
分段存儲管理方式的引入
引入分段存儲管理方式,主要是為了滿足用戶和程式設計師的下述一系列需要:
1) 方便編程
通常,用戶把自己的作業按照邏輯關係劃分為若干個段,每個段都是從0開始編址,並有自己的名字和長度。因此,希望要訪問的邏輯地址是由段名(段號)和段內偏移量(段內地址)決定的。例如,下述的兩條指令便是使用段名和段內地址:
LOAD 1,[A] |〈D〉;
STORE 1,[B] |〈C〉;
其中,前一條指令的含義是將分段A中D單元內的值讀入暫存器1;後一條指令的含義是將暫存器1的內容存入B分段的C單元中。
2) 信息共享
在實現對程式和數據的共享時,是以信息的邏輯單位為基礎的。比如,共享某個例程和函式。分頁系統中的“頁”只是存放信息的物理單位(塊),並無完整的意義,不便於實現共享;然而段卻是信息的邏輯單位。由此可知,為了實現段的共享,希望存儲管理能與用戶程式分段的組織方式相適應。
3) 信息保護
信息保護同樣是對信息的邏輯單位進行保護,因此,分段管理方式能更有效和方便地實現信息保護功能。
4) 動態增長
在實際套用中,往往有些段,特別是數據段,在使用過程中會不斷地增長,而事先又無法確切地知道數據段會增長到多大。前述的其它幾種存儲管理方式,都難以應付這種動態增長的情況,而分段存儲管理方式卻能較好地解決這一問題。
5) 動態連結
動態連結是指在作業運行之前,並不把幾個目標程式段連結起來。要運行時,先將主程式所對應的目標程式裝入記憶體並啟動運行,當運行過程中又需要調用某段時,才將該段(目標程式)調入記憶體並進行連結。可見,動態連結也要求以段作為管理的單位。
分段系統的基本原理
分段
在分段存儲管理方式中,作業的地址空間被劃分為若干個段,每個段定義了一組邏輯信息。例如,有主程式段MAIN、子程式段X、數據段D及棧段S等,如圖4-17所示。每個段都有自己的名字。為了實現簡單起見,通常可用一個段號來代替段名,每個段都從0開始編址,並採用一段連續的地址空間。段的長度由相應的邏輯信息組的長度決定,因而各段長度不等。整個作業的地址空間由於是分成多個段,因而是二維的,亦即,其邏輯地址由段號(段名)和段內地址所組成。
 基本分段存儲管理方式
基本分段存儲管理方式分段地址中的地址具有如下結構:
在該地址結構中,允許一個作業最長有 64 K個段,每個段的最大長度為64 KB。 分段方式已得到許多編譯程式的支持,編譯程式能自動地根據源程式的情況而產生若干個段。例如,Pascal編譯程式可以為全局變數、用於存儲相應參數及返回地址的過程調用棧、每個過程或函式的代碼部分、每個過程或函式的局部變數等等,分別建立各自的段。類似地,Fortran編譯程式可以為公共塊(Common block)建立單獨的段,也可以為數組分配一個單獨的段。裝入程式將裝入所有這些段,並為每個段賦予一個段號。
段表
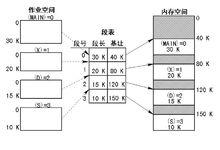 利用段表實現地址映射
利用段表實現地址映射在前面所介紹的動態分區分配方式中,系統為整個進程分配一個連續的記憶體空間。而在分段式存儲管理系統中,則是為每個分段分配一個連續的分區,而進程中的各個段可以離散地移入記憶體中不同的分區中。為使程式能正常運行,亦即,能從物理記憶體中找出每個邏輯段所對應的位置,應像分頁系統那樣,在系統中為每個進程建立一張段映射表,簡稱“段表”。每個段在表中占有一個表項,其中記錄了該段在記憶體中的起始地址(又稱為“基址”)和段的長度,如右圖所示。段表可以存放在一組暫存器中,這樣有利於提高地址轉換速度,但更常見的是將段表放在記憶體中。
