SPSS的快速聚類過程適用於對大樣本進行快速聚類,尤其是對形成的類的特徵(各變數值範圍)有了一定認識時,此聚類方法使用起來更加得心應手。
操作及分析方法
為了使粗通統計分析方法的讀者也能都使用該過程進行聚類分析,我們先以小樣本數據為例說明其操作及分析方法。
例12.3.1對游泳運動員進行分項。為簡化問題,僅以10名運動員的三項測試數據為例。其中變數x1=肩寬/髖寬×100;x2=胸厚/胸圍×100;x3=腿長/身長×100。預計按姿勢分為蝶泳、仰泳、蛙泳、自由式四類。原始數據如表12-13所示。
表12-1310名運動員的三項測試數據
 表12-13
表12-13操作方法分為以下幾步:
(1)首先定義變數、輸人數據。建立聚類工作數據檔案,也稱聚類分析的輸入數據檔案。
(2)按Analyze、Classify、K-Meanscluster順序逐一單擊滑鼠鍵,最後展開對話框,如圖12-20所示。
圖12-20K-Meanscluster對話框
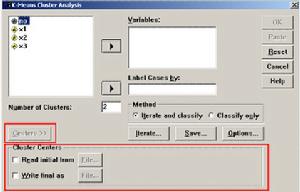 圖12-20 K-Means cluster對話框
圖12-20 K-Means cluster對話框(3)指定分析變數和標識變數
本例中標識每個觀測量的變數是"no"。因此:
選擇主對話框中左面變數表中的"no"。單擊滑鼠鍵使之置於光帶中。
單擊下面一個右箭頭按鈕,使變數名移到"LableCasesby:"下面的矩形框中。
選擇參與聚類分析的數值型變數,單擊上面一個向右箭頭按鈕,使選中的變數名移到右面的"Variables:"下面的矩形框中。
(4)確定分類數
系統默認的分類數為2,顯示在"Numberofcluster"後面的矩形框中。按分析要求應該分為4類,將原數值2改為4。
其他參數全部選用系統默認值,無需繼續操作其他按鈕或圖示按鈕。
(5)選擇聚類方法
在主對話框中的"Method"框中的兩項中可以選擇一種聚類方法。我們選擇系統默認值。(項前圓圈中有黑點的)所涉及的選擇項均使用默認值。
(6)執行Quickcluster命令,方法有兩種:
①單擊按鈕"OK",系統立即執行該命令。
②單去按鈕"Paste",激活"Syntax"窗,將"Quickcluster"命令及由其子命令和所設定的參數組成的程式生成在該窗中。
根據在主對話框中選擇的標識變數、分析變數、和分類數生成以下程式:
QUICKCLUSTER
xlx2x3
/MISSING=LISEWISE
/cRITERIA=cLUSTER(4)MxITER(10)cONVERGE(.02)
/METHOD=kmeans(NOUPDATE)
/PRINTID(no)INITIAL.
③按該窗中的"Run"按鈕,執行窗中的命令程式
(7)顯示在輸出窗中的程式運行結果如下:
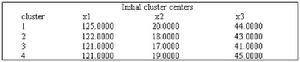
表12-14初始類中心
 快速聚類
快速聚類表12-15各次疊代後類中心的變化
 快速聚類
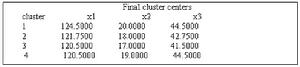
快速聚類表12-16最終的四類的類中心
 快速聚類
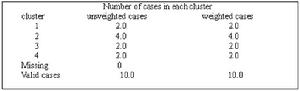
快速聚類表12-17聚類總結
 快速聚類
快速聚類