個問題進行了不小的改進。Core構架擁有2個浮點執行單元同時處理向量和標量的浮點運算,其中一個浮點單元執行負責加減等簡單的處理,而另一個浮點單元則執行負責乘除等運算。儘管不能說Core構架令浮點性能有很大幅度的提升,但是其改進效果還是顯而易見的。
3.數據預讀機制與快取結構
Core微架構的預讀取機制還有更多新特性。數據預取單元經常需要在快取中進行標籤查找。為了避免標籤查找可能帶來的高延遲,數據預取單元使用存儲接口進行標籤查找。存儲操作在大多數情況下並不是影響系統性能的關鍵,因為在數據開始寫入時,處理器即可以馬上開始進行下面的工作,而不必等待寫入操作完成。快取/記憶體子系統會負責數據的整個寫入到快取、複製到主記憶體的過程。
此外,Core架構使用了Smart Memory Access算法,這將幫助處理器在前端匯流排與記憶體傳輸之間實現更高的效率。
Core架構的快取系統也令人印象深刻。雙核心Core架構的二級快取容量高達4MB,且兩個核心共享,訪問延遲僅12到14個時鐘周期。每個核心還擁有32KB的一級指令快取和一級數據快取,訪問延遲僅僅3個時鐘周期。從 NetBurst架構開始引入的追蹤式快取(Trace Cache)在 Core架構中消失了。NetBurst 架構中的追蹤式快取的作用與常見的指令快取相類似,是用來存放解碼前的指令的,對NetBurst架構的長流水線結構非常有用,而Core架構回歸相對較短的流水線之後,追蹤式快取也隨之消失。
Nehalem微架構
經歷Core微架構的輝煌之後,英特爾再接再厲,於2008年末推出了新的Nehalem微架構, 它基本是建立在Core微架構的骨架上,外加增添了SMT、3層Cache、TLB和分支預測的等級化、IMC、QPI和支持DDR3等技術,比起從Pentium4的NetBurst架構到Core 微架構的較大變化來說,從Core微架構到Nehalem微架構的基本核心部分的變化則要小一些。
1.QPI匯流排技術
Nehalem架構使用的QPI匯流排是基於數據包傳輸(packet-based)、高頻寬、低延遲的點到點互連技術(point to point interconnect),速度達到6.4GT/s(每秒可以傳輸6.4G次數據)。每一條連線(link)是20bit位寬的接口,使用高速的差分信號(differential signaling)和專用的時鐘通道(dedicated clock lane),這些時鐘通道具有失效備援(failover)。QPI數據包是80bit的長度,傳送需要用4個周期。儘管數據包是80bit,但只有64bit是用於數據,其它的數據位則是用於流量控制、CRC和其它一些目的。這樣,每條連線就一次傳輸16bit(2Byte)的數據,其餘的位寬則是用於CRC。由於QPI匯流排可以雙向傳輸,那么一條QPI匯流排連線理論最大值就可以達到25.6GB/s(2×2B×6.4GT/s)的數據傳送。單向則是12.8GB/s。(更詳細資訊參考“快速通道互聯QPI”詞條)
2.IMC整合記憶體控制器
Nehalem架構的IMC(integrated memory controller,整合記憶體控制器),可以支持3通道的DDR3記憶體,運行在1.33GT/s(DDR3-1333),這樣總共的峰值頻寬就可以達到32GB/s。不過還並不支持FB-DIMM,要Nehalem EX(Beckton)才有可能會支持FB-DIMM(Fully Buffered-DIMM,全緩衝記憶體模組)。每通道的記憶體都能夠獨立操作,控制器需要亂序執行來降低(掩蓋)延遲。(更詳細資訊參見整合記憶體控制器詞條)
3.SMT
同步多執行緒(Simultaneous Multi-Threading,SMT)技術又重新回歸到了Nehalem架構,這最早出現在130納米的奔騰IV上。對於打開了SMT的處理器來說,將會遭受到更多的命中失敗,並需要使用更多的頻寬。所以Nehalem比奔騰IV是更適合使用SMT的。
