
基本信息
數理統計學的一個方面,研究當總體假定稍有變動及記錄數據有失誤時,統計方法的適應性問題。一個統計方法在實際套用中要有良好的表現,需要兩個條件:一是該方法所依據的條件與實際問題中的條件相符;二是樣本確是隨機的,不包含過失誤差,如記錄錯誤等。但實際套用中這些條件很難嚴格滿足,比方說,原來在提出該方法時是依據總體分布為常態分配的假定,但實際問題中總體的分布與正態略有偏離;或在大量的觀測數據中存在受到過失誤差影響的“異常數據”等。如果在這種情況下,所用統計方法的性能僅受到少許影響,就稱它具有穩健性。
穩健性一詞是G.E.P.博克斯在1953年提出的,但關於穩健性的思想,可追溯到20世紀初期,有些穩健性統計方法,如下文提到的修削平均,使用還要早些。從1960年J.W.圖基發表他的工作以來,這方面的工作得到更多統計學家的重視。1964年P.J.休伯發表了他關於M估計的工作,進一步推動了它的發展。到1980年為止關於這方面的工作,已由休伯寫成專著。
對總體分布的穩健性設當總體分布為F時,統計方法T的某項性能指標為AT(F),例如,T可以是F的數學期望的估計,而AT(F)為T的方差;若在某項實際套用中,真實的總體分布為F,而該項性能指標取值AT(F)。以距離p(F,F)刻畫F與F的差異,比如,p(F,F)可以是|F(x)-F(x)|對x取的最大值。如果當 P(F,F)充分小時,|AT(F)-AT(F)|也充分小,則稱方法T具有對總體分布的穩健性。可見,統計方法的穩健性與考慮的性能指標有關,也與分布的距離p(F,F)的定義有關。因此,怎樣定義適當的距離p(F,F),研究各種距離的性質及相互關係,怎樣選擇適當的性能指標作為衡量穩健性的依據等,是穩健統計研究的一方面的內容。
通常使用的很多統計方法,是在總體分布為正態的前提下導出的,理論上也證明了,在正態總體的情況下這些方法具有某種優良的性能。但在大多數具體問題中,正態假定往往只是近似地滿足,若一個統計方法缺乏穩健性,則它理論上可能有某種優良性能,而在實際套用中卻表現很差,甚至面目全非。因此,穩健性的研究是一個有很大實際意義的課題。
圖基在1960年提供了這樣的例子:設x1,x2,…,xn是抽自正態總體N(μ,σ)的樣本,要估計σ,常用的估計量
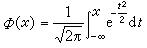 穩健統計
穩健統計是標準常態分配函式,則可以算出,當ε=0.05時,捛n和dn的方差比的極限超過2。就是說,即使像0.05這么小的污染程度也足以使捛n遠不如dn的一半。因此捛n作為σ的估計穩健性較差,而相對地說dn的穩健性就較捛n好。
理論研究表明:像F檢驗(見假設檢驗、方差分析)之類的與總體方差有關的統計方法,其性能多與總體的正態性有較強的依賴關係,穩健性較差;而與總體均值有關的統計方法,如t檢驗之類,穩健性相對說來要好一些。
對異常數據的穩健性由於在大量次數的試驗或觀測中,很難完全避免出現個別疏忽,因此,要使統計方法有較好的穩健性,就必須要求,它所依據的統計量不受個別異常數據的太大影響。一個典型的例子是用樣本均值或樣本中位數(見統計量)去估計常態分配的均值,前者受個別異常數據的影響較大,而後者則幾乎不受到影響,故從穩健性角度看,後者優於前者。介於兩者之間的有所謂修削平均,即給定自然數k<n/2(n為樣本大小),把全部樣本x1,x2,…,xn中最大的k個和最小的k個捨棄,餘下的n-2k個的算術平均值稱為修削平均值,k愈大,修削愈多,如果有少量異常數據混入,則在修削時被捨棄了,因而不致造成危害。這是一個較早的穩健統計方法,但被廣泛使用。
其他信息
為獲得對異常數據的穩健性,有兩個途徑:一是設計出有效的方法以發現數據中的異常值,從而把它們剔除。這已成為數理統計學中的一個重要課題,積累了不少成果。另一個途徑是設計這樣的方法,使樣本中的個別數據不致對最終結果有過大的影響,如用最小二乘法求參數估計時,是根據使偏差平方和為最小的原則,從而若有個別偏差特大的數據,其對結果的影響很大,故基於最小二乘法的統計方法的穩健性一般較差,若改用絕對偏差和最小的原則,則穩健性有所改善。
穩健性與效率使統計方法具有穩健性,在一定的意義上可以看成是一種“保險”:付出一定的保險費,以避免遭受重大損失,保險費就表現為方法在效率上的降低。例如,用樣本中位數估計常態分配均值,在穩健性上比用樣本均值好;但如情況沒有異常,即總體分布確為正態,並且無異常數據,則樣本中位數以方差大小衡量的效率,約只有樣本均值的三分之二。穩健統計的一個任務,就是設計有穩健性的統計方法,而使其在效率上的損失儘可能小。
與非參數統計的關係非參數統計方法往往有較好的穩健性,而一些穩健統計方法常要用到非參數性質的統計量,因此二者關係密切。但從性質上看二者是不同的:非參數統計中,對總體分布的假定很少;而穩健統計則一般是從一個確定的參數性模型(如正態模型)出發,考慮當模型條件有少許擾動時的後果。因此,穩健統計本質上屬於參數統計的範疇。
參考書目
P.J. Huber,Robust Statistics,John Wiley & Sons,New York,1981.
