
基本介紹
混合線性模型是20世紀80年代初針對統計資料的非獨立性而發展起來的。由於該模型的理論起源較多,根據所從事的領域、模型用途,又可稱為 多 水平模型(Multilevel,MLM)、隨機係數模型(Random Coefficients,RCM)、等級線性模型(Hierarchical Linear,HLM)等。甚至和廣義估計方程也有很大的交叉。這種模型充分考慮到數據聚集性的問題,可以在數據存在聚集性的時候對影響因素進行正確的估計和假設檢驗。不僅如此,它還可以對變異的影響因素加以分析,即哪些因素導致了數據間聚集性的出現,哪些又會導致個體間變異增大。由於該模型成功地解決了長期困擾統計學界的數據聚集性問題,20年來已經得到了飛速的發展,也成為SPSS等權威統計軟體的標準統計分析方法之一 。
在傳統的線性模型(y=xb+e)中,除X與Y之間的線性關係外,對反應變數Y還有三個假定:①正態性,即Y來自常態分配總體;②獨立性,Y的不同觀察值之間的相關係數為零;③方差齊性,各Y值的方差相等。但在實際研究中,經常會遇到一些資料,它們並不能完全滿足上述三個條件。例如,當Y為分類反應變數時,如性別分為男、女,婚姻狀態為已婚、未婚,學生成績是及格、不及格等,不能滿足條件①。當Y具有群體特性時,如在抽樣調查中,被調查者會來自不同的城市、不同的學校,這就形成一個層次結構,高層為城市、中層為學校、低層為學生。顯然,同一城市或同一學校的學生各方面的特徵應當更加相似。也就是基本的觀察單位聚集在更高層次的不同單位中,如同一城市的學生數據具有相關性,不能滿足條件②。當自變數X具有隨機誤差時,這種誤差會傳遞給Y,使得Y不能滿足條件③。
如果對不滿足正態性、獨立性、方差齊性三個適用條件的資料採用傳統的分析方法,對所有樣本一視同仁,建立回歸方程,就會帶來如下問題:
(1)參數估計值不再具有最小方差線性無偏性。
(2)會嚴重低估回歸係數的標準誤差。
(3)容易導致估計值過高,使常用的檢驗失效,從而增加統計檢驗I型錯誤發生的機率。
如果我們對不同的群體分別建立各自的回歸模型,當群體數較少,群體內樣本容量較大,傳統的分析方法可能是有效的。或者,我們的興趣僅在於對這些群體分別做一些統計推斷時,也適合用這種方法。但是如果我們把這些群體看成是從總體中抽樣來的一個樣本(例如多階段抽樣和重複測度數據),並想分析不同群體之間的總體差異,那么簡單地使用傳統的統計方法是不夠的。同樣,如果一些群體包含的樣本容量較少,對這些群體做出的推斷也不可靠。因此,我們需要把這些群體看成是從總體抽樣來的樣本,並使用樣本總體的信息來進行推斷 。
本文所討論的混合線性模型既保留了傳統線性模型中的正態性假定條件,又對獨立性和方差齊性不作要求,從而擴大了傳統線性模型的適用範圍 。
混合線性模型的結構
具有固定效應的一般線性模型的結構為:
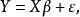 混合線性模型
混合線性模型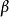 混合線性模型
混合線性模型 混合線性模型
混合線性模型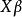 混合線性模型
混合線性模型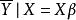 混合線性模型 混合線性模型
混合線性模型 混合線性模型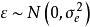 混合線性模型 混合線性模型
混合線性模型 混合線性模型式中的Y表示反應變數的測量值向量,X為固定效應自變數的設計矩陣, 是與X對應的固定效應參數向量, 為剩餘誤差向量。 為在X條件下的Y的平均值向量,即 。 假定為獨立、等方差及均值為0的常態分配,即 用最小二乘法求參數 的估計值B。
混合線性模型將一般線性模型擴展為:
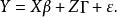 混合線性模型
混合線性模型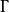 混合線性模型
混合線性模型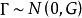 混合線性模型 混合線性模型 混合線性模型
混合線性模型 混合線性模型 混合線性模型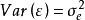 混合線性模型
混合線性模型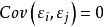 混合線性模型
混合線性模型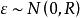 混合線性模型 混合線性模型
混合線性模型 混合線性模型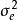 混合線性模型
混合線性模型式中Z為隨機效應變數構造的設計矩陣,其構成方式與X相同。 為隨機效應參數向量,服從均值向量為0、方差協方差矩陣為G的常態分配,表示為 。 為隨機誤差向量,放寬了對 的限制條件,其元素不必為獨立同分布,即對E沒有 及 的假定。用符號表示隨機誤差向量 ,不要求 的方差、協方差矩陣R的主對角元素為 、非主對角元素為0。同時假定Cov(G,R)=0,即G與R間無相關關係。這時Y的方差、協方差矩陣變為:
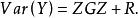 混合線性模型
混合線性模型Y的期望值為:
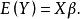 混合線性模型
混合線性模型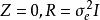 混合線性模型
混合線性模型當 時,混合線形模型轉變為一般線形模型 。
