引言
利用歷史數據中的有用信息來幫助分析未來數據的機器學習,通常需要大量有標籤數據才能訓練出一個優良的學習器。深度學習模型是一種典型的機器學習模型,因為這類模型是帶有很多隱藏層和很多參數的神經網路,所以通常需要數以百萬計的數據樣本才能學習得到準確的參數。但是,包括醫學圖像分析在內的一些套用無法滿足這種數據要求,因為標註數據需要很多人力勞動。在這些情況下,多任務學習(MTL)可以通過使用來自其它相關學習任務的有用信息來幫助緩解這種數據稀疏問題。
MTL 是機器學習中一個很有前景的領域,其目標是利用多個學習任務中所包含的有用信息來幫助為每個任務學習得到更為準確的學習器。我們假設所有任務(至少其中一部分任務)是相關的,在此基礎上,我們在實驗和理論上都發現,聯合學習多個任務能比單獨學習它們得到更好的性能。根據任務的性質,MTL 可以被分類成多種設定,主要包括多任務監督學習、多任務無監督學習、多任務半監督學習、多任務主動學習、多任務強化學習、多任務線上學習和多任務多視角學習。
多任務監督學習任務(可能是分類或回歸問題)是根據訓練數據集(包含訓練數據實例和它們的標籤)預測未曾見過的數據的標籤。多任務無監督學習任務(可能是聚類問題)是識別僅由數據構成的訓練數據集中的有用模式。多任務半監督學習任務與多任務監督學習類似,只是其訓練集中不僅包含有標籤數據,也包含無標籤數據。多任務主動學習任務是利用無標籤數據來幫助學習有標籤數據,這類似於多任務半監督學習,其差異在於主動學習會選擇無標籤數據來主動查詢它們的標籤從而降低標註開銷。多任務強化學習任務是選擇動作以最大化累積獎勵。多任務線上學習任務是處理序列數據。多任務多視角學習任務是處理多視角數據——其中每個數據實例都有多組特徵。
MTL 可以看作是讓機器模仿人類學習行為的一種方法,因為人類常常將一個任務的知識遷移到另一個相關的任務上。例如,根據作者自身經驗,打壁球和打網球的技能可以互相幫助提升。與人類學習類似,(機器)同時學習多個學習任務是很有用的,因為一個任務可以利用另一個相關任務的知識。
MTL 也與機器學習的某些其它領域有關,包括遷移學習、多標籤學習和多輸出回歸,但 MTL 也有自己不同的特點。比如說,類似於 MTL,遷移學習的目標也是將知識從一個任務遷移到另一個任務,但不同之處在於遷移學習希望使用一個或多個任務來幫助另一個目標任務,而 MTL 則是希望多個任務彼此助益。當多任務監督學習的不同任務使用了同樣的訓練數據時,這就變成了多標籤學習或多輸出回歸。從這個意義上看,MTL 可以被看作是多標籤學習和多輸出回歸的一種泛化。
與傳統遷移學習、領域自適應等方法不同,多任務學習是一種並行遷移模式。傳統遷移學習強調學習的先後順序,即將在一個領域學到的知識遷移到另一個領域,知識遷移的過程是串列進行。而在多任務學習中,任務之間的信息相互共享,知識在不同的任務中互相遷移,因此多任務學習也被叫做並行遷移學習。多任務學習方法通過多任務信息共享提升整體的學習效果,這對於小樣本上的學習尤其有效。假設有大量的小樣本學習任務,多任務學習方法可以充分利用多個小樣本的信息,提升多任務整體的學習效果。
提出動機
提出多任務學習的出發點是多種多樣的:
(1)從生物學來看,我們將多任務學習視為對人類學習的一種模擬。為了學習一個新的任務,我們通常會使用學習相關任務中所獲得的知識。例如,嬰兒先學會識別臉,然後將這種知識用來識別其他物體。
(2)從教學法的角度來看,我們首先學習的任務是那些能夠幫助我們掌握更複雜技術的技能。這一點對於學習武術和編程來講都是非常正確的方法。具一個脫離大眾認知的例子,電影Karate Kid中Miyagi先生教會學空手道的小孩磨光地板以及為汽車打蠟這些表明上沒關係的任務。然而,結果表明正是這些無關緊要的任務使得他具備了學習空手道的相關的技能。
(3)從機器學習的角度來看,我們將多任務學習視為一種歸約遷移(inductive transfer)。歸約遷移(inductive transfer)通過引入歸約偏置(inductive bias)來改進模型,使得模型更傾向於某些假設。舉例來說,常見的一種歸約偏置(Inductive bias)是L1正則化,它使得模型更偏向於那些稀疏的解。在多任務學習場景中,歸約偏置(Inductive bias)是由輔助任務來提供的,這會導致模型更傾向於那些可以同時解釋多個任務的解。
定義
定義 (多任務學習):給定 m 個學習任務,其中所有或一部分任務是相關但並不完全一樣的,多任務學習的目標是通過使用這 m 個任務中包含的知識來幫助提升各個任務的性能。
