
定義
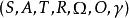 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程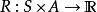 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程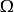 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程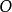 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程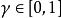 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程離散時間POMDP模擬代理與其環境之間的關係。 形式上,POMDP是7元組,其中
是一組狀態,
是一組動作,
是狀態之間的一組條件轉移機率,
是獎勵函式。
是一組觀察,
是一組條件觀察機率,
是折扣因子。
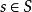 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程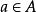 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程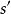 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程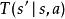 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程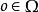 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程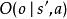 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程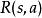 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程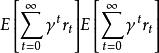 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程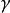 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程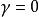 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程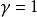 部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程在每個時間段,環境處於某種狀態 .The agent在A中採取動作 ,這會導致轉換到狀態 的環境機率為 。同時,代理接收觀察 ,它取決於環境的新狀態,機率為 。最後,代理接收獎勵 等於 。然後重複該過程。目標是讓代理人在每個時間步驟選擇最大化其預期未來折扣獎勵的行動: 。折扣係數 決定了對更遠距離的獎勵有多大的直接獎勵。當 時,代理人只關心哪個動作會產生最大的預期即時獎勵;當 時,代理人關心最大化未來獎勵的預期總和。
近似POMDP解決方案
在實踐中,POMDP通常在計算上難以解決,因此計算機科學家已經開發了近似POMDP解決方案的方法。基於格線的算法包括一種近似解決方案技術。 在該方法中,針對置信空間中的一組點計算值函式,並且使用內插來確定針對不在該組格線點中遇到的其他信念狀態採取的最優動作。 最近的工作利用了採樣技術,泛化技術和問題結構的利用,並將POMDP解決擴展到具有數百萬個州的大型域。例如,基於點的方法對隨機可達信念點進行抽樣,以將規劃約束到信念空間中的相關區域。還探索了使用PCA降低尺寸的方法。
討論
由於代理不直接觀察環境的狀態,因此代理必須在真實環境狀態的不確定性下做出決策。然而,通過與環境互動並接收觀察,代理可以通過更新當前狀態的機率分布來更新其對真實狀態的信念。這種性質的結果是最佳行為通常可能包括信息收集行動,這些行動純粹是因為它們改善了代理人對當前狀態的估計,從而使其能夠在未來做出更好的決策。
將上述定義與馬爾可夫決策過程的定義進行比較是有益的。 MDP不包括觀察集,因為代理總是確切地知道環境的當前狀態。或者,通過將觀察組設定為等於狀態組並定義觀察條件機率以確定性地選擇對應於真實狀態的觀察,可以將MDP重新表述為POMDP。