Nehalem的同步多執行緒(Simultaneous Multi-Threading,SMT)是2-way的,每核心可以同時執行2個執行緒。對於執行引擎來說,在多執行緒任務的情況下,就可以掩蓋單個執行緒的延遲。SMT功能的好處是只需要消耗很小的核心面積代價,就可以在多任務的情況下提供顯著的性能提升,比起完全再添加一個物理核心來說要划算得多。這個和以前P4的HT技術是一樣的,但比較起來,Nehalem的優勢是有更大的快取和更大的記憶體頻寬,這樣就更能夠有效的發揮。按照英特爾的說法,Nehalem的SMT可以在增加很少能耗的情況下,讓性能提升20-30%。(更詳細資訊參見同步多執行緒技術詞條)
4.全新設計的快取體系
Nehalem的每個核心有一個私有的通用型L2,是8路聯合的256KB,訪問速度相當快。Nehalem的L2相對於其L1D來說,既不是包含式(inclusive)也不是獨占式(exclusive),可以在兩個核心的私有快取(L1D和L2)之間傳遞數據,儘管不能夠達到全速。
與Core微架構相比,Nehalem新增加了一層L3快取,這是為了多個核心共享數據的需要(Nehalem-EX具有8個核心),也因此這個L3的容量很大。從架構上看,Nehalem架構的處理器所配備的16路聯合、8MB的L3對於前兩級來說,是完全包含式的,並且由4個核心共享。(更詳細資訊參見新增快取層級體系詞條)
發展步調
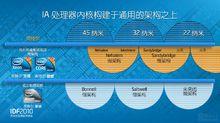
英特爾長期以來不懈遵循摩爾定律,一直是引領行業創新的排頭兵。通過對處理器架構的不斷創新,這種驚人的創新速度不僅提升了處理器的性能,還提供了新的特性和能力,最終滿足了用戶日益增長的需求。我們十分關注這種持續的發展,行業需要能夠以更快且更加可預測的創新步伐來提供平台,這些平台的特點就是更快、能夠實現更多連線、值得信賴、個性化且能夠帶來出色的計算體驗。憑藉行業領先的晶片專業知識,以及將為未來十年及以後提供強勁增長動力的架構設計能力,英特爾公司已邁出了協調且日益加快的架構創新步伐。
指什麼
發展步調是指英特爾公司的戰略,即大約每兩年推出一款新的微體系結構和新一代矽製程技術。
英特爾公司在矽製程技術上的不斷創新使電晶體密度約每兩年就要翻一番,這就為處理器設計師提供了強大的設計靈活性來設計出更出色的產品。過去,設計靈活性一直被用來在降低功耗的同時提供更卓越的性能和特性。展望未來,用戶不斷增長的需求將要求更加快速地提升性能,並跨越模糊的使用界限實現各種能力的融合。因此,這就需要一種能夠跨越廣泛使用領域進行擴展的解決方案架構,而這一目標只能通過全行業的創新來實現。英特爾 架構和晶片發展步調模式可提供強大的創新動力,不但能夠以快速、協調的步伐推動全新處理器架構和晶片組的發展,而且還能成為平台級行業創新的“催化劑”,提供高能效表現的種種優勢。
特徵
發展步調所堅持的原則基於英特爾公司所謂的晶片和微體系結構“tick-tock”模式。該模式將提供一款橫跨所有規模市場的通用處理器架構。每一“tick”代表矽壓縮頻率(beat rate),並且每一“tick”都有一個相對應的“tock”,後者代表新微體系結構的設計,大約每兩年更新一次。英特爾公司全球範圍的設計方法和大量的紀律是其發展步調原則的奠基石,該發展步調支持英特爾公司提供對超越個別產品能力的處理器和平台的創新。
一個很好的實例即英特爾公司為提供出色的伺服器性能而擴展筆記本電腦架構所實現的巨大飛躍。英特爾在其處理器中實現了這一巨大飛躍。英特爾酷睿(TM)2雙核處理器基於英特爾酷睿(TM) 微體系結構。一個物理處理器中內置了兩個完整的執行核心,它們以相同的頻率運行,可為筆記本電腦以及台式機提供行業領先的能效表現。英特爾酷睿(TM) 微體系結構的計算元件被形容為一個整合的核心,它支持架構和技術的最佳化,以滿足突破性性能和能效的使用需求。英特爾將一如既往地為伺服器、台式機和移動產品提供基於多核處理器技術的通用可擴充架構。最終,經過不斷創新,一款專門針對性能功耗比和擴展的能力進行最佳化的架構誕生,由此將推動基於通用晶片基礎的“tick-tock”發展步調中晶片組、互連、記憶體以及平台等的一系列創新。