地址變換機構
為了實現從進程的邏輯地址到物理地址的變換功能,在系統中設定了段表暫存器,用於存放段表始址和段表長度TL。在進行地址變換時,系統將邏輯地址中的段號與段表長度TL進行比較。若S>TL,表示段號太大,是訪問越界,於是產生越界中斷信號;若未越界,則根據段表的始址和該段的段號,計算出該段對應段表項的位置,從中讀出該段在記憶體的起始地址,然後,再檢查段內地址d是否超過該段的段長SL。若超過,即d>SL,同樣發出越界中斷信號;若未越界,則將該段的基址d與段內地址相加,即可得到要訪問的記憶體物理地址。
下圖示出了分段系統的地址變換過程。
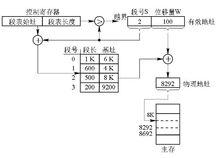 基本分段存儲管理方式
基本分段存儲管理方式像分頁系統一樣,當段表放在記憶體中時,每要訪問一個數據,都須訪問兩次記憶體,從而極大地降低了計算機的速率。解決的方法也和分頁系統類似,再增設一個聯想存儲器,用於保存最近常用的段表項。由於一般情況是段比頁大,因而段表項的數目比頁表項的數目少,其所需的聯想存儲器也相對較小,便可以顯著地減少存取數據的時間,比起沒有地址變換的常規存儲器的存取速度來僅慢約10%~15%。
信息共享
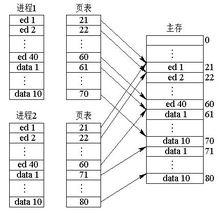
分段系統的一個突出優點,是易於實現段的共享,即允許若干個進程共享一個或多個分段,且對段的保護也十分簡單易行。在分頁系統中,雖然也能實現程式和數據的共享,但遠不如分段系統來得方便。我們通過一個例子來說明這個問題。例如,有一個多用戶系統,可同時接納40個用戶,他們都執行一個文本編輯程式(Text Editor)。如果文本編輯程式有160 KB的代碼和另外40 KB的數據區,則總共需有 8 MB的記憶體空間來支持40個用戶。如果160 KB的代碼是可重入的(Reentrant),則無論是在分頁系統還是在分段系統中,該代碼都能被共享,在記憶體中只需保留一份文本編輯程式的副本,此時所需的記憶體空間僅為1760 KB(40×40+160),而不是8000 KB。
假定每個頁面的大小為4 KB,那么,160 KB的代碼將占用40個頁面,數據區占10個頁面。為實現代碼的共享,應在每個進程的頁表中都建立40個頁表項,它們的物理塊號都是21#~60#。在每個進程的頁表中,還須為自己的數據區建立頁表項,它們的物理塊號分別是61#~70#、71#~80#、81#~90#,…,等等。下圖是分頁系統中共享editor的示意。
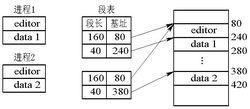
 基本分段存儲管理方式
基本分段存儲管理方式在分段系統中,實現共享則容易得多,只需在每個進程的段表中為文本編輯程式設定一個段表項。下圖是分段系統中共享editor的示意圖。
 基本分段存儲管理方式
基本分段存儲管理方式可重入代碼(Reentrant Code)又稱為“純代碼”(Pure Code),是一種允許多個進程同時訪問的代碼。為使各個進程所執行的代碼完全相同,絕對不允許可重入代碼在執行中有任何改變。因此,可重入代碼是一種不允許任何進程對它進行修改的代碼。但事實上,大多數代碼在執行時都可能有些改變,例如,用於控制程式執行次數的變數以及指針、信號量及數組等。為此,在每個進程中,都必須配以局部數據區,把在執行中可能改變的部分拷貝到該數據區,這樣,程式在執行時,只需對該數據區(屬於該進程私有)中的內容進行修改,並不去改變共享的代碼,這時的可共享代碼即成為可重入碼。
