定義
一個文法是左遞歸的,若我們可以找出其中存在某非終端符號A,最終會推導出來的句型(sentential form)裡面包含以自己為最左符號(left-symbol)的句型。
直接左遞歸
直接左遞歸(Immediate left recursion)以下面的句型規則出現:
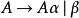 左遞歸
左遞歸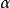 左遞歸
左遞歸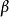 左遞歸
左遞歸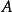 左遞歸
左遞歸這裡 跟 代表不同的非終端符號跟終端符號組成的序列,並且{\displaystyle \beta }不一定要包含 。舉例來說,以下規則
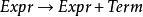 左遞歸
左遞歸就是一個直接左遞歸的例子。 這規則的遞歸下降分析器(recursive descent parser)可能會像這樣:
function Expr()
{
Expr(); match('+'); Term();
}
然後這個遞歸下降分析器在嘗試去解析包含此規則的文法時,會陷入一個無窮的遞歸。
間接左遞歸
間接左遞歸(indirect left recursion)最簡單的形式如下:
 左遞歸
左遞歸 左遞歸
左遞歸 左遞歸
左遞歸這規則可能產生 這種生成。
簡單的說,間接左遞歸就是,並非在一條規則內完成左遞歸,而是在許多條規則之後,於產生的句子最左邊出現了一開始的非終端符號。
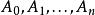 左遞歸
左遞歸更一般化的說法,對非終端符號 ,間接左遞歸被定義為以下的型態:
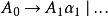 左遞歸
左遞歸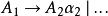 左遞歸
左遞歸 左遞歸
左遞歸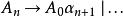 左遞歸
左遞歸 左遞歸
左遞歸這裡的 都是一堆終端與非終端符號的序列。
容納左遞歸
一個包含左遞歸的形式文法不能以簡易的遞歸下降分析器進行語法分析,除非將文法轉變為weakly equivalent的右遞歸形式 (相對的,在LALR分析器裡面則比較偏好左遞歸,因為比起右遞歸來說會使用比較少的堆疊);然而,比較複雜的由上而下(top-down)語法分析器裡面可以藉由使用縮減(by use of curtailment)來實做一般的上下文無關文法。 在2006年, Frost 和 Hafiz 提出一個算法,可以容納包含直接左遞歸生成規則的模糊文法(ambiguous grammers)。在2007年,Frost,Hafiz和Callaghan 將此算法延伸為一個完整的,可以適用並在多項式時間內處理直接或間接左遞歸,而且可以為高度模糊文法接近指數數目的分析樹,產生小一些多項式空間的表示法。這些人後來在Haskell程式語言裡面以這個算法實做了一個的分析器組合(parser combinator)的集合。
移除左遞歸
移除直接左遞歸
一個一般化後移除直接左遞歸的算法如下所述。 這個方法已經有過許多的改進,包括Robert C. Moore所撰寫,名為"Removing Left Recursion from Context-Free Grammars"的改進。
對於每個規則如下:
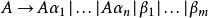 左遞歸
左遞歸注意這裡:
A 是一個有左遞歸的非終端符號
左遞歸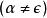 左遞歸
左遞歸是一個終端與非終端符號的序列,而且不為空字串
左遞歸是一個不以A開頭的,以終端與非終端符號組成的序列)
將A的規則改成以下規則:
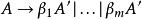 左遞歸
左遞歸然後對新創造出來非終端符號的規則
 左遞歸
左遞歸這個新創造出來的符號常被稱為"尾巴"(tail),或者"rest"(剩餘)
舉例,考慮以下規則
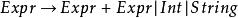 左遞歸
左遞歸我們可以改寫為
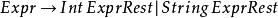 左遞歸
左遞歸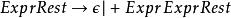 左遞歸
左遞歸然後最後一個規則可以縮短改寫為
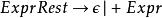 左遞歸
左遞歸來避免掉左遞歸的出現
移除間接左遞歸
 左遞歸
左遞歸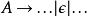 左遞歸
左遞歸 左遞歸
左遞歸如果文法內不存在 (代表空字串)的生成 (不存在 這樣的規則),而且不是循環(cyclic)的文法(對所有非終端符號A,不存在像是 這種形式的規則),以下這個一般化的算法可以用來去除文法的間接左遞歸:
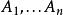 左遞歸
左遞歸將所有非終端符號以某個固定的順序 排列。
從 i = 1 到 n {
從 j = 1 到 i – 1 {
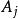 左遞歸
左遞歸設 的生成規則為
 左遞歸
左遞歸 左遞歸
左遞歸將所有規則 換成
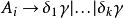 左遞歸
左遞歸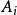 左遞歸
左遞歸移除 規則中的直接左遞歸。
}
}
陷阱
上面的轉換使用右遞歸的文法來避免掉左遞歸的出現;但是這樣會改變規則的結合律。左遞歸會創造出向左的結合律;但是右遞歸則會創造出向右的結合律。
範例:
一開始我們拿到以下文法:
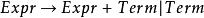 左遞歸
左遞歸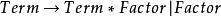 左遞歸
左遞歸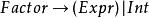 左遞歸
左遞歸在我們使用上面的轉換方式來移除掉左遞歸之後,我們取得了以下文法:
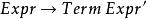 左遞歸
左遞歸 左遞歸
左遞歸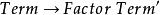 左遞歸
左遞歸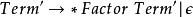 左遞歸 左遞歸
左遞歸 左遞歸我們將字串 'a + a + a'用一個LALR分析器(這種分析器可以處理左遞歸的文法)使用原先的文法來分析,會得到下面的分析樹(parse tree):
整個分析樹是往左邊長,代表在這裡的規則,'+'這個符號是左結合(left associative)的,或者說這規則代表(a + a) + a。
但是我們改變了文法之後,那這個分析樹會變成 :
 左遞歸
左遞歸整個分析樹是往左邊長,代表在這裡的規則,'+'這個符號是左結合(left associative)的,或者說這規則代表(a + a) + a。
但是我們改變了文法之後,那這個分析樹會變成:
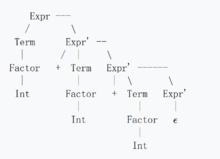 左遞歸
左遞歸我們可以看出這棵樹現在是往右邊成長,意思上代表了a + ( a + a)。我們將'+'的結合律改變了, 變成是右結合的規則。 在處理加法的文法時這不是什麼問題,但是如果我們現在處理的是減法,這就會變成是很嚴重的問題。
問題的關鍵在於有很多常用的算術規則要求左結合的規則。我們有幾種解決辦法: (a) 將規則重新改為左遞歸,(b) 使用更多的非終端符號來改寫規則,以強迫文法合乎正確的結合(c) 如果使用YACC或者Bison,他們有所謂算符宣告(operator declarations),%left,%right and%nonassoc,這一些算符可以告訴語法分析器產生程式(parser generator)應該遵從哪一種結合。