基於這一定義,我們可以看到 MTL 有兩個基本因素。
第一個因素是任務的相關性。任務的相關性是基於對不同任務關聯方式的理解,這種相關性會被編碼進 MTL 模型的設計中。
第二個因素是任務的定義。在機器學習中,學習任務主要包含分類和回歸等監督學習任務、聚類等無監督學習任務、半監督學習任務、主動學習任務、強化學習任務、線上學習任務和多視角學習任務。因此不同的學習任務對應於不同的 MTL 設定。
多任務監督學習
多任務監督學習(MTSL)意味著 MTL 中的每個任務都是監督學習任務,其建模了從數據到標籤的函式映射。
基於特徵的 MTSL
在這一類別中,所有 MTL 模型都假設不同的任務都具有同樣的特徵表示,這是根據原始特徵學習得到的。根據這種共有的特徵表示的學習方式,我們進一步將多任務模型分為了三種方法,包括特徵變換方法、特徵選擇方法和深度學習方法。特徵變換方法學習到的共有特徵是原始特徵的線性或非線性變換。特徵選擇方法假設共有特徵是原始特徵的一個子集。深度學習方法套用深度神經網路來為多個任務學習共有特徵,該表征會被編碼在深度神經網路的隱藏層中。
基於參數的 MTSL
基於參數的 MTSL 使用模型參數來關聯不同任務的學習。根據不同任務的模型參數的關聯方式,我們可將其分成 5 種方法,包括低秩方法、任務聚類方法、任務關係學習方法、髒方法(dirty approach)和多層次方法。具體而言,因為假設任務是相關的,所以參數矩陣 W 很可能是低秩的,這是低秩方法提出的動機。任務聚類方法的目標是將任務分成多個集群,並假設其中每個集群中的所有任務都具有同樣的或相似的模型參數。任務關係學習方法是直接從數據中學習任務間的關係。髒方法假設參數矩陣 W 可以分解成兩個分量矩陣,其中每個矩陣都由一種稀疏類型進行正則化。多層次方法是髒方法的一種泛化形式,是將參數矩陣分解成兩個以上的分量矩陣,從而建模所有任務之間的複雜關係。
基於實例的 MTSL
這一類別的研究很少,其中 [61] 提出的多任務分布匹配方法是其中的代表。具體來說,它首先評估每個實例來自其自己的任務的機率和來自所有任務的混合的機率之比。在確定了此比率之後,這種方法會利用此比率針對每一個任務來加權所有任務的數據,並利用加權的數據來學習每一個任務的模型參數。
多任務無監督學習
不同於每個數據實例都關聯了一個標籤的多任務監督學習,多任務無監督學習的訓練集僅由數據樣本構成,其目標是挖掘數據集中所包含的信息。典型的無監督學習任務包括聚類、降維、流形學習(manifold learning)和可視化等,而多任務無監督學習主要關注多任務聚類。聚類是指將一個數據集分成多個簇,其中每簇中都有相似的實例,因此多任務聚類的目的是通過利用不同數據集中包含的有用信息來在多個數據集上同時執行聚類。
多任務半監督學習
在很多套用中,數據通常都需要很多人力來進行標註,這使得有標籤數據並不很充足;而在很多情況下,無標籤數據則非常豐富。所以在這種情況下,可以使用無標籤數據來幫助提升監督學習的表現,這就是半監督學習。半監督學習的訓練集由有標籤和無標籤的數據混合構成。在多任務半監督學習中,目標是一樣的,其中無標籤數據被用於提升監督學習的表現,而不同的監督學習任務則共享有用的信息來互相幫助。
多任務主動學習
多任務主動學習的設定和多任務半監督學習幾乎一樣,其中每個任務的訓練集中都有少量有標籤數據和大量無標籤數據。但是不同於多任務半監督學習,在多任務主動學習中,每個任務都會選擇部分無標籤數據來查詢一個 oracle 以主動獲取其標籤。因此,無標籤數據的選擇標準是多任務主動學習領域的主要研究重點。
多任務強化學習
受行為心理學的啟發,強化學習研究的是如何在環境中採取行動以最大化累積獎勵。其在很多套用上都表現出色,在圍棋上擊敗人類的 AlphaGo 就是其中的代表。當環境相似時,不同的強化學習任務可以使用相似的策略來進行決策,因此研究者提出了多任務強化學習。
多任務線上學習
當多個任務的訓練數據以序列的形式出現時,傳統的 MTL 模型無法處理它們,但多任務線上學習則可以做到。
多任務多視角學習
在計算機視覺等一些套用中,每個數據樣本可以使用不同的特徵來描述。以圖像數據為例,其特徵包含 SIFT 和小波(wavelet)等。在這種情況下,一種特徵都被稱為一個視角(view)。多視角學習就是為處理這樣的多視角數據而提出的一種機器學習範式。與監督學習類似,多視角學習中每個數據樣本通常都關聯了一個標籤。多視角學習的目標是利用多個視角中包含的有用信息在監督學習的基礎上進一步提升表現。多任務多視角學習是多視角學習向多任務的擴展,其目標是利用多個多視角學習問題,通過使用相關任務中所包含的有用信息來提升每個多視角學習問題的性能。