兌現發展步調承諾的核心是全球多個設計團隊能夠並肩作戰。這就要求各團隊之間進行有效協調,以最少的重合和冗餘實現彼此方法和計畫的相互補充。英特爾還支持軟體社區和一些大學開發多執行緒套用,並致力於促使行業價值鏈廠商充分感受創新步伐帶來的優勢。這包括推進標準活動、行業與監管環境的契合以及為滿足用戶需求所做出的真正努力。
早在 20 世紀 90 年代初,英特爾公司憑藉其 32 位英特爾 處理器架構(IA32)贏得行業領先地位,從而確立了一個行業標準,並對英特爾奔騰處理持領先地位。1993 年,英特爾奔騰處理器的推出標誌著第五代台式機處理器的問世。隨後,一系列創新緊隨其至:1995 年,英特爾 高能奔騰處理器推出;1997 年,英特爾 奔騰 II 處理器推出;1999 年,英特爾 奔騰 III 處理器推出;2000 年,基於英特爾 NetBurst 架構的英特爾 奔騰 4 處理器推出。同年,英特爾還推出了英特爾至強處理器。
2003 年,首款基於 90 納米製程技術的英特爾奔騰M 處理器的推出標誌著向高能效表現的轉奔騰 M 處理器的推出標誌著向高能效表現的轉變,以性能功耗比作為衡量標準,具有擴展的能力。這些處理器的推出均基於晶片創新發展步調,並不一定伴隨有設計流程和方法。
2006 年,英特爾推出全新英特爾酷睿(TM) 微體系結構,它為英特爾 架構台式機、筆記本電腦和主流伺服器多核處理器奠定了堅實的基礎。此次創新基於 65 納米製程技術,是發展步調中架構設計和晶片創新掛鈎的發展道路上的首款微體系結構。英特爾 架構和晶片發展步調有幾個方面與業內其他廠商不同。這些方面包括:
一個面向所有大規模市場並針對性能、能力和能效而最佳化的微體系架構;
風行設計再利用原則而無需等待晶片密度可用的聯合設計團隊,但這卻推動向共同目標及設計目標邁進;
關注利用並聯的晶片組和行業價值鏈廠商的發展實現平台級創新,快速增強平台能力。
因此,英特爾的發展步調模式進一步鞏固了其它晶片創新的可信基礎,以便按照將推動行業範圍內的創新和增長的步伐提供行業領先的高能效表現架構。
英特爾公司的“tick-tock”發展戰略
面向多核處理器的“tick-tock”發展步調的實施一直基於整合的核心,後者是基本計算元件,能夠提供目標性能和能力以及出色的能效。
因此,“Tick-tock”就需要同步化設計流程來實現下列創新,符合橫跨各市場領域的用戶價值:
更低功耗; 多執行緒性能;特性和能力;增強模組性和靈活性。
執行的關鍵在於將這一創新步伐帶給行業創新者,以便為用戶帶來真正的利益。所以,英特爾公司調整了關乎整體行業領先情況的發展步調:
每兩年更新一次矽製程技術(“ticks”),同時,每兩年更新一次架構( “tocks”);
多個經驗豐富的設計團隊,同時致力於保持設計目標和重要事件的同步,並確定流程接觸點來最大限度地提高效率;
對技術能力和特性的頻繁“培訓”也提供了適應改變的能力。
總結
通過不斷遵循摩爾定律,英特爾幾乎每兩年就將一個矽核上的電晶體數量增加一倍。雙倍的電晶體數量提供了極大的設計靈活性,進而可提升性能、擴展能力並提高能效。在最新一代英特爾 酷睿(TM) 微體系結構產品中,通過增加核心數量這一設計靈活性帶來了巨大的性能提升,為全新改進的套用帶來卓越的特性/能力,並大幅降低了功耗。英特爾正著眼於可信且日益加快的創新步伐,大約每兩年就要兌現一款新的微體系結構和一次矽製程技術改進。
英特爾的“tick-tock”架構和晶片發展步調模式為業界和用戶帶來了巨大優勢,新的能力和解決方案將滿足他們日益增長的需求。在英特爾,我們的宗旨是以摩爾定律的創新速度兌現架構創新。
