原理
DMA 傳輸將數據從一個地址空間複製到另外一個地址空間。當CPU 初始化這個傳輸動作,傳輸動作本身是由 DMA 控制器來實行和完成。典型的例子就是移動一個外部記憶體的區塊到晶片內部更快的記憶體區。像是這樣的操作並沒有讓處理器工作拖延,反而可以被重新排程去處理其他的工作。DMA 傳輸對於高效能 嵌入式系統算法和網路是很重要的。
 DMA
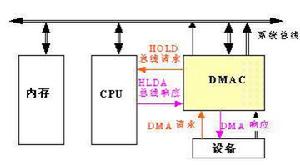
DMA在實現DMA傳輸時,是由DMA控制器直接掌管匯流排,因此,存在著一個匯流排控制權轉移問題。即DMA傳輸前,CPU要把匯流排控制權交給DMA控制器,而在結束DMA傳輸後,DMA控制器應立即把匯流排控制權再交回給CPU。一個完整的DMA傳輸過程必須經過DMA請求、DMA回響、DMA傳輸、DMA結束4個步驟。
請求
CPU對DMA控制器初始化,並向I/O接口發出操作命令,I/O接口提出DMA請求。
回響
DMA控制器對DMA請求判別優先權及禁止,向匯流排裁決邏輯提出匯流排請求。當CPU執行完當前匯流排周期即可釋放匯流排控制權。此時,匯流排裁決邏輯輸出匯流排應答,表示DMA已經回響,通過DMA控制器通知I/O接口開始DMA傳輸。
傳輸
DMA控制器獲得匯流排控制權後,CPU即刻掛起或只執行內部操作,由DMA控制器輸出讀寫命令,直接控制RAM與I/O接口進行DMA傳輸。
在DMA控制器的控制下,在存儲器和外部設備之間直接進行數據傳送,在傳送過程中不需要中央處理器的參與。開始時需提供要傳送的數據的起始位置和數據長度。
結束
當完成規定的成批數據傳送後,DMA控制器即釋放匯流排控制權,並向I/O接口發出結束信號。當I/O接口收到結束信號後,一方面停 止I/O設備的工作,另一方面向CPU提出中斷請求,使CPU從不介入的狀態解脫,並執行一段檢查本次DMA傳輸操作正確性的代碼。最後,帶著本次操作結果及狀態繼續執行原來的程式。
由此可見,DMA傳輸方式無需CPU直接控制傳輸,也沒有中斷處理方式那樣保留現場和恢復現場的過程,通過硬體為RAM與I/O設備開闢一條直接傳送數據的通路,使CPU的效率大為提高。
傳送方式
DMA技術的出現,使得外圍設備可以通過DMA控制器直接訪問記憶體,與此同時,CPU可以繼續執行程式。那么DMA控制器與CPU怎樣分時使用記憶體呢?通常採用以下三種方法:(1)停止CPU訪記憶體;(2)周期挪用;(3)DMA與CPU交替訪問記憶體。
停止CPU訪問記憶體
當外圍設備要求傳送一批數據時,由DMA控制器發一個停止信號給CPU,要求CPU放棄對地址匯流排、數據匯流排和有關控制匯流排的使用權。DMA控制器獲得匯流排控制權以後,開始進行數據傳送。在一批數據傳送完畢後,DMA控制器通知CPU可以使用記憶體,並把匯流排控制權交還給CPU。圖(a)是這種傳送方式的時間圖。很顯然,在這種DMA傳送過程中,CPU基本處於不工作狀態或者說保持狀態。
![DMA[直接存儲器訪問]](/img/1/54f/nBnauM3X0gDOyUTM4UTO5ETM2UTM1QDN5MjM5ADMwAjMwUzL1kzL3IzLt92YucmbvRWdo5Cd0FmL0E2LvoDc0RHa.jpg) DMA[直接存儲器訪問]
DMA[直接存儲器訪問]優點: 控制簡單,它適用於數據傳輸率很高的設備進行成組傳送。
缺點: 在DMA控制器訪內階段,記憶體的效能沒有充分發揮,相當一部分記憶體工作周期是空閒的。這是因為,外圍設備傳送兩個數據之間的間隔一般總是大於記憶體存儲周期,即使高速I/O設備也是如此。例如,軟碟讀出一個8位二進制數大約需要32us,而半導體記憶體的存儲周期小於0.5us,因此許多空閒的存儲周期不能被CPU利用。