多任務學習方法
基於傳統的單任務學習方法,可以設計出對應的多任務學習模型。目前,已有學者提出基於決策樹、線性判別分析(LDA)、支持向量機(SVM)、貝葉斯方法、高斯過程的多任務學習方法。結合集成學習理論,已有學者提出多任務Boosting等方法。
多任務深度學習
參數的硬共享機制
參數的硬共享機制是神經網路的多任務學習中最常見的一種方式 。一般來講,它可以套用到所有任務的所有隱層上,而保留任務相關的輸出層。硬共享機制降低了過擬合的風險。事實上,文獻 證明了這些共享參數過擬合風險的階數是N,其中N為任務的數量,比任務相關參數的過擬合風險要小。直觀來將,這一點是非常有意義的。越多任務同時學習,我們的模型就能捕捉到越多任務的同一個表示,從而導致在我們原始任務上的過擬合風險越小。
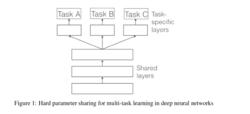 多任務學習
多任務學習參數的軟共享機制
每個任務都由自己的模型,自己的參數。我們對模型參數的距離進行正則化來保障參數的相似。文獻 使用L2距離正則化,而文獻 使用跡正則化(trace norm)。用於深度神經網路中的軟共享機制的約束很大程度上是受傳統多任務學習中正則化技術的影響。
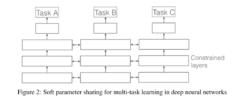 多任務學習
多任務學習MTL有效原因
即使從多任務學習中獲得歸約偏置的解釋很受歡迎,但是為了更好理解多任務學習,我們必須探究其深層的機制。大多數機制早在1998年被Caruana提出。為了便於說明,我們假設有兩個相關的任務A與B,兩者共享隱層表示F。
(1)隱世數據增加機制。
多任務學習有效的增加了訓練實例的數目。由於所有任務都或多或少存在一些噪音,例如,當我們訓練任務A上的模型時,我們的目標在於得到任務A的一個好的表示,而忽略了數據相關的噪音以及泛化性能。由於不同的任務有不同的噪音模式,同時學習到兩個任務可以得到一個更為泛化的表示。如果只學習任務A要承擔對任務A過擬合的風險,然而同時學習任務A與任務B對噪音模式進行平均,可以使得模型獲得更好表示F。
(2)注意力集中機制。
若任務噪音嚴重,數據量小,數據維度高,則對於模型來說區分相關與不相關特徵變得困難。多任務有助於將模型注意力集中在確實有影響的那些特徵上,是因為其他任務可以為特徵的相關與不相關性提供額外的證據。
(3)竊聽機制。對於任務B來說很容易學習到某些特徵G,而這些特徵對於任務A來說很難學到。這可能是因為任務A與特徵G的互動方式更複雜,或者因為其他特徵阻礙了特徵G的學習。通過多任務學習,我們可以允許模型竊聽(eavesdrop),即使用任務B來學習特徵G。最簡單的實現方式是使用hints ,即訓練模型來直接預測哪些是最重要的特徵。
(4)表示偏置機制。
多任務學習更傾向於學習到一類模型,這類模型更強調與其他任務也強調的那部分表示。由於一個對足夠多的訓練任務都表現很好的假設空間,對來自於同一環境的新任務也會表現很好,所以這樣有助於模型展示出對新任務的泛化能力 。
(5)正則化機制。
多任務學習通過引入歸納偏置(inductive bias)起到與正則化相同的作用。正是如此,它減小了模型過擬合的風險,同時降低了模型的Rademacher複雜度,即擬合隨機噪音的能力。
MTL共享內容
大多數的多任務學習中,任務都是來自於同一個分布的。儘管這種場景對於共享是有益的,但並不總能成立。為了研發更健壯的多任務模型,我們必須處理那些不相關的任務。
早期用於深度學習的多任務模型需要預定義任務間的共享結構。這種策略不適合擴展,嚴重依賴於多任務的結構。早在1997年就已經提出的參數的硬共享技術在20年後仍舊是主流。儘管參數的硬共享機制在許多場景中有用,但是若任務間的聯繫不那么緊密,或需要多層次的推理,則硬共享技術很快失效。最近也有一些工作研究學習哪些可以共享,這些工作的性能從一般意義上將優於硬共享機制。此外,若模型已知,學習一個任務層次結構的容量也是有用的,尤其是在有多粒度的場景中。
一旦我們要做一個多目標的最佳化問題,那么我們就是在做多任務學習。多任務不應僅僅局限於將所有任務的知識都局限於表示為同一個參數空間,而是更加關注於如何使我們的模型學習到任務間本應該的互動模式。
