
公式
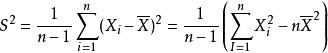 樣本方差
樣本方差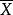 樣本方差
樣本方差樣本方差的公式為其中為樣本均值。
簡介
在許多實際情況下,人口的真實差異事先是不知道的,必須以某種方式計算。 當處理非常大的人口時,不可能對人口中的每個物體進行計數,因此必須對人口樣本進行計算。樣本方差也可以套用於從該分布的樣本的連續分布的方差的估計。
樣本方差的無偏性
我們從一個樣本取n個值y,...,y,其中n <N,並根據這個樣本估計方差。直接取樣本數據的方差給出平均偏差的平均值:
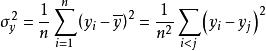 樣本方差
樣本方差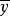 樣本方差
樣本方差這裡, 表示樣本均值。
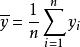 樣本方差
樣本方差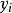 樣本方差 樣本方差
樣本方差 樣本方差 樣本方差 樣本方差 樣本方差
樣本方差 樣本方差 樣本方差由於 是隨機選擇的,所以 和 是隨機變數。 他們的預期值可以通過從群體中的大小為n的所有可能樣本 的集合進行平均來評估。 對於 ,有
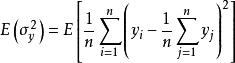 樣本方差
樣本方差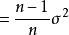 樣本方差 樣本方差
樣本方差 樣本方差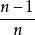 樣本方差 樣本方差
樣本方差 樣本方差因此 給出了基於因子 的人口方差的估計值。 被稱為偏樣本方差。 糾正該偏差之後形成無偏樣本方差:
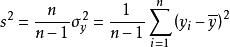 樣本方差
樣本方差估計值可以簡單地稱為樣本方差。 同樣的證明也適用於從連續機率分布中抽取的樣本。
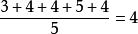 樣本方差
樣本方差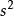 樣本方差
樣本方差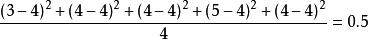 樣本方差
樣本方差例如,n=5個樣本觀測值值為3,4,4,5,4,則樣本均值= , 樣本方差 = 。樣本方差是常用的統計量之一,是描述一組數據變異程度或分散程度大小的指標。
實際上,樣本方差可以理解成是對所給總體方差的一個無偏估計。E(S^2)=DX。
n-1的使用稱為貝塞爾校正(Bessel's correction),也用於樣本協方差和樣本標準偏差(方差平方根)。 平方根是一個凹函式,因此引入負偏差(由Jensen不等式),這取決於分布,因此校正樣本標準偏差(使用貝塞爾校正)有偏差。 標準偏差的無偏估計是一個技術上涉及的問題,儘管對於使用術語n-1.5的常態分配,形成無偏估計。
無偏樣本方差是函式ƒ(y,y)=(y-y) /2的U統計量,這意味著它是通過對群體的兩個樣本統計平均得到的。
樣本方差分布
作為隨機變數的函式,樣本方差本身就是一個隨機變數,研究其分布是很自然的。 在yi是來自常態分配的獨立觀察的情況下,Cochran定理表明s 服從卡方分布:
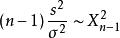 樣本方差
樣本方差所以可求;
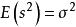 樣本方差
樣本方差和
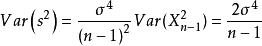 樣本方差
樣本方差如果y獨立同分布,但不一定是常態分配,那么
樣本方差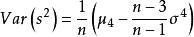 樣本方差
樣本方差如果大數定律的條件對於平方觀測值同樣適用,則s 是σ 的一致估計量。 可以看出,估計的方差趨於零。 在Kenney and Keeping(1951:164),Rose和Smith(2002:264)和Weisstein(n.d.)中給出了漸近等效的公式。
正態總體的樣本均值和樣本方差相互獨立。