周期挪用
當I/O設備沒有DMA請求時,CPU按程式要求訪問記憶體;一旦I/O設備有DMA請求,則由I/O設備挪用一個或幾個記憶體周期。
![DMA[直接存儲器訪問]](/img/1/6c6/nBnauM3X4MTN3UTO3UTO5ETM2UTM1QDN5MjM5ADMwAjMwUzL1kzL1UzLt92YucmbvRWdo5Cd0FmLyE2LvoDc0RHa.jpg) DMA[直接存儲器訪問]
DMA[直接存儲器訪問]這種傳送方式的時間圖如下圖(b):
I/O設備要求DMA傳送時可能遇到兩種情況:
(1)此時CPU不需要訪內,如CPU正在執行乘法指令。由於乘法指令執行時間較長,此時I/O訪內與CPU訪內沒有衝突,即I/O設備挪用一二個記憶體周期對CPU執行程式沒有任何影響。
(2)I/O設備要求訪內時CPU也要求訪內,這就產生了訪內衝突,在這種情況下I/O設備訪內優先,因為I/O訪內有時間要求,前一個I/O數據必須在下一個訪問請求到來之前存取完畢。顯然,在這種情況下I/O 設備挪用一二個記憶體周期,意味著CPU延緩了對指令的執行,或者更明確地說,在CPU執行訪內指令的過程中插入DMA請求,挪用了一二個記憶體周期。 與停止CPU訪內的DMA方法比較,周期挪用的方法既實現了I/O傳送,又較好地發揮了記憶體和CPU的效率,是一種廣泛採用的方法。但是I/O設備每一次周期挪用都有申請匯流排控制權、建立線控制權和歸還匯流排控制權的過程,所以傳送一個字對記憶體來說要占用一個周期,但對DMA控制器來說一般要2—5個記憶體周期(視邏輯線路的延遲而定)。因此,周期挪用的方法適用於I/O設備讀寫周期大於記憶體存儲周期的情況。
DMA與CPU交替訪問記憶體
如果CPU的工作周期比記憶體存取周期長很多,此時採用交替訪內的方法可以使DMA傳送和CPU同時發揮最高的效率。
這種傳送方式的時間圖如下:
![DMA[直接存儲器訪問]](/img/6/565/nBnauM3XyMTN0YTM3UTO5ETM2UTM1QDN5MjM5ADMwAjMwUzL1kzLwMzLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) DMA[直接存儲器訪問]
DMA[直接存儲器訪問]此圖是DMA與CPU交替訪內的詳細時間圖.假設CPU工作周期為1.2us,記憶體存取周期小於0.6us,那么一個CPU周期可分為C1和C2兩個分周期,其中C1專供DMA控制器訪內,C2專供CPU訪內。
這種方式不需要匯流排使用權的申請、建立和歸還過程,匯流排使用權是通過C1和C2分時制的。CPU和DMA控制器各自有自己的訪內地址暫存器、數據暫存器和讀/寫信號等控制暫存器。在C1周期中,如果DMA控制器有訪內請求,可將地址、數據等信號送到匯流排上。在C2周期中,如CPU有訪內請求,同樣傳送地址、數據等信號。事實上,對於匯流排,這是用C1,C2控制的一個多路轉換器,這種匯流排控制權的轉移幾乎不需要什麼時間,所以對DMA傳送來講效率是很高的。
這種傳送方式又稱為“透明的DMA”方式,其來由是這種DMA傳送對CPU來說,如同透明的玻璃一般,沒有任何感覺或影響。在透明的DMA方式下工作,CPU既不停止主程式的運行,也不進入等待狀態,是一種高效率的工作方式。當然,相應的硬體邏輯也就更加複雜。
![DMA[直接存儲器訪問]](/img/9/66b/nBnauM3X2gjNzUTN3UTO5ETM2UTM1QDN5MjM5ADMwAjMwUzL1kzLxIzLt92YucmbvRWdo5Cd0FmLxE2LvoDc0RHa.jpg) DMA[直接存儲器訪問]
DMA[直接存儲器訪問]